
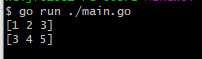
一道挺有意思的题
package main
import (
"encoding/json"
"fmt"
)
type AutoGenerated struct {
Age int `json:"age"`
Name string `json:"name"`
Child []int `json:"child"`
}
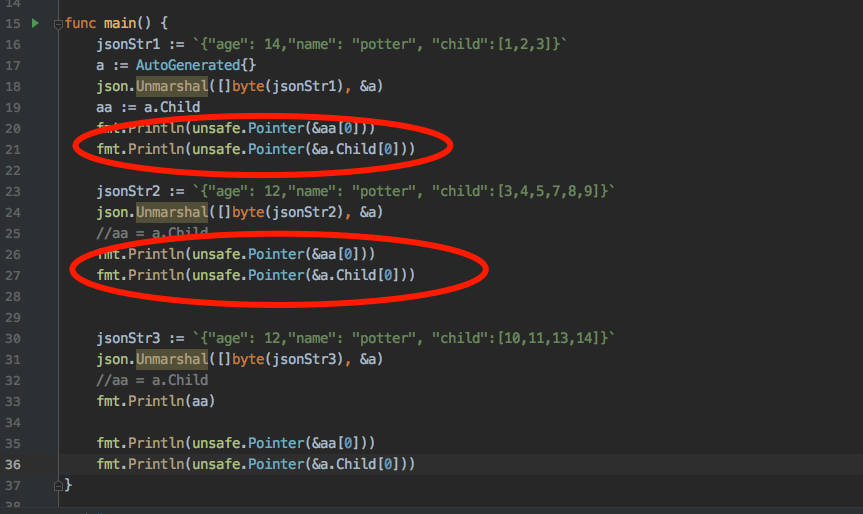
func main() {
jsonStr1 := `{"age": 14,"name": "potter", "child":[1,2,3]}`
a := AutoGenerated{}
json.Unmarshal([]byte(jsonStr1), &a)
aa := a.Child
fmt.Println(aa)
jsonStr2 := `{"age": 12,"name": "potter", "child":[3,4,5,7,8,9]}`
json.Unmarshal([]byte(jsonStr2), &a)
fmt.Println(aa)
}选项:
A:[1 2 3] [1 2 3]
B:[1 2 3] [3 4 5]
C:[1 2 3] [3 4 5 6 7 8 9]
D:[1 2 3] [3 4 5 0 0 0]
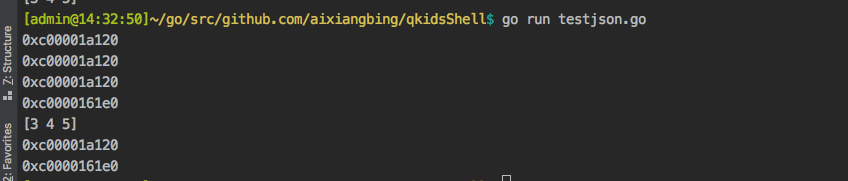
应该选哪个呢?为什么?












 关于 LearnKu
关于 LearnKu




推荐文章: