
为了与BUG死磕,用AI做了些工具
136 / 4 / 创建于 10个月前
 cg33 的个人博客
cg33 的个人博客
事情是这样的,作为一个golang后端开发,目前在一家互联网小厂养老,一到6点撒腿就跑。但是,老是有些BUG拖后腿,阻碍我下班的步伐。因此,我就想开始思考怎样能提高修BUG的效率。本文分享一下我为此做的一些工程化实践以及展望。
- 0x01 背景介绍(可略过)
- 0x02 痛点一:收集足够多信息定位
- 0x03 痛点二:部分编译,提高效率
- 0x04 AI自动修BUG?
0x01 耗时耗哪儿
要提升效率,先要确定到底是哪个步骤耗时。修BUG无非三步,第一步定位,第二步修复,第三步验证。第一步前面往往还需要第零步,就是重现。但有的BUG重现不了,这种属于比较高级别的BUG了。
相比于修复验证,耗时的大头是定位。
怎么定位,以我们组的方式就是看日志与监控,然后人工分析代码。但日志往往不太够用。因为写代码的时候不爱加日志,且也不鼓励加太多日志。不鼓励的原因有二:
第一是不重要日志会冲掉重要的比如ERROR,WARN日志,日志存储量有限;
第二是由于安全规范,日志不能暴露一些隐私信息。
当然这是生产环境的要求,测试环境可以随便加,但是不会在一开始开发时候就去加。只有出问题了,无法直接定位需要更多信息了才需要加日志。这时候问题就来了,也是第一个卡顿点。那就是加日志,怎么加,加哪些地方,以及加完之后的部署。为了加一点日志,去触发一次测试环境的部署其实不划算。因为我们的基建相对没那么完善。部署一个服务要经过编译打包镜像等过程,看不同环境,有的环境10分钟起步,有的环境动不动20分钟起步。20分钟都够我回家了。部署的期间还只能干等。
有人会说那本地环境不能测吗。其实本地环境能复现的问题都是极好解决的问题。但现在很少有团队是不用微服务的,不同服务不同版本代码,加上不同环境的数据不同,导致了大部分的BUG都是与环境相关的,只能到特定环境去DEBUG。如果能给不同环境都加上泳道,也能解决本地DEBUG问题,但是我们尚且没有这种基建能力,且也不太能在统一环境去这样搞。
这是第一个痛点,定位问题缺少足够的信息以及部署耗时的困扰。
假设我们定位了问题,接着要做的就是修复。修复同样的也要面临一个问题,我只是修复一小块代码,可能只是几行IF/ELSE,但是我却要编译整个项目,因为我们用的静态编译语言。这个跟加几行日志的困扰却要部署整个项目是一个样的。在我们的部署流程里面还有打镜像等环节,简直是准下班打工人的噩梦。更崩溃的问题是,当你部署完之后,发现少写或写错了一点逻辑,那么则又要来一次部署。此时,相信各位gopher都要开始怀念起php吧。
此之谓第二痛点,修复难以一步到位。
围绕这两点,我开始了一些实践。
0x02 SimpleTrace
DEBUG的终极手段就是打断点,但是在测试环境去给一个后端GO程序打断点,在实施起来会遇到一些问题:
第一,golang需要编译时保留符号表和调试信息,需要修改编译方式,编译后产物也会相应增大;
第二,需要在环境维护多一个dlv程序,并且打开相关端口监听;
第三,需要使用条件断点,不能阻塞非BUG请求执行,因为环境大概率不止你一个人在用,如果阻塞了别的请求导致失败,这时候估计别人会骂街,显然不行,条件断点也有比较多限制;
实时DEBUG固然很好,也并非不能实现,但是会导致维护更困难,性能下降,为了偶尔的环境业务BUG去做似乎不太划得来。
当然了,另一个更好的思路是使用泳道,把指定的请求转到你本地环境进行DEBUG。在测试环境启用泳道到本地开发环境有一些难点和弊端,一方面是不同环境部署方式不统一,另一个方面,让大家都能侵入到环境DEBUG,也会影响测试环境的稳定性。
最后,只剩下一种属于脏活累活的手段了,就是侵入式的获取日志。
每次手打日志前面提到了,不划算也不彻底。于是我使用AI辅助做了一个Trace工具:SimpleTrace。这个工具能把调用链路上的函数的入参出参都记录起来并用很友好的方式展示。这时候需要的信息基本上都会满足,99%的情况都不需要再去加日志了。
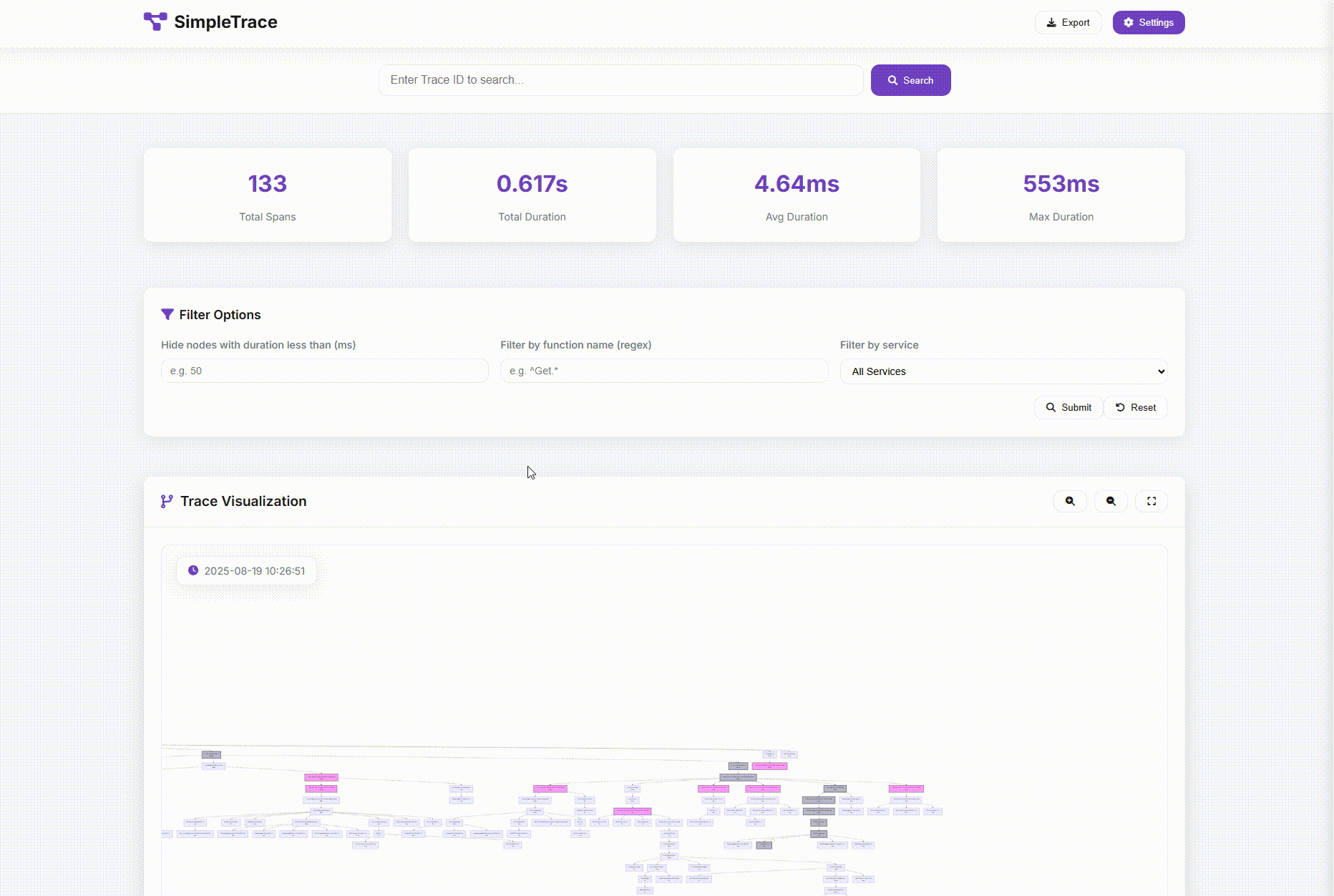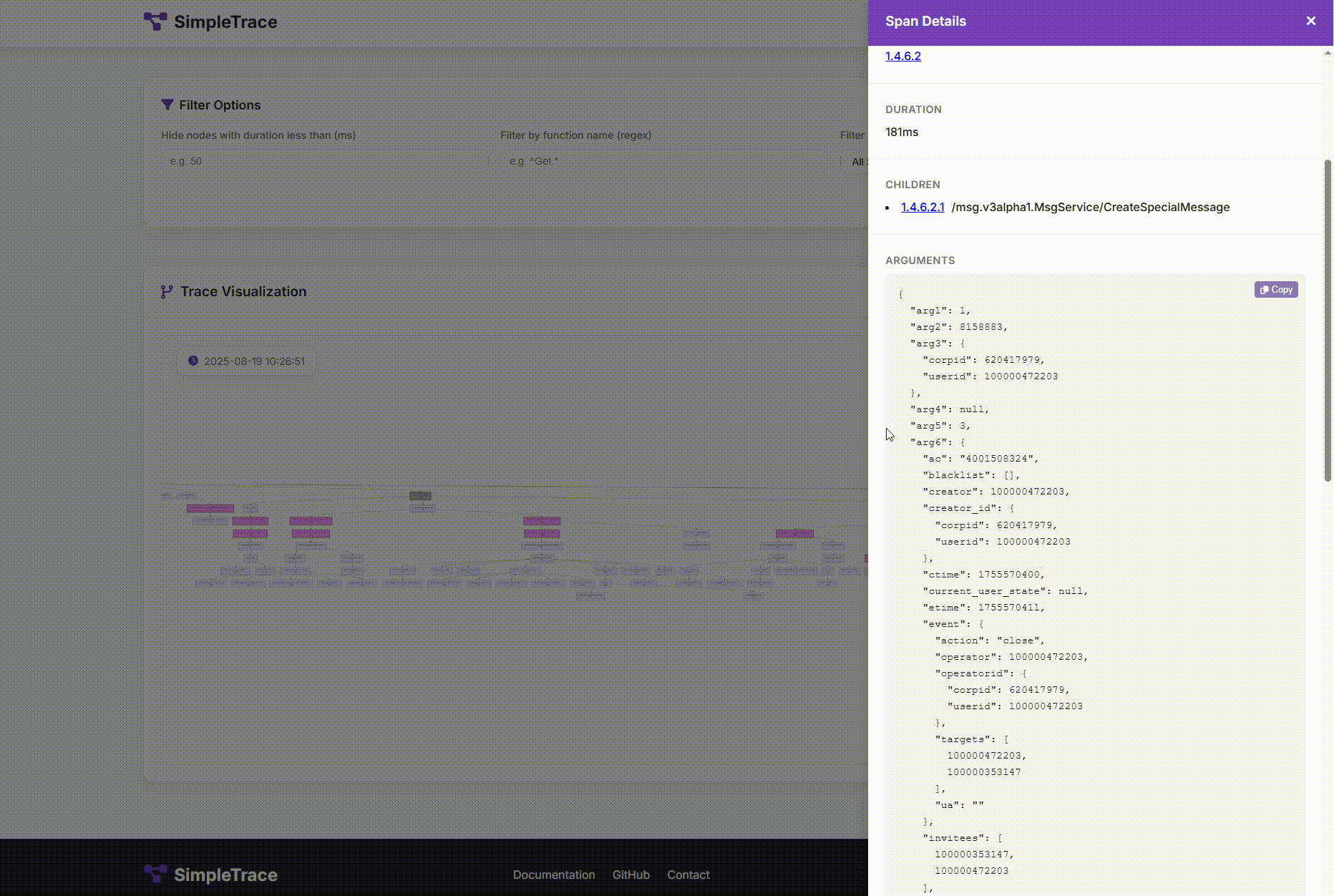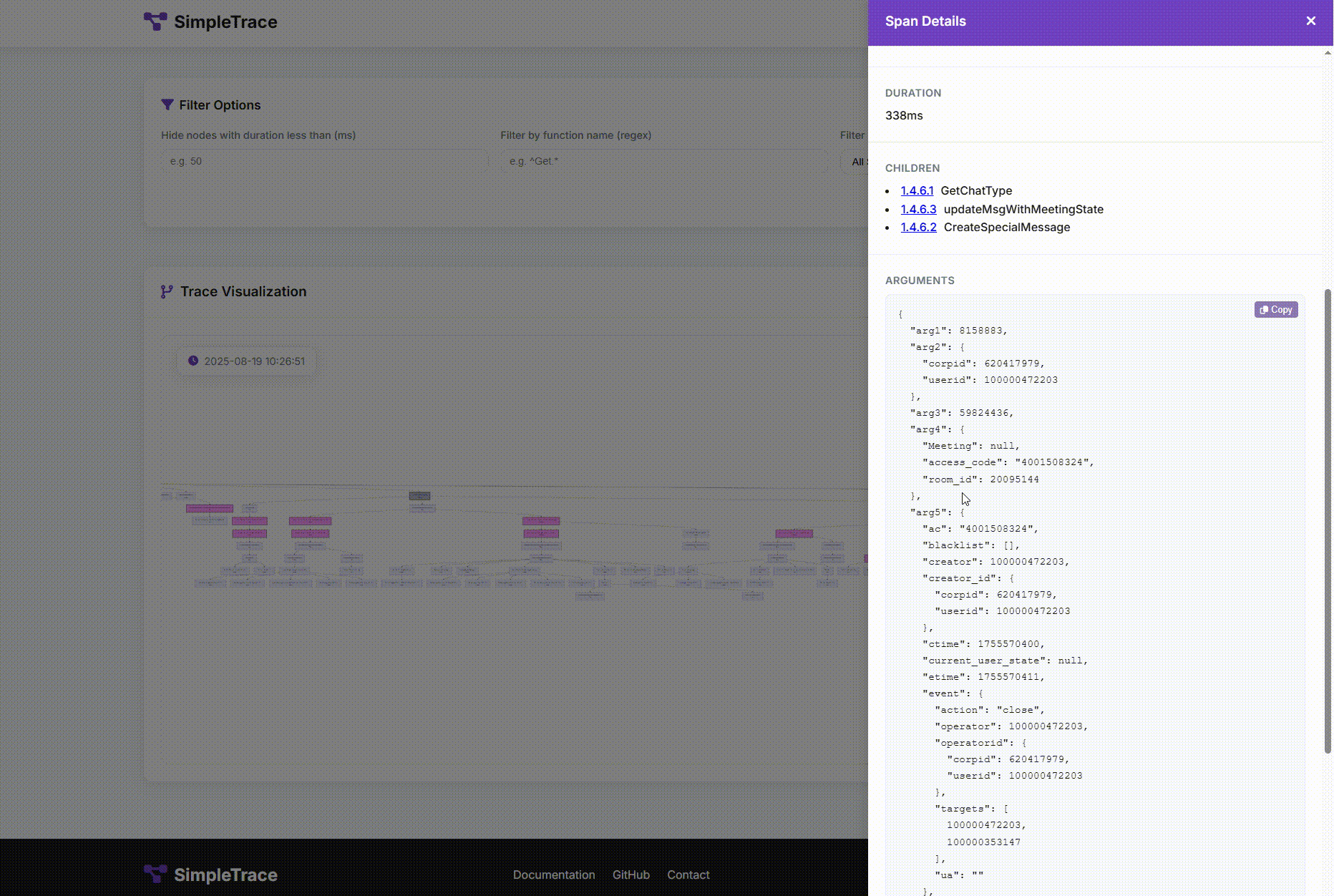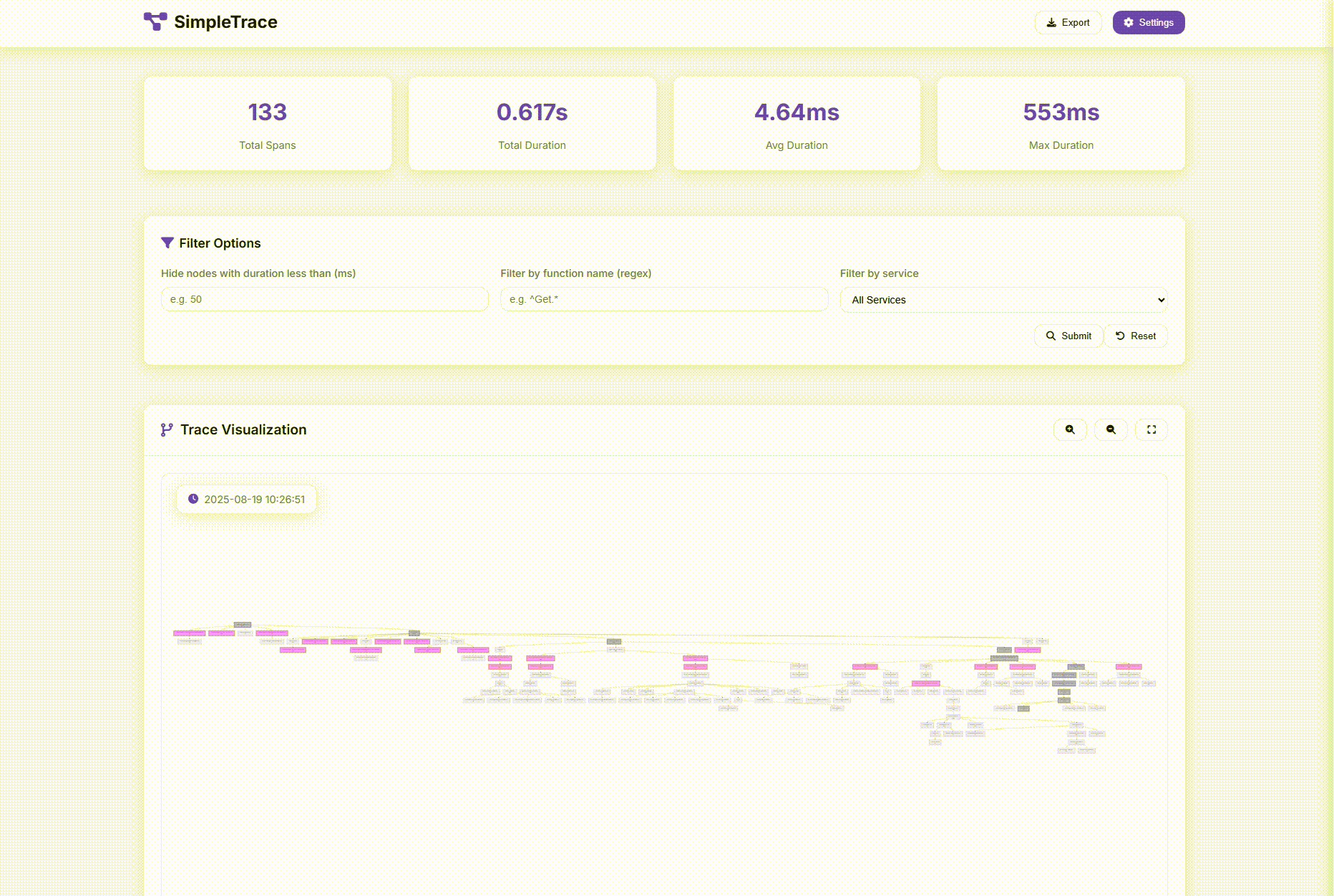
虽然决定了要侵入业务代码,但是也要竭尽能力地优雅地轻量去侵入。
userService.GetUser(ctx, userID)
对于上面这样一个函数调用,simpletrace对其进行抓取的方式十分简单。
simpletrace.Trace(userService.GetUser)(ctx, userID)
这样就能收集到函数的各种信息:
- 函数名
- 函数位置
- 入参
- 出参
- 执行耗时
这是利用golang的反射能力做到,本质就是使用反射重新构建了一个函数Wrapper,然后捕获外部的入参以及出参。
但是即便如此,要对函数链路上的每个函数都加上,也十分地dirty,耗时耗力。因此必须有另外的方案来解决。目前折中的方案就是代码生成。还是上面的例子。
type UserService struct {...}
func (us *UserService) GetUser(ctx context.Context, userID int64) *User {...}
针对这个结构体对象,我们可以使用代码生成工具对其所有的方法都加上Trace。我做了个工具:tracegen。可以指定结构体,生成其对应的trace包装的结构体。
type TraceUserService struct {
s *UserService
}
func (us *UserService) Trace() *TraceUserService {
return &TraceUserService{us}
}
func (us *TraceUserService) GetUser(ctx context.Context, userID int64) *User {
return simpletrace.Trace(us.s.GetUser)(ctx, userID)
}
这样子一来,针对结构体的方法就也不用手动去加了,使用生成的方法即可全部加上。在赋值时,把结构体换一下即可。这已经是目前能想到的最不侵入原业务代码的方式了,因为golang没法实现对结构体的替换,因此如果是定义为interface的则可以直接更换为trace实现,还是相当丝滑,但不是interface,则要么还是更换为interface定义,要么就得手动更改为trace实现。
关于trace怎么采样,怎么保存就十分常规略过了。
总体而言,能拿到整个调用链信息,DEBUG的时候基本就能更得心应手的定位了。
0x03 Pluginable
现在看第二个痛点,修复问题无法一步到位,全量编译耗时太长。
如果你觉得上面做一个trace工具还比较普通,那这个痛点的解决就不太普通了。golang确实提供了一种方式可以只编译部分逻辑代码,而不用编译整个项目。就是备受吐槽的golang plugin,相信很多人都没用过,因为实在难用。其设计的初衷和目的也都不是为了热更新,这使得他在热更新这个场景有很多问题。包括但不限于:
- 加载so时runtime各种一致性检查
- go version、 gopath、dependency…
- 加载后不再可卸载
- 有Load方法却不能unload
这些问题导致这个功能很难用在生产环境,很难标准化。但对于测试环境,有一线生机,测试环境可以随意整。死马当活马医。
- 既然包依赖版本有限制,那干脆不依赖了,直接通过interface绕过。
- 既然加载后不可卸载,那就把代码进行剪裁,只留下有用的,控制编译产物的大小,大不了就重启一波。
最终的效果就是,实现本地编译部分代码上传然后远程执行,把原本长达几分钟到几十分钟的编译缩短为秒级。这个效果体验比起适配他的缺点来说还是相当有诱惑。
其实业界关于这块也有很多别的尝试,都是在做不同的tradeoff。比如:
- 使用开发go解释器
- 使用rpc模块
- 使用CGO
诚然这些方案会更稳健,更适用于生产环境,也是经过验证的。但是在使用体验上还是不够好,测试开发环境上还是以效率为先。
能在本地直接接管和调用到项目方法变量的体验是无与伦比的。这不仅能帮你在debug阶段可以更好的定位问题,也可以帮你快速尝试修复问题。做过微服务的同学都知道,服务内部以及跨服务各种调用认证鉴权复杂,要想本地构建各种签名很麻烦,但是如果你能在本地就直接调用测试环境函数方法就可以绕过这些认证,因为各种认证判断和限制都已经在运行时程序中解决了,你只要传入对应参数即可。
此外,这个工具还能与上面的simpletrace做绝妙的配合。还记得我们上面在函数链路上打点拿trace信息吗,这时候其实我们完全可以在整条trace链路上的所有方法都打上桩,这意味着我们可以根据trace的入参信息来判断是否由我们的plugin接管当前的链路节点函数。这时候你只需要包装同样的输入输出,即可完成对节点函数的替代,实现修复当前节点函数的目的。
当然这些修复都是临时的,作为调试开发是很高效,但是最终还是得以正式的项目代码来解决。这两者还需要去抹平一些差异。但这个抹平差异的流程是简单且可自动化的。
0x04 未来展望
当前这两个工具项目仍处于非常早期的阶段。而且只是解决了一部分的问题,仍然有一些tradeoff的问题需要去治理。但是这给我打开了很多想象空间。
我开始思考一个问题,AI当前这么火,那能不能替代我们去修BUG。
让AI自己修BUG听起来像科幻片,毕竟人类都读不懂这些诸多大厂先贤们留下的屎山代码,AI能征服且找出其中问题吗。其实还真有希望,毕竟现在大模型连16进制代码都能搞懂。但是现阶段存在一些工程问题,包括但不限于:
- 上下文的限制
- 幻觉
但工程问题是可以通过各种dirty work来搞定的。比如,上下文的问题通过上下文工程解决,幻觉的问题通过调试prompt,重试,使用更适配的大模型等手段来优化。
加上现在通过agent的方式,我们可以使用多轮的对话,来把人与大模型与知识库的之间的交互从而提供更好的上下文来提高修复问题的准确率。
当前这还得依赖我前面工具的一些能力,比如使用静态分析加线上的动态trace信息采集,提供给大模型更好的噪音更小的上下文信息,从而不断深搜缩小问题范围直到确认定位。
更多交流,欢迎加v:chenhg33
本作品采用《CC 协议》,转载必须注明作者和本文链接







 关于 LearnKu
关于 LearnKu




推荐文章: