
 每日一题
每日一题【2021-07-16】为什么 redo log 需要两阶段提交?
请移步至:
每日一题 查看更多的题目 ~
本问答为【极客时间】课程【MySQL 实战 45 讲】的内容整理
我们先来看一下,什么是“redo log 的两阶段提交”。
先从一条 MySQL 的更新语句开始:
update T set c=c+1 where ID=2;Server 层
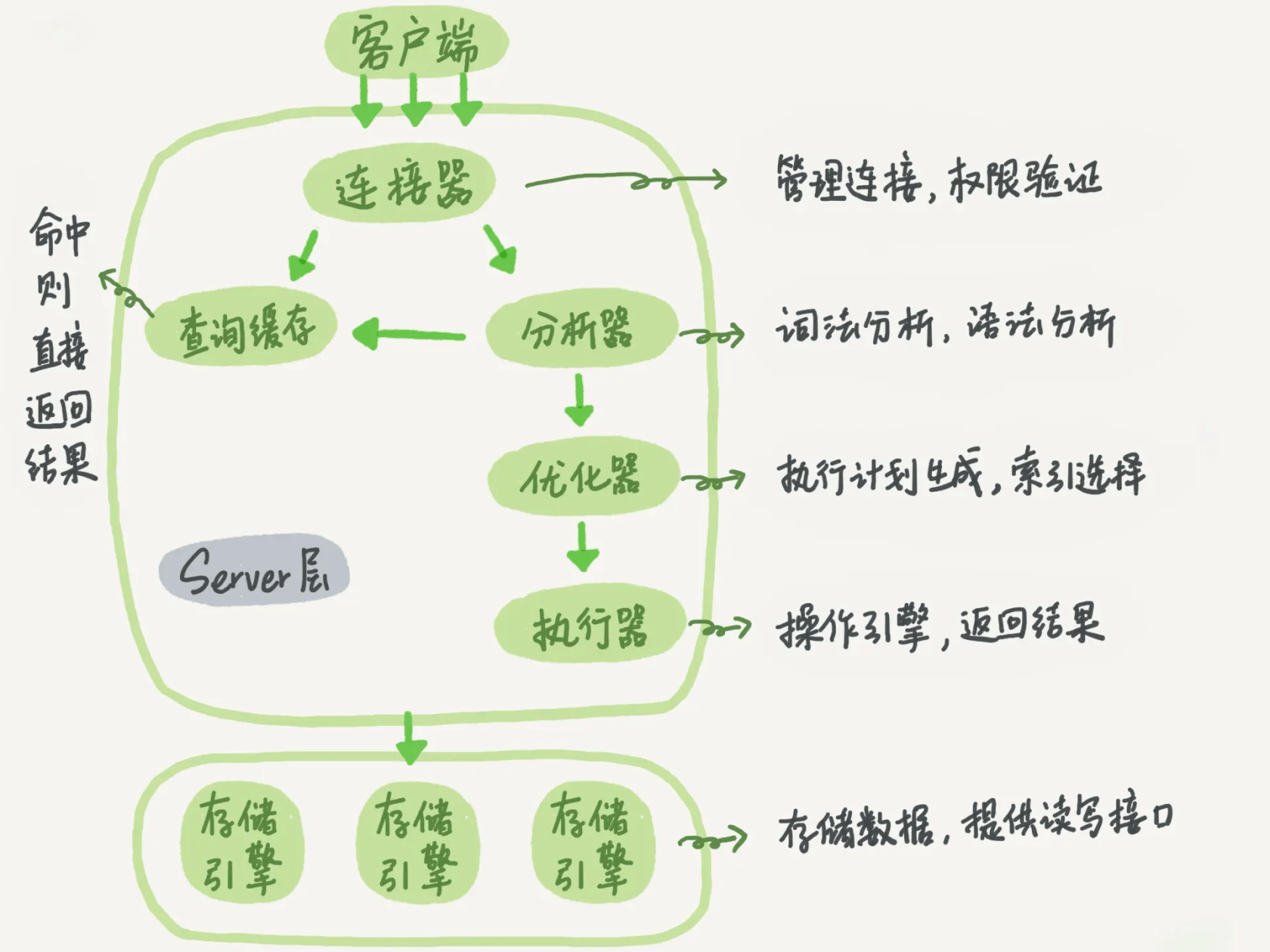
在我们执行这条语句之前,首先要连接数据库,这是连接器的工作。
因为这条语句是一个更新语句,在一个表上有更新操作的时候,跟这个表有关的查询缓存会失效,所以这条语句就会把表 T 上所有缓存结果都清空。
解析来分析器通过词法分析和语法分析知道这是一条更新语句,优化器决定要使用 ID 这个索引。
存储引擎层
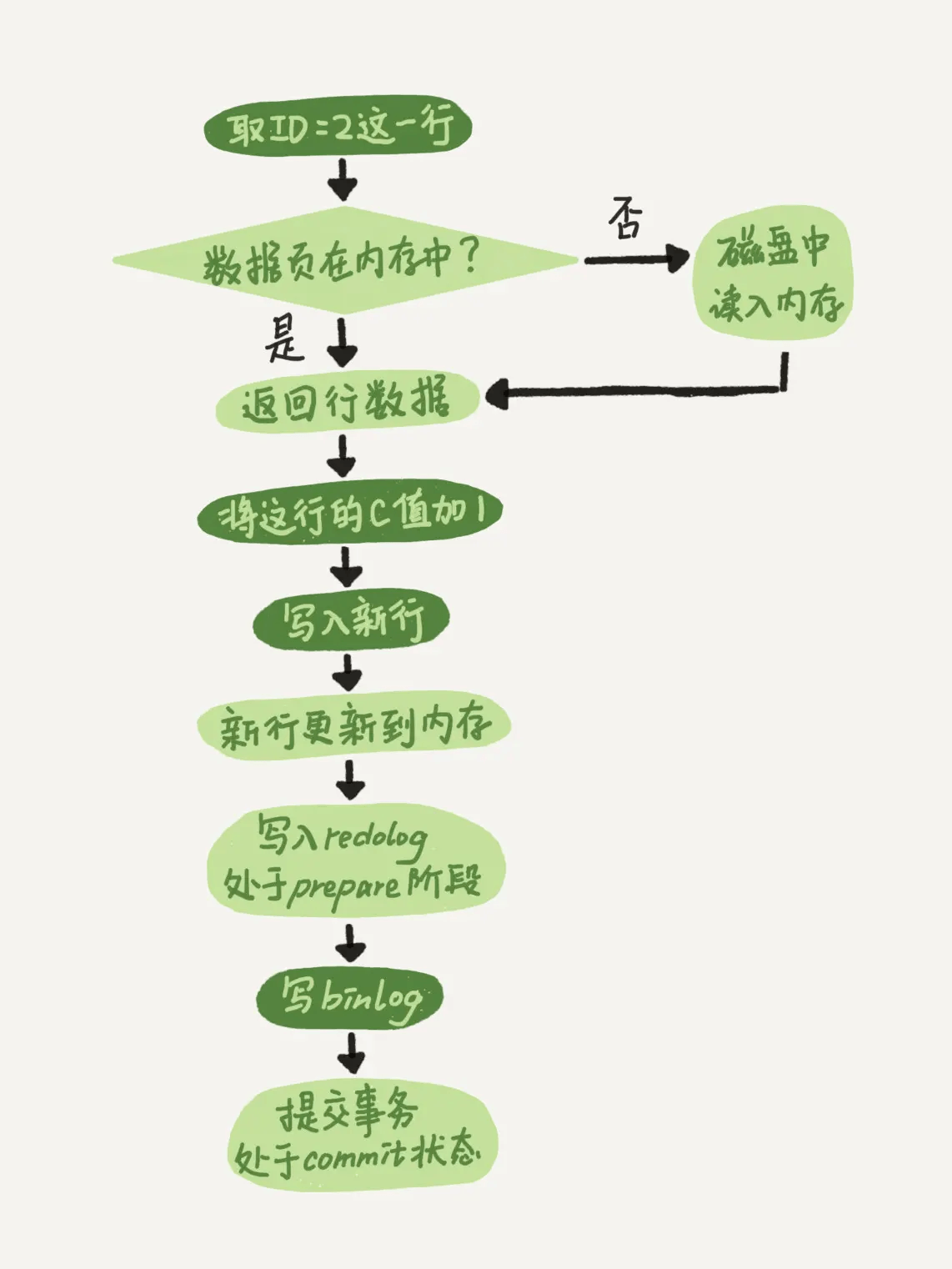
图中浅色框表示在 InnoDB 引擎内部执行的,深色框表示在执行器中执行的。
执行器先找引擎取ID=2 这一行。ID 是主键,引擎直接用树搜索找到这一行。如果 ID=2 这一行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回。
执行器拿到引擎给的行数据,把这个值加上 1,比如原来是 N,现在就是 N+1,得到新的一行数据,再调用引擎接口写入这行新数据。
引擎将这行新数据更新到内存中,同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务。
执行器生成这个操作的 binlog,并把 binlog 写入磁盘。
执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交(commit)状态,更新完成。
我们看到,redo log 的写入被拆成了两个部分:prepare 和 commit,这就是“两阶段提交”。
为什么 redo log 需要两阶段提交
使用反证法来思考,redo log 和 binlog 是两个独立的逻辑,如果我们的 redo log 不使用两阶段提交,要么就是先写完 redo log 再写 binlog,要么就是先写完 binlog 再写 redo log。我们看看这两种方式会出现什么问题。
我们仍然执行上面的更新语句,假设表的当前 ID=2 的行,字段 c 的值是 0,再假设执行 update 语句过程中在写完第一个日志后,第二个日志还没有写完的期间发生了 crash,会出现什么情况呢?
- 先写 redo log 后写 binlog。
假设在 redo log 写完,binlog 还没有写完的时候,MySQL 进程异常重启。由于我们前面说过的,redo log 写完之后,系统即使崩溃,仍然能够把数据恢复回来,所以恢复后这一行 c 的值是 1。但是由于 binlog 没写完就 crash 了,这时候 binlog 里面就没有记录这个语句。因此,之后备份日志的时候,存起来的 binlog 里面就没有这条语句。然后你会发现,如果需要用这个 binlog 来恢复临时库的话,由于这个语句的 binlog 丢失,这个临时库就会少了这一次更新,恢复出来的这一行 c 的值就是 0,与原库的值不同。
- 先写 binlog 后写 redo log。
如果在 binlog 写完之后 crash,由于 redo log 还没写,崩溃恢复以后这个事务无效,所以这一行 c 的值是 0。但是 binlog 里面已经记录了“把 c 从 0 改成 1”这个日志。所以,在之后用 binlog 来恢复的时候就多了一个事务出来,恢复出来的这一行 c 的值就是 1,与原库的值不同。
综上所示,我们得出了结论,为什么 redo log 需要两阶段提交?因为,两阶段提交就是让 redo log 和 binlog 表示事务的提交状态的逻辑保持一致。
redo log 和 binlog 具有关联性,在恢复数据时,redo log 用于恢复主机故障时的未更新的物理数据,binlog用于备份操作。每个阶段的 log 操作都是记录在磁盘的,在恢复数据时,redo log 状态为 commit 则说明 binlog 也成功,直接恢复数据;如果 redo log 是 prepare,则需要查询对应的 binlog 事务是否成功,决定是回滚还是执行。







 关于 LearnKu
关于 LearnKu



