
针对 `calculateActiveUsers` 的一些优化
教程中 calculateActiveUsers 方法用到了8次查询,把一些排序和判断都放在代码里了
trait ActiveUserHelper
{
private function calculateActiveUsers()
{
$this->calculateTopicScore();
$this->calculateReplyScore();
// 数组按照得分排序
$users = array_sort($this->users, function ($user) {
return $user['score'];
});
// 我们需要的是倒序,高分靠前,第二个参数为保持数组的 KEY 不变
$users = array_reverse($users, true);
// 只获取我们想要的数量
$users = array_slice($users, 0, $this->user_number, true);
// 新建一个空集合
$active_users = collect();
foreach ($users as $user_id => $user) {
// 找寻下是否可以找到用户
$user = $this->find($user_id);
// 如果数据库里有该用户的话
if ($user) {
// 将此用户实体放入集合的末尾
$active_users->push($user);
}
}
// 返回数据
return $active_users;
}
private function calculateTopicScore()
{
// 从话题数据表里取出限定时间范围($pass_days)内,有发表过话题的用户
// 并且同时取出用户此段时间内发布话题的数量
$topic_users = Topic::query()->select(DB::raw('user_id, count(*) as topic_count'))
->where('created_at', '>=', Carbon::now()->subDays($this->pass_days))
->groupBy('user_id')
->get();
// 根据话题数量计算得分
foreach ($topic_users as $value) {
$this->users[$value->user_id]['score'] = $value->topic_count * $this->topic_weight;
}
}
private function calculateReplyScore()
{
// 从回复数据表里取出限定时间范围($pass_days)内,有发表过回复的用户
// 并且同时取出用户此段时间内发布回复的数量
$reply_users = Reply::query()->select(DB::raw('user_id, count(*) as reply_count'))
->where('created_at', '>=', Carbon::now()->subDays($this->pass_days))
->groupBy('user_id')
->get();
// 根据回复数量计算得分
foreach ($reply_users as $value) {
$reply_score = $value->reply_count * $this->reply_weight;
if (isset($this->users[$value->user_id])) {
$this->users[$value->user_id]['score'] += $reply_score;
} else {
$this->users[$value->user_id]['score'] = $reply_score;
}
}
}
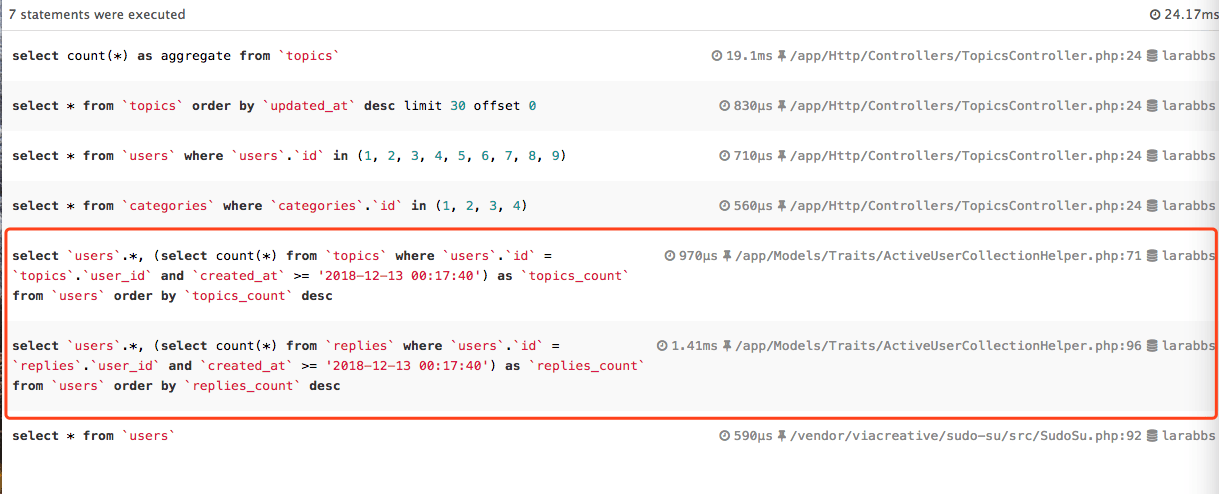
}打开页面时可以看到执行了以下 8 次查询
- select user_id, count(*) as topic_count from
topicswherecreated_at>= '2018-08-09' group byuser_id- select user_id, count(*) as reply_count from
replieswherecreated_at>= '2018-08-09' group byuser_id- select * from
userswhereusers.id= '6' limit 1- select * from
userswhereusers.id= '2' limit 1- select * from
userswhereusers.id= '3' limit 1- select * from
userswhereusers.id= '1' limit 1- select * from
userswhereusers.id= '5' limit 1- select * from
userswhereusers.id= '4' limit 1
我尝试把逻辑都放在 sql 中,重写了这个方法
trait ActiveUserHelper
{
private function calculateActiveUsers()
{
$day = Carbon::now()->subDays($this->pass_days);
$sql = <<<SQL
SELECT u.*
FROM (
SELECT user_id, SUM(score) AS score
FROM (
SELECT user_id, COUNT(*) * $this->topic_weight AS score
FROM topics
WHERE created_at >= '$day'
GROUP BY user_id
UNION ALL
SELECT user_id, COUNT(*) * $this->reply_weight AS score
FROM replies
WHERE created_at >= '$day'
GROUP BY user_id
) t
GROUP BY t.user_id
ORDER BY score DESC
LIMIT 6
) us
JOIN users u ON us.user_id = u.id
SQL;
$active_users = DB::select($sql);
return $active_users;
}
}这样一句 sql 就可以解决这个方法需要做的事情,我想在查询数据库这块应该能省则省。
另外我尝试着用 Laravel 的查询构造器实现了上面的 sql 语句,效果是一样的也是只执行一句 sql。
trait ActiveUserHelper
{
private function calculateActiveUsers()
{
//近期发表话题的用户话题得分
$users_topic_score_query = DB::table('topics')
->select(DB::raw("user_id, count(*)*$this->topic_weight as score"))
->where('created_at', '>=', Carbon::now()->subDays($this->pass_days))
->groupBy('user_id');
//近期发表回复的用户回复得分
$users_reply_score_query = DB::table('replies')
->select(DB::raw("user_id, count(*)*$this->reply_weight as score"))
->where('created_at', '>=', Carbon::now()->subDays($this->pass_days))
->groupBy('user_id');
//用户的话题和回复得分的联合
$users_topic_reply_score_query = $users_topic_score_query->unionAll($users_reply_score_query);
//总得分最高的前6个用户的id
$users_score_query = DB::table(DB::raw("({$users_topic_reply_score_query->toSql()}) as users_score"))
->selectRaw("user_id, sum(score) as score")
->groupBy('user_id')
->orderBy('score', 'desc')
->limit(6);
//总得分最高的前6个用户
$active_users_query = DB::table(DB::raw("({$users_score_query->toSql()}) as users_score"))
->join('users', 'users.id', '=', 'users_score.user_id')
->select("users.*")
->mergeBindings($users_topic_reply_score_query);
return $active_users_query->get();
}
}通过调试发现教程中的代码用时在 200-300ms,优化后的两种方法运行用时 20-50ms。效果还是蛮显著的,不过很奇怪的是查询构造器比纯 sql 竟然表现还要好一些。
写使用查询构造器的方法时花了好多时间,有些内容在文档上也没有描述(比如:DB::table(DB::raw("({$query->toSql()}) as xxx")) ->mergeBindings($users_topic_reply_score_query)),借助谷歌终于还是写好了,这个过程帮助我加深了对查询构造器的理解。
本帖已被设为精华帖!
本帖由系统于 6年前 自动加精
































 关于 LearnKu
关于 LearnKu




推荐文章: