
 每天一篇CV paper
每天一篇CV paperMedical Transformer
论文标题:Medical Transformer: Gated Axial-Attention for Medical Image Segmentation
引言
卷积体系结构缺乏对图像中的远程依赖关系的理解。
基于Transformer的体系结构利用自我注意机制,编码长期依赖关系,并具有极富表现力的表示法。
我们提出了一种门控轴向注意模型,通过在自我注意模块中引入额外的控制机制来扩展现有的体系结构。
为了对模型进行有效的医学图像训练,我们提出了一种局部-全局训练策略(LOGO),进一步提高了模型的性能。
具体地说,我们对整个图像和patches进行操作,分别学习全局特征和局部特征。
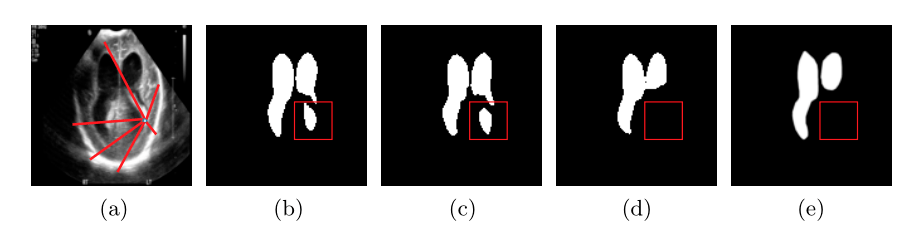
(A)活体早产儿脑室输入超声 (B)U-Net (C)Res-UNET (D)MedT和(E)Ground Truth的预测
在(B)和(C)中,我们可以看到卷积网络错误地将背景分类为脑室,而基于transformer-based 的方法没有犯这种错误。
这是因为我们提出的方法学习像素区域与背景区域的长期依赖关系。
相关
最近,TransUNet被提出,它基于transformer的编码器对图像块序列进行操作,并使用带有跳过连接的卷积解码器来分割医学图像。它仍然依赖于通过在大型图像训练而获得的预先训练的权重。
我们探索了只使用自我注意机制的transformers作为医学图像分割的编码器的可行性,而不需要任何预训练。
医学图像贴标签的过程也很昂贵,需要专业知识。为此我们提出了一种门控位置敏感轴向注意机制,引入了四个门来控制位置嵌入,提供给键、查询和值的信息量。这些门控是可学习的参数。
Medical Transformer
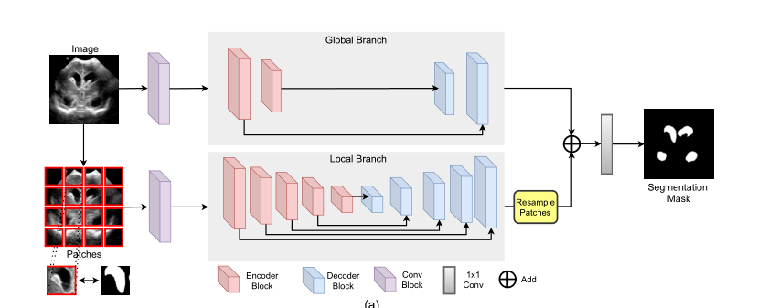
MedT有两个分支机构:一个全局分支和一个本地分支。
这两分支的输入是从初始卷积块提取的特征图。
在MedT的全局分支中,我们有2个编码器块和2个解码器块。
在本地分支中,我们有5个编码器块和5个解码器块。
Self-Attention
高度H、权重W和通道Cin的输入特征映射,输出
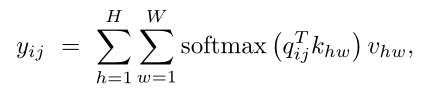
其中查询q、键k和值v都是从输入x计算的投影,
投影矩阵WQ,WK,WV是可学习的.计算这种全局亲和度关系是非常昂贵的,并且随着特征图大小的增加,将 Self-Attention用于视觉模型体系结构通常变得不可行。
Axial-Attention
为了克服亲和度计算的复杂性,将自我注意分解为两个自我注意模块。
第一个模块在要素地图高度轴上执行自我关注,第二个模块在宽度轴上操作。
轴向注意应用于高度和宽度轴上,有效地模拟了原有的自我注意机制,具有更好的计算效率。在查询、关键字和值中的附加位置偏差利用精确的位置信息来捕获远程交互。
沿宽度轴施加的轴向注意:
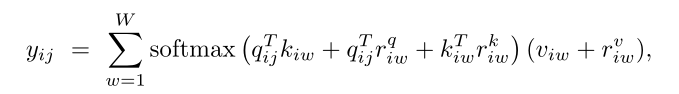
Gated Axial-Attention
对于小规模数据集的实验,像医学图像分割中,位置偏差很难学习,因此在编码远程交互时并不总是准确的。
因此,我们提出了一种改进的轴向注意块,它可以控制位置偏差对非局部语境编码的影响。
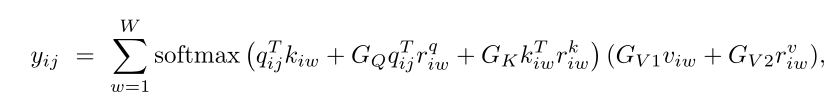
GQ、GK、GV1、GV2是可学习的参数,它们共同创建门控机制。
Local-Global Training
对于医学图像分割这样的任务,仅靠patches训练是不够的。为了提高对图像的整体理解,我们建议使用网络的两个分支,即处理图像原始分辨率的全局分支和处理图像块的局部分支。
在全局分支中,我们减少门控轴向transformer的数量。
在本地分支中,我们创建大小为 原图/4 的16个图像块。在局部分支中,每个patch通过网络进行反馈,并根据其位置对输出的特征地图进行重新采样,以获得输出的特征地图。然后将两个分支的输出特征图相加并通过1×1卷积层以产生输出分割掩码。
全局分支关注的是高层信息,而局部分支关注的是更精细的细节
Experiments
我们使用脑解剖分割(超声)、腺体分割(显微)和MoNuSeg(显微)数据集。
MedT在Pytorch中实现。我们使用二进制交叉熵(CE)损失来训练我们的网络。
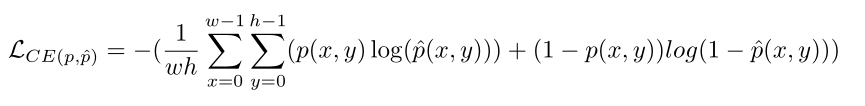
其中w和h是图像的尺寸,p(x,y)对应于图像中的像素,ˆp(x,y)表示在特定位置(x,y)的输出预测。
对于卷积baselines,我们与完全卷积网络(FCN)、U-NET、U-NET++和Res-UNET进行了比较。
对于基于transformer-based baselines,我们使用Axial-Attention U-Net。
Results
我们使用F1和IOU分数来将我们提出的方法与基线进行比较。
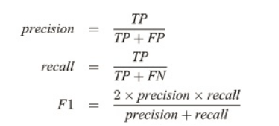
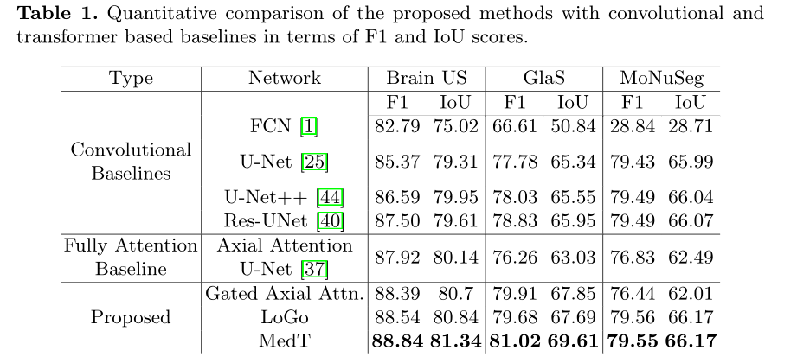
我们最终的架构MedT比以前的方法执行得更好。
F1: 在Brain US、GLAS和MoNuSeg数据集上,比完全注意力基线分别提高了0.92%、4.76%和2.72%。对最佳卷积基线的改善分别为1.32%、2.19%和0.06%。
对于定性分析,我们可视化了来自U-Net、ResUNet、Axial Attribute U-Net和我们提出的方法MedT。
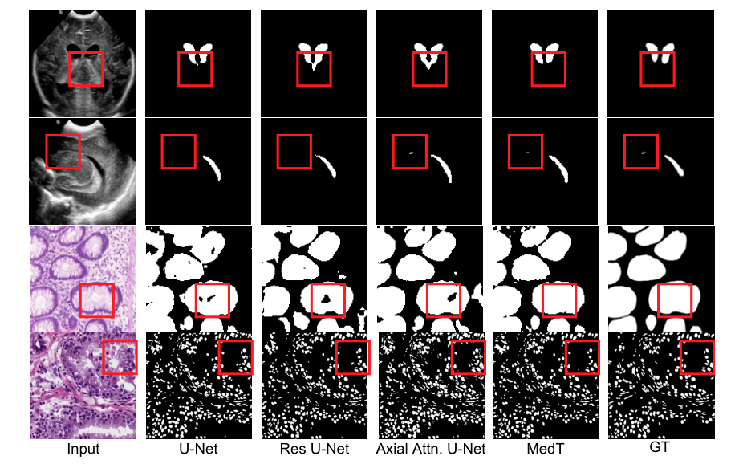
红色方框突出了MedT在哪些方面比其他方法执行得更好。






 关于 LearnKu
关于 LearnKu



