
 Go高并发实战
Go高并发实战3.5. 一致性Hash算法原理
什么是一致性Hash算法?
用途:快速定位资源,均匀分布
场景:分布式存储,分布式缓存,负载均衡
一致性hash算法:
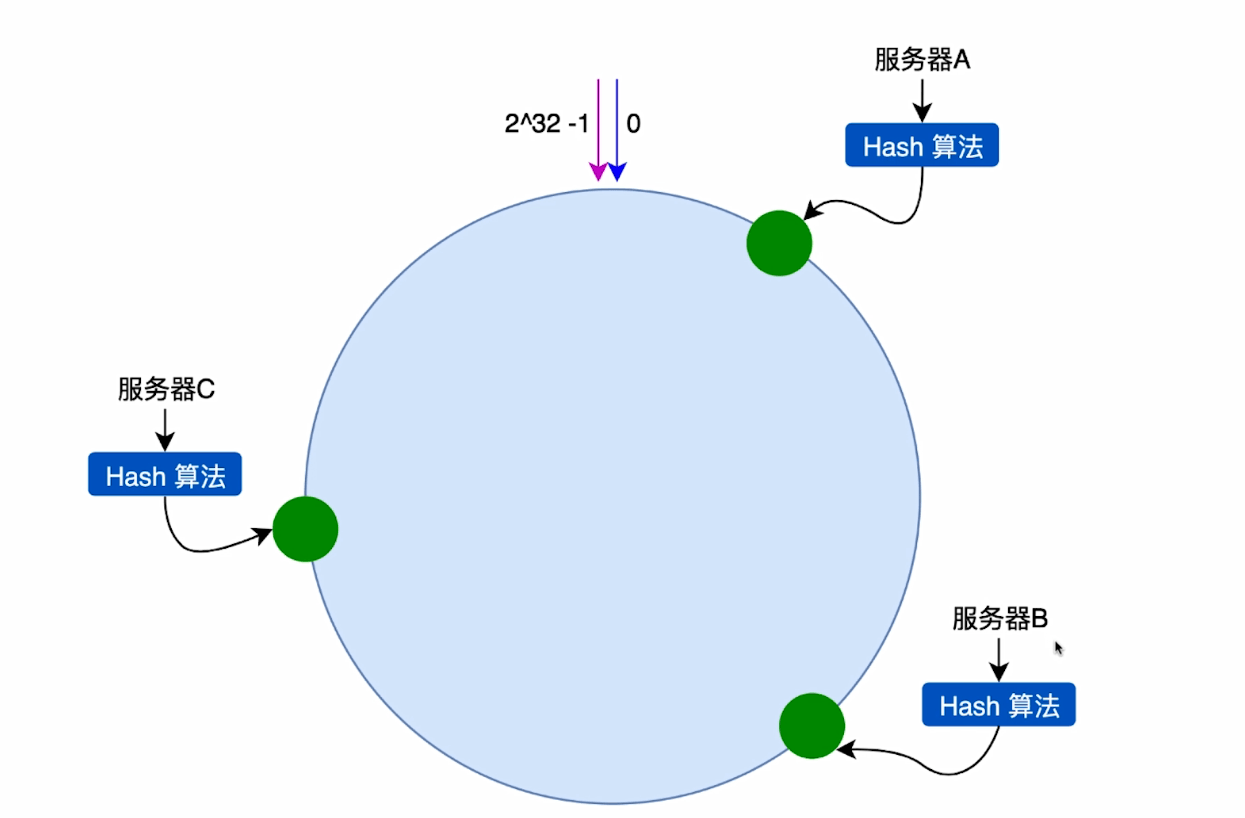
先构造一个0到2的32次方的整数环,这个数大体是43亿左右,然后将服务器的节点的hash值放在该环上,可以理解为将你的ip做hash,将ip的hashcode放在环上,如下图所示
将我们的数据key使用相同的hash算法计算出hashcode放在圆环上,顺时针查找距离这个key的hash值最近的缓存服务器的节点,然后将value存储到该服务器节点上,比如图中数据A讲过hash算法算出hashcode离着服务器B最近则value就存储到了服务器B上了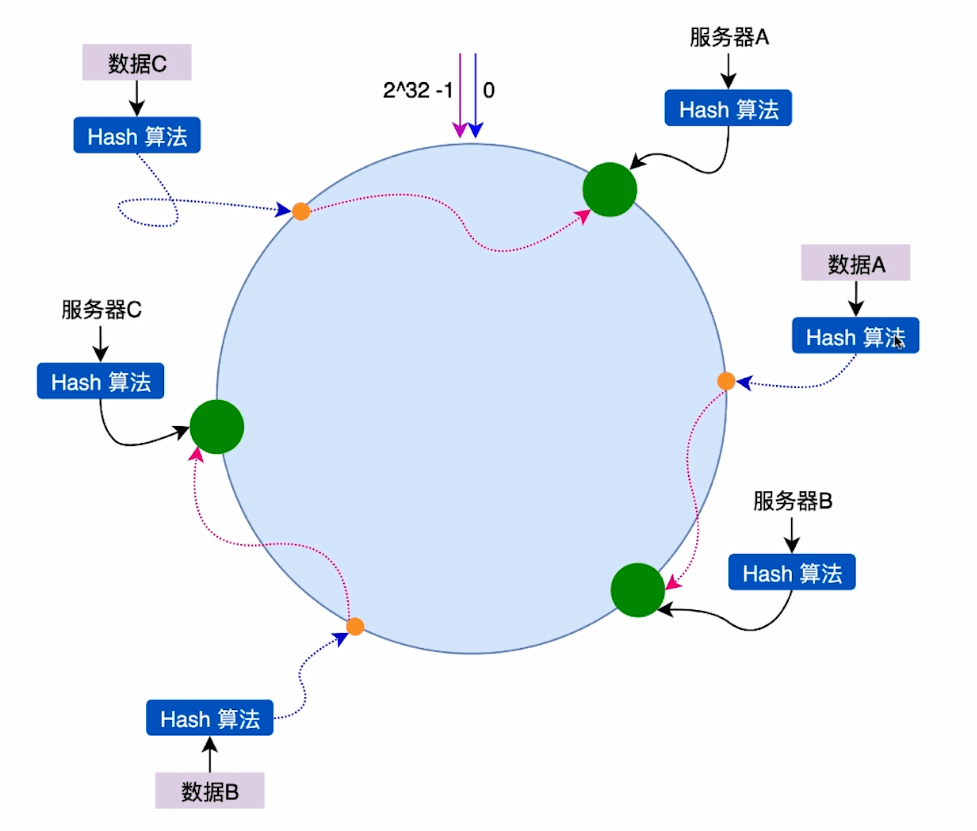
但是还有个问题,一致性hash算法并不是你想象的那么公平,就这么均匀的分布,当你服务器节点少的时候很有可能就会造成节点分布不均匀的情况发生,比如下图你就两台服务器导致节点分配不均匀,那么就很容易造成数据存储严重倾斜的问题,可能大部分都存储到了A服务器B服务器的数据就很少
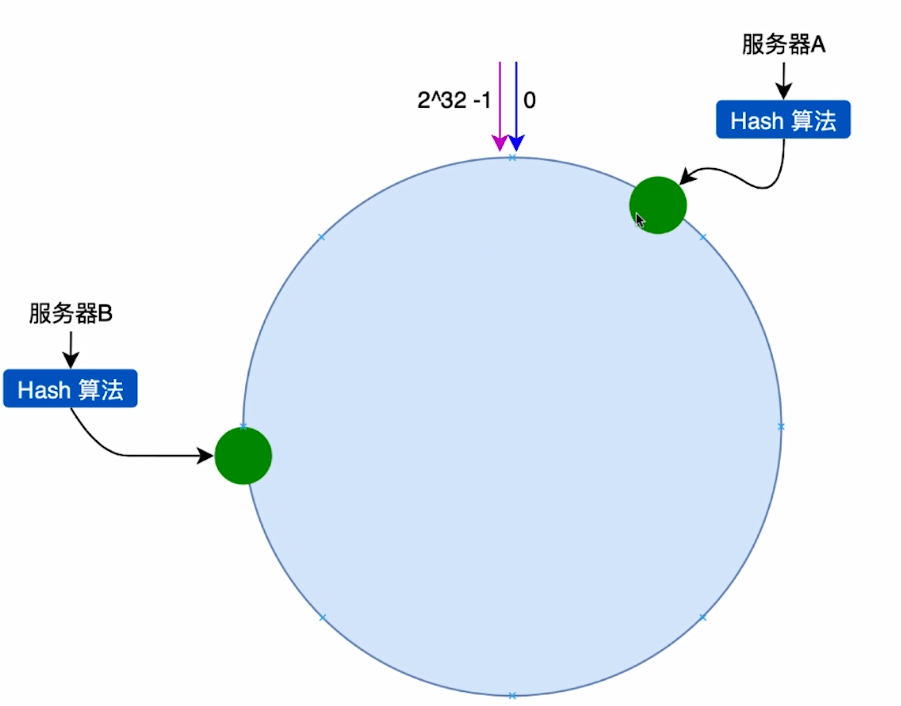
如何解决这种数据倾斜的问题呢?
引入虚拟节点,在现有节点上层再增加一层虚拟节点,比如根据服务器A的ip的hash值按照一定规律复制出三个虚拟节点A1 A2 A3 服务器B 和服务器C都一样都复制出三个虚拟节点,那么拿到key之后在闭环上定位hashcode 先找到虚拟服务器节点,然后再得到物理服务器信息,从而知道最终要存储在哪台服务器上!这样三台服务器根据虚拟节点被选中的概率就是一样的啦!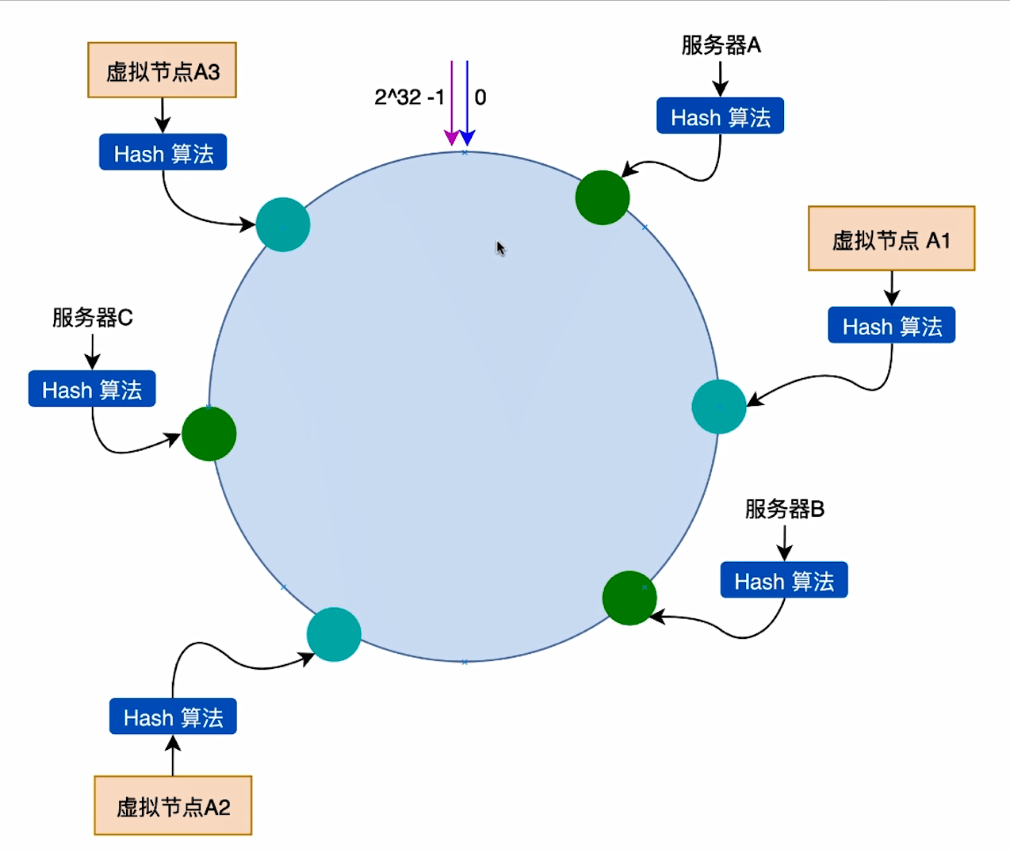
这样,一台服务器节点,被环中多个虚拟节点所代表,且多个节点均匀分配。很显然,每个物理节点对应的虚拟节点越多,各个物理节点之间的负载越均衡,新加入物理服务器对原有的物理服务器的影响越保持一致!






 关于 LearnKu
关于 LearnKu




推荐文章: