
 做过的项目和反思
做过的项目和反思唱吧面试
一面
- 自我介绍:新浪彩通,滴滴
- 介绍项目:定时任务系统
- Redis前一名和后一名的分数差别是多少?
zadd key score value
zadd rankKey 100 zs
zadd rankKey 200 ls
…100个用户
第70名和71名的分数差别是多少呢?
zrank rankKey 70Name
zrank rankKey 71Name
这样是可以的,但是必须知道70Name和71Name。如果我做一个排行榜会怎么做?
zrange rankKey 0 100 //前100名
zrange rankKey 70 70 //返回70Name
但是Redis的score排序是低分在前,高分在后。上面这个其实是第29和第30名。应该这样:
zrange rankKey -70 -70 //70Name
zrange rankKey -71 -71 //71Name
zscore rankKey 70Name
zscore rankKey 71Name
MySQL查询: uid,gid,gnum,time
select uid from (select uid,gnum from t where gid=1 group by uid) as t2 where t2.gnum>100;
MySQL Explain 关注的字段和查询效率排序
关注的字段:type,key,extra,rowsconst>ref>index>range>all
主键=唯一键>二级索引>覆盖索引>范围查找>ALL
extra:可能存在的一些优化提示 MRR ICP where index
- MySQL string查询的最长前缀是多少?
key
idx_name(name(10))
最大可设置长度根据行格式而定:Redundant,Compact默认最长是255个utf8,对应长度就是255*3=767。dynamic和Compressed默认最长是3072 byte,3072/3=1024个utf8.
Redis Map的遍历:hgetall
1亿行的日志,查找前100的IP排序。
PHP使用yield生成器按行读取数据,然后分析完之后再继续向下读。把IP通过数组记录
recod[ip]++。为了使程序更快,可以优化:(1)每次读多行(2)多个进程同时执行。Redis怎么切换主从
面试官这个问题问的不够具体,让我听了摸不着头脑。主从是通过slaveof命令,问这个问题的原因是因为面试官所处的公司出现Redis主机不稳定的情况。这种情况很容易丢失数据,因为AOF和RDB都有一定的可能丢失数据。然后Redis的连接是通过什么连接的呢?面试官没有说,想了半天不知道该怎么回答。
面试官:
(1)从服务器执行 slaveof NO ONE 则可写
(2)业务代码调用改成连接从库
(3)主库Redis服务重启之后,执行slaveof 从库IP
疑问:
(1)这里面如何保证数据不丢失呢?
(2)真的需要切换业务代码吗?
PHP单例要注意的点
(1)构造方法私有化
(2)禁止__clone
(3)禁止__invokego怎么让map有序
这个问题问的我有点懵。map为了保证无序做了很多操作,为什么还要让map有序呢?
比如:map[string]string,要让获取map有序吗?
(1)借助[]string存key,然后排好序之后再遍历切片,从map获取value?
(2)自己定一个struct,怎么定义呢?
type sortMap struct {
}Https的TLS握手
(1)Client向Server发起连接 Hello,包括数据:
TLS版本、Client Random、加密算法(eg:RSA)
(2)Server收到Client发起的连接,然后:- 校验TLS版本,版本不支持直接退出。
- 确认加密算法(RSA)
- 给客户端发送自己的随机数:Server Random
- 给客户端发送服务器使用 的证书
- 服务端 Hello 完成
(3)客户端通过浏览器或者操作系统的CA公钥验证服务端的证书,并取出公钥。然后在生成一个随机数 pre-master Random,并且通过pre-master Random+Client Random+Server Random+证书和加密算法生成会话秘钥。并且将之前生成的数据做个摘要,供服务端校验。最后告知Server切换通信方式,之后都用会话秘钥通信。
(4)Server接收到pre-master Random,并且也通过协商加密方式加密,告知Client更改通信方式为会话秘钥,TLS连接结束。
怎么做一个Auth授权给三方使用呢?
回忆滴滴的授权登入:
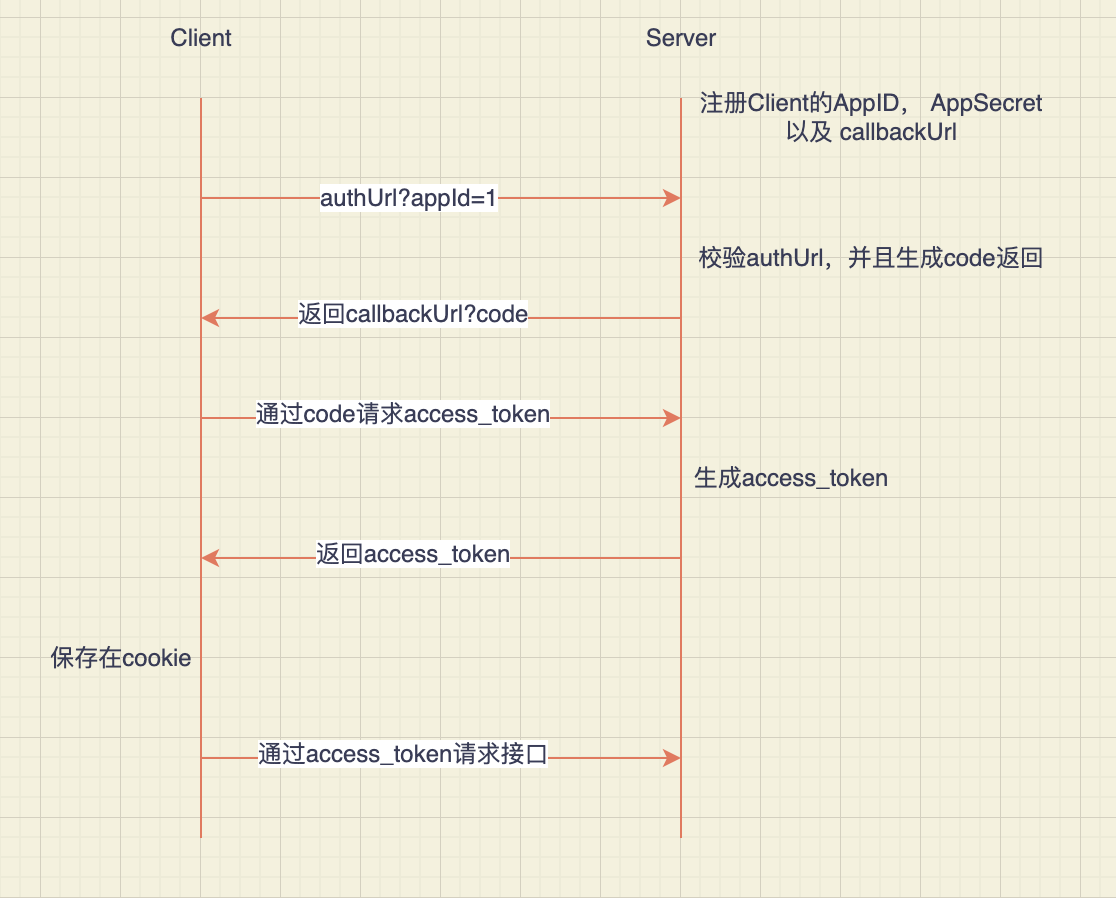
回忆微信公众号的授权登入:
回忆彩通如何做的授权登入:
- Redis的类型和数据结构
string:SDS,int
list:linkedlist,ziplist
hash:dict,ziplist
set:dict,intset
sorted set:skiplist,ziplist
请介绍下跳表:
typedef struct zset {
dict *dict; //O(1)复杂度找到value和socre
zskiplist *zsl; //O(logn)复杂度范围查找
} zset;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;zset key score value
zscore key value
zrange key 0 -1
最大层次是64,每个节点的层是随机的,概率是0.25,越高层则概率越低。
自己提问:
- listpack和ziplist的结构区别:
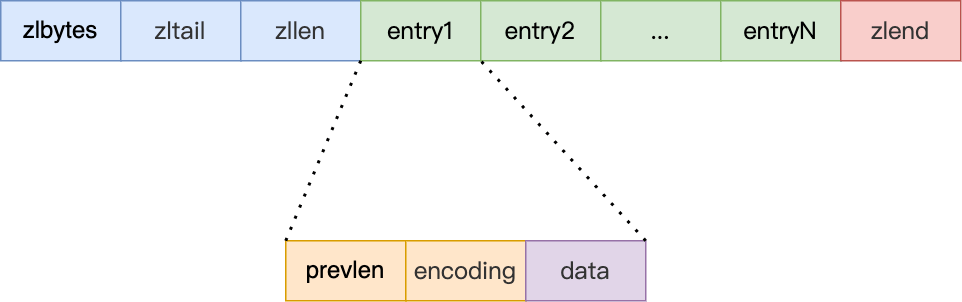
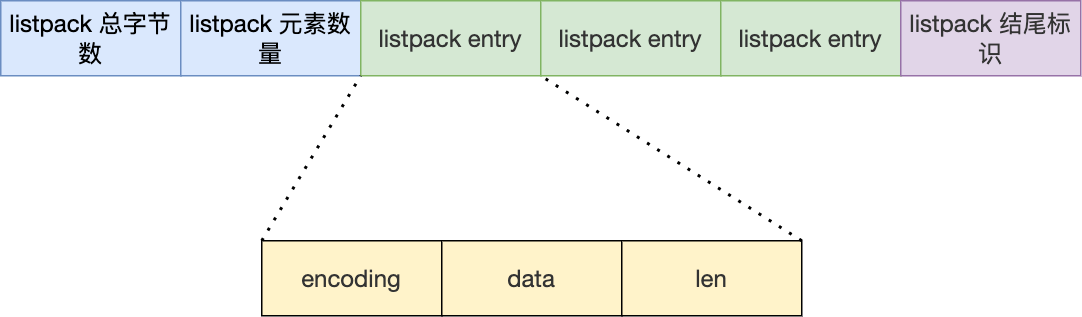
区别:
(1)ziplist的属性zltail没了,这个属性的作用是O(1)复杂度定位到尾节点。
ziplist作为list的底层实现时,获取尾节点是很有必要的操作。因为rpop命令弹出队尾元素。但是listpack不用做list的底层结构,因此比较ziplist和listpack作为sorted set和hash的实现。
(2)有序集合:ziplist作为有序集合的底层实现,如果要获取最后一个元素:zrange key -1 -1 时间复杂度是O(1)。
listpack时间复杂度是:O(1),通过listpack的粽子节长度-1定位到结尾标志。然后在通过len的长度查找前继节点。所以解决了ziplist的prevlen的问题。
- quicklist和ziplist的区别
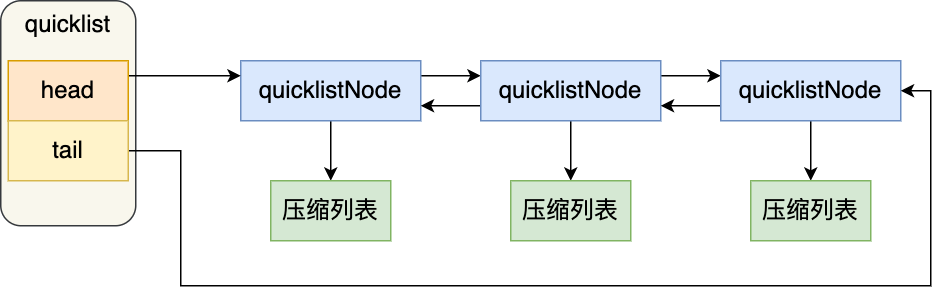
结合了linkedlist和ziplist,作为了新版的list底层实现。
思考:只要去思考的话,总能找到一些优化的手段。而且发现很多优化的手段就是在原来已有的基础上去做一些细微的改动或者两者方案的结合。
二面
- 优惠券项目
- 商户减免实现
- chan实现





 关于 LearnKu
关于 LearnKu



