
 每天一篇CV paper
每天一篇CV paperClassMix:基于分割的数据增强的半监督学习
引言
一致性正则化的半监督学习在图像分类中取得了显著的进展,主要利用强数据增强来加强对未标记的一致性预测图片,然而在半监督语义分割中被证明是无效的。
一致性正则化的核心思想:对未标记数据的预测应该不受扰动的影响。
ClassMix:
- 扩展策略从一幅图像中删除一半的预测类,并将它们粘贴到另一幅图像上,形成一个新的样本,同时不需要真正的注释。
- 通过利用网络学习预测原始图像的像素级语义映射。对混合图像的预测随后被训练成与混合前对图像的预测一致。
- 根据分类一致性正则化趋势,还集成了熵最小化,鼓励网络对未标记数据生成低熵预测。
主要贡献:
(1)我们引入了一种新的扩展策略,用于语义分割,我们称之为ClassMix。
(2)我们将ClassMix整合到一个统一的框架中,使用一致性正则化和伪标记进行语义分割。
(3)通过在城市景观数据集上获得最先进的半监督学习结果,以及在Pascal VOC数据集上获得具有竞争力的结果。
伪标记
对于没有标签的数据,选取预测概率最大的类别作为其伪标签,它的主要动机来自熵正则化,鼓励网络对未标记的图像进行自信的预测。
半监督学习的目标是利用无标签数据来提高泛化性能。
使用伪标签作为熵正则化的训练:
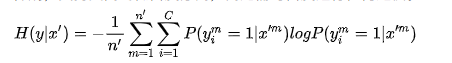
相关介绍
在CutMix算法中,从一幅图像中剪切出随机的矩形区域,然后粘贴到另一幅图像上。这种技术是基于基于掩码的混合,即使用与图像大小相同的二进制掩码混合两幅图像。
ClassMix是基于相似的原理组合图像,并利用预测分割来生成二进制掩码,而不是矩形。ClassMix使用两个未标记的图像作为输入,并输出一个新的增强图像,以及相应的人工标签。输出的增强图像是由输入的混合组成的,其中一个图像的语义类的一半粘贴到另一个上面,导致输出是新颖和多样的。
算法
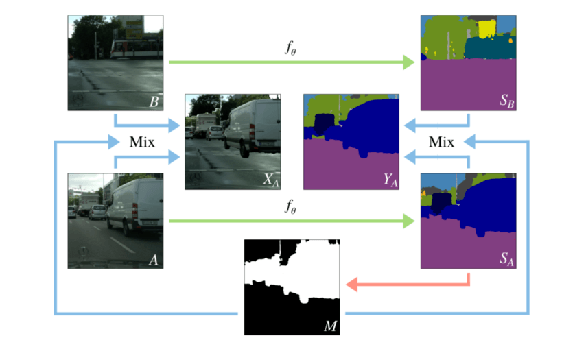
两个未标记的图像A和B,从数据集中采样。
通过分割网络f(θ),而输出预测SA和SB,二进制Mask M是随机选择SA一半的类别的argmax预测,将这些类中的像素设置为值1,而其他的值都是0。
然后使用这个Mask将图像A和B混合为增强图像XA中,对SA,SB的预测也进行了同样的混合,生成人造标签YA。
伪代码如下:

Mean-Teacher
Mean Teacher Framework模型即充当学生,又充当老师。作为老师,用来产生学生学习时的目标,作为学生,利用老师模型产生的目标来学习。教师模式是连续学生模式的平均值,因此我们叫它Mean teacher。
从当前模型(Student model),构造出一个比 Student model 更好一些的 Teather model,然后用这个 Teacher model 的预测来训练 Student model(即 Consistency Regularization)
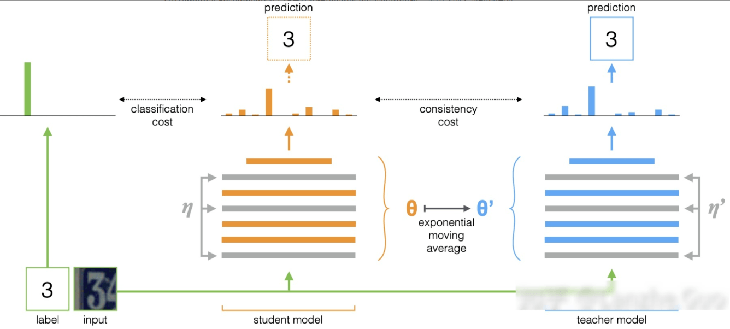
对应损失函数:
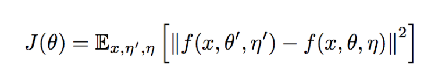
本文为了提高预测的稳定性,使用Mean Teacher。我们不再使用f(θ)来预测ClassMix中的输入图像A和B,而是使用f(θ’) ,其中θ’是在整个优化过程中θ移动的平均。
损失函数
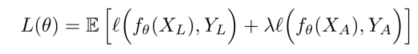
XL是一种从标记图像数据集中均匀随机采样的图像
YL 则是相应的ground-truth语义图
XA和YA为增强方法产生的增强图像和其人工标号,
λ是一个控制监督和非监督术语之间平衡的超参数
ℓ交叉熵损失,对语义映射中的所有像素位置进行平均计算
对于交叉熵损失:
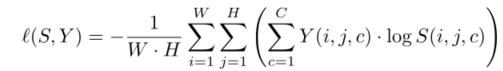
W和H为图像的宽度和高度,
分别根据预测S和目标Y,S(i, j, c)和Y (i, j, c)是像素在坐标中的概率,
坐标中的像i, j属于c类,随机梯度下降法训练。
无监督权值λ开始接近于零对训练过程是有益的。
Experiments
使用PyTorch框架实现的,并在两个Tesla V100 gpu上进行培训。采用了ResNet101的DeepLab-v2框架。backbone在ImageNet和COCO上预先训练。
在Cityscapes和Pascal VOC 2012两个语义分割数据集上给出了结果。
- cityscape城市风景数据集包含2975张训练图像和500张验证图像,使用两个带标记和两个未标记样本的批次,训练40k迭代。
- 对于Pascal VOC 2012数据集,我们使用来自语义边界数据集的原始图像和额外的注释图像,10,582张训练图像和1,449张验证图像。

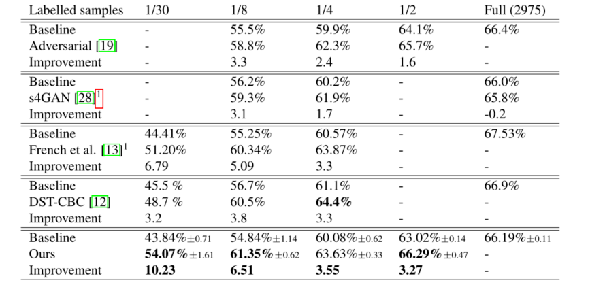
ClassMix在城市景观中表现良好的第三个原因可能是数据集中的图像相似。因此,从一个图像粘贴到另一个图像的对象很可能以合理的方式结束。
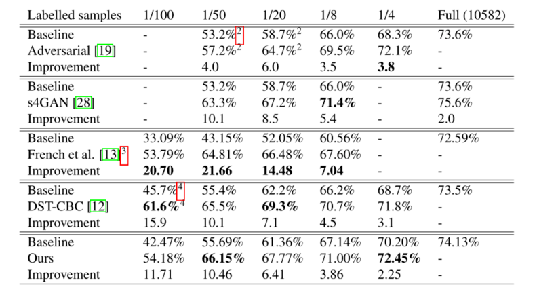
Pascal VOC 2012数据集上使用我们的方法得到的结果是具有竞争性的,我们的性能是最强的。与城市景观不同,图像中没有特定类出现的位置或上下文。因此,粘贴对象通常会在不合理的环境中结束,我们认为这不利于性能。
我们在Pascal数据集上的结果不如在城市景观上的结果那么强。我们认为这在很大程度上是因为Pascal在每张图像中只包含很少的类,这意味着ClassMix中蒙版的多样性将非常小






 关于 LearnKu
关于 LearnKu




推荐文章: