
一个混乱的gpu/cpu联合调度 大文本离线计算任务,求大佬指导设计方案,没有完整方案只提建议也接受
之前的描述
问答:golang协程调度 - 线程数设置越多,资源利用率越低,执行时间无差别...
执行流程如图所示

执行过程说明:
- 解析bed文件,按业务逻辑拆分为多个region。(一次性执行完全部放入channel,与后续计算无竞争关系)
- 使用Region pool并行管理N个region处理线程,针对每一个region:
2.1. 初始化一个reader读取record(借助htslib)
2.2. 使用map对record进行配对(配对结果流出速度不稳定,可能相差不远就能配对,也可能距离几万个record才配对)
2.3. 配对后根据业务逻辑区分delins和nonDelins(1:9)
2.4. 汇集一组delins后(64)或一组nonDelins(4096)后分别提交给go worker和gpu worker完成这一组计算
2.5. 每一个region内初始化一个result,属于同一组的所有go worker和gpu worker将结果写入同一个result
2.6. 待record读取计算结束,将result写入result channel - writer线程处理result channel中的数据,输出到文件。
一些测试和结果和个人分析
1.执行读record,配对record然后丢弃,不做下游计算。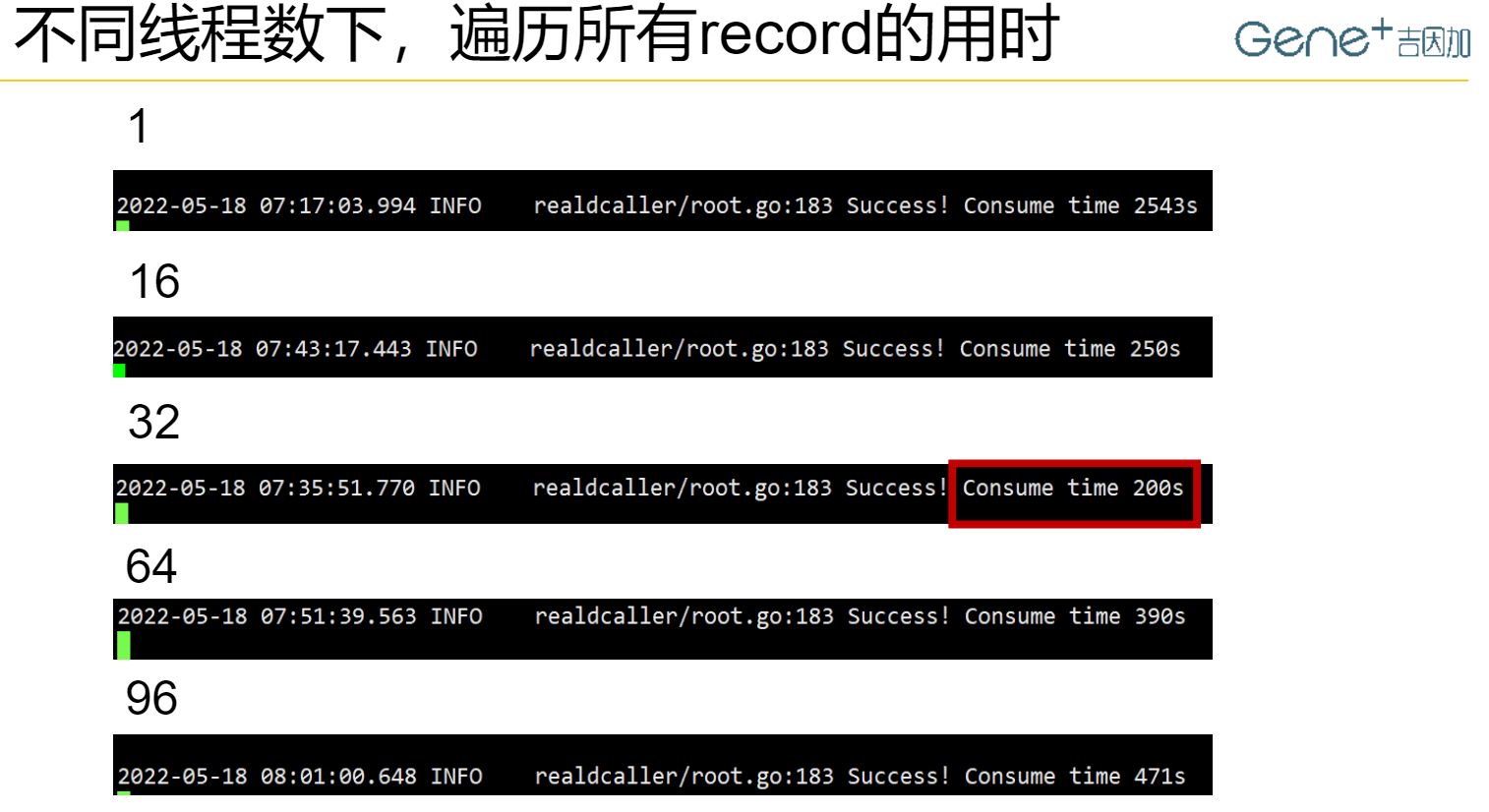
- 线程池使用的ants。根据其提供的接口动态监控正在执行的worker数量。
监控方法:
poolSize分配:
生产者线程: 即流程图中的regionPoolSize = 32
go计算线程: batchNum=64,PoolSize = 64
cuda计算线程:batchNum=4096,PoolSize = 64
执行现场:
生产者数量全程 = 32 为线程池最大值
go计算线程 30-50少数时候会达到64
cuda计算线程 30-50少数时候会达到64









 关于 LearnKu
关于 LearnKu




推荐文章: