
字符编码之GB2312
16 / 0 / 创建于 1年前 /
 公众号:自在牛马 的个人博客
公众号:自在牛马 的个人博客
之前我们已经简单介绍过字符集和字符编码,今天我们接着来讲下简体中文常用的字符编码 GB2312。
简介
GB2312 或 GB2312-80 是中华人民共和国国家标准简体中文字符集,全称《信息交换用汉字编码字符集·基本集》,又称 GB0,由中国国家标准总局于 1980 年发布,1981年5月1日实施。GB2312 编码通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持 GB2312。
GB2312 标准共收录 6763 个汉字,其中一级汉字 3755 个,二级汉字 3008 个;同时,GB2312 收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的 682 个全角字符。
GB2312 的出现,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆 99.75% 的使用频率。
但对于人名、古汉语等方面出现的罕用字,GB2312 不能处理,这也导致了后来 GBK 及 GB18030 汉字字符集的出现。
分区表示
GB2312 中对所收汉字进行了“分区”处理,每区含有 94 个汉字/符号,共计 94 个区。实际上,GB2312 只使用了 87 个区。
下列是 GB2312 分区后在区段内储存的字符:
- 01~09区(682个):特殊符号、数字、英文字符、制表符等,包括拉丁字母、希腊字母、日文平假名及片假名字母、注音符号、俄语西里尔字母等在内的 682 个全角字符;
- 10~15区:空区,留待扩展;在附录3,第10区推荐作为 GB 1988-80 中的94个图形字符区域(即第3区字符之半形版本)。
- 16~55区(3755个):常用汉字(也称一级汉字),按拼音排序;
- 56~87区(3008个):非常用汉字(也称二级汉字),按部首/笔画排序;
- 88~94区:空区,留待扩展。
字节结构
在 GB2312 中,每个汉字及符号的码位使用两个字节来表示。第一个字节称为“高位字节”,对应分区的编号;第二个字节称为“低位字节”,对应区段内的码位。
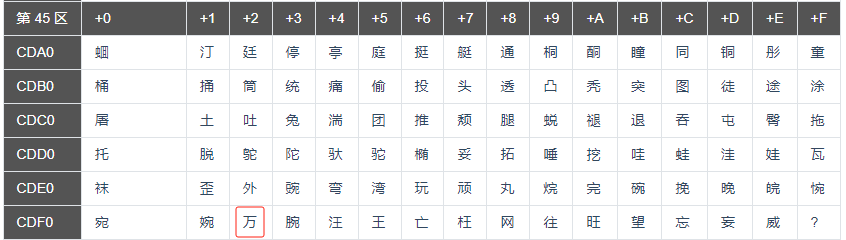
这种用字符所在的区号和码位来表示字符的方法称为区位码。例如“万”字在 GB2312 字符集的 45 区 82 位,所以“万”字的区位码是 45-82(45是“区码”,82是“位码”)。
为了能够向后兼容 ASCII 编码,在存储进电脑时,还需要再次进行转码,即在区位码的基础上加上特定数字。
编码方式
下面我们就简单看下 GB2312 常见的两种表示方式。
- ISO 2022-CN(国标码、交换码)
为了避开 ASCII 字符中的不可显示字符(十六进制为 0×00 至 0×1F,十进制为 0 至 31)及空格字符(十六进制为 0×20,十进制为 32),国标码参考 ISO 2022 规定在进行码位转换时,须将“区码”和“位码”分别加上32(十六进制为 0×20)作为国标码。
在 ISO 2022-CN 内,高位字节使用了 0x21-0x77(把 01-87 区的区号加 32 或 0×20),低位字节使用了 0x21-0x7E(把 01-94 加上 32 或 0×20)。
例:汉字“万”的区位码是 45-82,它的 ISO 2022 码十进制是:(45+32,82+32)=(77,114),十六进制是:(4D,72)。
国标码是汉字信息交换的标准编码,但因其前后字节的最高位为 0,与 ASCII 码冲突,如“保”字,国标码为 0x31 和 0x23,而西文字符“1”和“#”的 ASCII 也为 0x31 和 0x23,假如内存中有两个字节为 0x31 和 0x23,我们根本不知道这到底是一个汉字?还是两个西文字符“1”和“#”?可见,国标码是不能在计算机内部直接使用的。
- EUC-CN(机内码、内码)
因为国标码和通用的 ASCII 码冲突,因此后续为了方便辨认单字节和双字节的编码,部分厂商在 ISO 2022 的基础上把双字节字符的二进制最高位都从 0 换成 1,即相当于把 ISO 2022 的每个字节都再加上128(十六进制为0×80)得到“机内码”表示,简称“内码”。把“区码”和“位码”分别加上160(十六进制为0×A0)也可以得到相同的机内码表示,这种格式也就是 EUC。
EUC-CN 是 GB2312 最常用的表示方法。浏览器编码表上的“GB2312”,通常都是指“EUC-CN”表示法。
在 EUC-CN 中,高位字节使用了 0xA1-0xF7(把 01-87 区的区号加 160 或 0×A0),低位字节使用了 0xA1-0xFE(把 01-94 加上 160 或 0×A0)。
例:汉字“万”的区位码是 45-82,它的 EUC 码十进制是:(45+160,82+160)=(205,242),十六进制是:(CD,F2)。
下面我们通过一张图片来更直观的展示下这两种表示方式:

讲到这里,我们已经大概知道 GB2312 是怎么进行字符编码了。但是这里我还有个疑问,那就是机内码为什么是加 160?如果只是为了向后兼容 ASCII 编码,直接加 128 不就好了吗?这里我们就不得不说说 ISO/IEC 2022 了。
ISO/IEC 2022
ISO/IEC 2022,由国际标准化组织(ISO)及国际电工委员会(IEC)联合制定,是一个使用7位编码表示汉语文字、日语文字或朝鲜文字的方法。
ISO 2022 用于兼容当时的 7 比特宽的通信协议/通信设备。对于 7 比特宽的编码空间,0x00-0x1F 保留给控制字符,0x20-0x7F 用来表示图形字符(printing/“graphic” characters)。因此,在 1 个 7 比特的字符编码空间,图形字符总计为 94 个(由于空格符占用了 0x20 码位、Del符占用了 0x7F 码位)或者 96 个。对于双字节的 7 比特编码空间,图形字符可以有 94 x 94 即 8836 个。
ISO 2022 规定字符集的控制字符可分为两块:C0,C1; 打印(图形)字符分为四块:G0,G1,G2,G3。对于 7 比特编码,字节值 0x00-0x1F 保留给 C0 控制字符块;字节值 0x20-0x7F 用于 G0, G1, G2, G3 字符块。对于单字节编码的字符集,1 个打印(图形)字符块可包含 94 个或 96 个字符;对于双字节编码的字符集,1 个打印(图形)字符块可包含 94 x 94 个字符。使用控制符的转义序列来表示在 G0,G1,G2,G3 之间的切换。
对于遵从 ISO 2022 的 8 比特编码字符集(比如我们本文介绍的 GB2312 就是 8 比特双字节编码),也是按照上述 7 比特编码原则设计的编码方案。这种 8 比特编码字符集很容易兼容当时的 7 比特宽的通信协议/通信设备。8 比特字符编码时,0x00-0x1F 表示 C0 或称 CL 区(L 是 left 缩写,因为其在字符表的左侧),0x80-0x9F 表示 C1 或称 CR(R 是 Right 缩写,因为其在字符表的右侧)。0x20-0x7F 表示 G0(称 GL 区),0xA0-0xFF(称 GR 区)可表示 G1, G2, G3。
GB2312 中字节值在 0x00-0x7F,为单字节表示一个字符,构成了 C0、G0 区,与 ASCII 码兼容;使用 16-55 区编码一级汉字,56-87 区编码二级汉字,这些汉字均放在了 G1 字符块。因此,GB 2312是单、双字节混合编码。
ISO-8859-X 字符集是特定的把 ISO-2022 的若干成分组合起来的字符集。这些成分包括:
- 低端控制字符(C0)
- US-ASCII 字符集(G0)
- 高端控制字符(C1)
- 高端字符(GR)是特定于每个 ISO-8859-X 变种。例如 ISO-8859-1 是由ISO-IR-1, ISO-IR-6, ISO-IR-77, ISO-IR-100 组成。
低端控制字符(C0):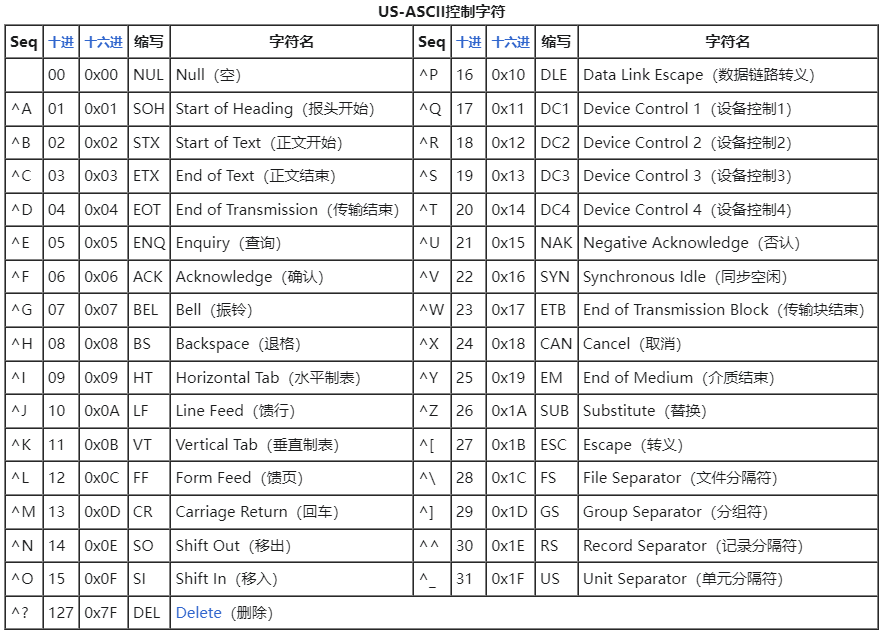
高端控制字符(C1):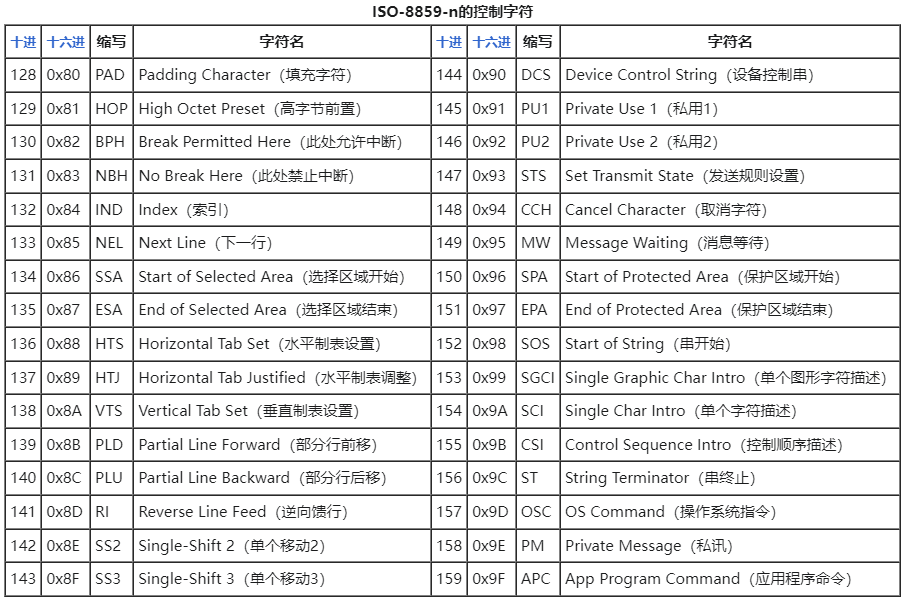
看到这里,我们也就能明白为什么机内码是在区位码的基础上加 160 了,因为 C0 与 C1 是 ISO/IEC 2022 定义的控制字符集,0x00-0x7F 构成了 C0、G0 区,0x80-0x9F 构成了 C1 区,所以区位码加 160(0xA0)是为了更好的向后兼容。
参考
写在最后
如果本文对您有所帮助或者有所启发,请帮忙扫描下方二维码或微信搜索 「自在牛马」 关注一下我的公众号,您的支持是我最大的写作动力。感谢~
拒绝白嫖,转载请注明出处。

本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu



