
 每天一篇CV paper
每天一篇CV paperAlexNet:ImageNet Classification with Deep Convolutional Neural Networks
卷积神经网络
卷积神经网络由一个或多个卷积层、池化层以及全连接层等组成。
其中包含了几个主要结构:
- 卷积层(Convolutions):提取输入的不同特征
- 池化层(Subsampling):对卷积层学习到的特征图进行亚采样处理,减少特征数量
- 全连接层(Full connection):模型任务(分类、回归)
欠拟合和过拟合
过拟合:在训练数据上能够获得比其他假设更好的拟合, 但是在测试数据集上却不能很好地拟合数据(模型过于复杂)
训练很好,测试完蛋
欠拟合:在训练数据上不能获得更好的拟合,并且在测试数据集上也不能很好地拟合数据(模型过于简单)
训练不行,测试也不行
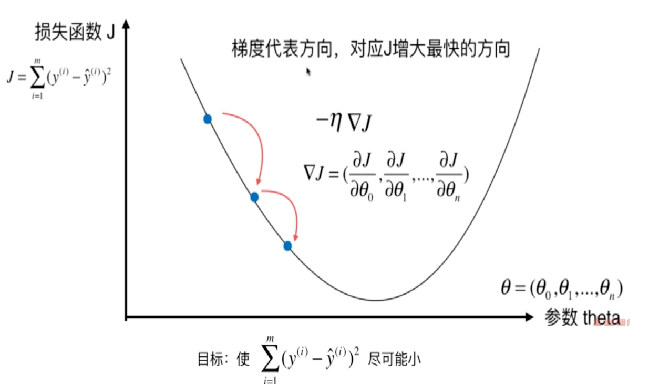
梯度下降法
是一种基于搜索的最优化方法,最小化损失函数,梯度下降法的算法可以有代数法和矩阵法(也称向量法) 。
随机梯度下降法Stochastic Gradient Descent
在与求梯度时没有用所有的样本的数据,而是仅仅选取一个样本来求梯度,用一个样本决定梯度方向,导致解很有可能不是最优。对于收敛速度来说,由于随机梯度下降法一次迭代一个样本,导致迭代方向变化很大,不能很快的收敛到局部最优解。
论文内容
数据集
ImageNet是一个拥有超过1500万个已标记高分辨率图像的数据集,大概有22,000个类别。
在ImageNet上,习惯上使用两种错误率:top-1和top-5,图像采样到256×256的固定分辨率。
Top-1:排名第一的类别与实际结果相符的准确率
Top-5:指排名前五的类别包含实际结果的准确率
架构
包含八个学习层——五个卷积层和三个全连接层。
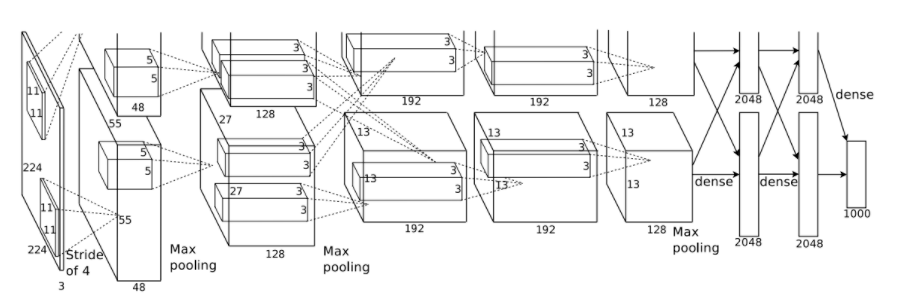
前五个是卷积层,其余三个为全连接层。最后的全连接层的输出被送到1000维的softmax函数,其产生1000个类的预测。ReLU应用于每个卷积层和全连接层的输出。
- 第一个卷积层的输入为224×224×3的图像,对其使用96个大小为11×11×3、步长为4(步长表示内核映射中相邻神经元感受野中心之间的距离)的内核来处理输入图像。
- 第二个卷积层将第一个卷积层的输出(响应归一化以及池化)作为输入,并使用256个内核处理图像,每个内核大小为5×5×48
- 第三个、第四个和第五个卷积层彼此连接而中间没有任何池化或归一化层。
- 第三个卷积层有384个内核,每个的大小为3×3×256,其输入为第二个卷积层的输出。
- 第四个卷积层有384个内核,每个内核大小为3×3×192。
- 第五个卷积层有256个内核,每个内核大小为3×3×192。
- 全连接层各有4096个神经元。
ReLU非线性单元
使用ReLU做为激活函数的卷积神经网络迭代次数比起使用tanh作为激活函数的训练起来快了好几倍。局部响应归一化
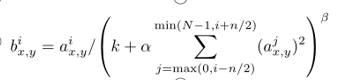
把数据变成(0,1)小数,常数k, n, α, β都是超参数,它们的值是通过验证集确定的,我们在某些层的应用ReLU后再使用这种归一化方法,响应归一化将我们的top-1和top-5的错误率分别降低了1.4%和1.2%。重叠池化
在传统方法中,相邻池化单元之间互不重叠,池化层可以被认为是由一些间隔为s个像素的池化单元组成的网格,每个都表示了一个以池化单元的位置为中心的大小为z×z的邻域,如果我们令s = z,我们就可以得到CNN中常用的传统的局部池化。如果我们设s<z,则得到重叠池。这就是我们在整个网络中使用的,s=2和z=3。与产生等效尺寸输出的非重叠方案s=2,z=2相比,reduces the top-1 and top-5 error rates by 0.4% and 0.3%。
减少过拟合
1、数据增强(Data Augmentation)
减小过拟合的最简单且最常用的方法就是,使用标签保留转换,人为地放大数据集。
第一种形式包括平移图像和水平映射。我们通过从256×256图像中随机提取224×224的图像块(及其水平映射)并在这些提取的图像块上训练我们的网络。这使我们的训练集的规模增加了2048倍,尽管由此产生的训练样本当然还是高度相互依赖的。
第二种形式的数据增强包括改变训练图像中RGB通道的灰度。我们在整个ImageNet训练集的图像的RGB像素值上使用PCA。我们添加多个通过PCA找到的主成分,大小与相应的特征值成比例,乘以一个随机值,该随机值属于均值为0、标准差为0.1的高斯分布。
2、Dropout
结合许多不同模型的预测结果是减少测试错误率的一种非常成功的方法。但对于花费数天时间训练的大型神经网络来说,它似乎成本太高了。然而,有一种非常有效的模型组合方法,在训练期间,只需要消耗1/2的参数。这个新发现的技术叫做“Dropout”。
以50%的概率将隐含层的神经元输出置为0。以这种方法被置0的神经元不参与网络的前馈和反向传播。这种技术减少了神经元复杂的共适应, 因为神经元不能依赖其他特定神经元的存在。
我们在前两个全连接层上使用了dropout。没有dropout,我们的网络会出现严重的过拟合。
结果
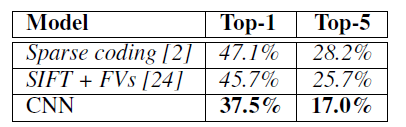
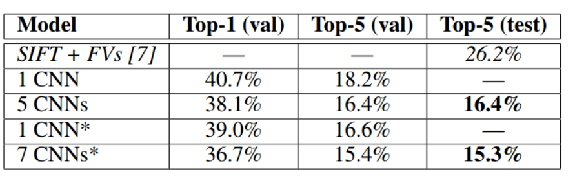
我们在ILSVRC-2010上取得的结果如表1所示。top-1和top-5测试集错误率分别为37.5%和17.0%
我们还在ILSVRC-2012竞赛中使用了我们的模型,并在表2中给出了我们的结果。
CNN的top-5错误率达到了18.2%。
计算均值,得到的错误率为16.4%。
在最后一个池化层之后,额外添加第六个卷积层,得到的错误率为16.6%






 关于 LearnKu
关于 LearnKu



