



->select(DB::raw('count(id)'))加上这个也不行的


查看了下源码,是不可以的,代码中直接写死了count(*)
//Illuminate\Database\Eloquent\Relations\Relation
public function getRelationExistenceCountQuery(Builder $query, Builder $parentQuery)
{
return $this->getRelationExistenceQuery(
$query, $parentQuery, new Expression('count(*)')
)->setBindings([], 'select');
}
可以看看官方文档 https://dev.mysql.com/doc/refman/8.0/en/gr...
InnoDB handles SELECT COUNT(*) and SELECT COUNT(1) operations in the same way. There is no performance difference.
For MyISAM tables, COUNT(*) is optimized to return very quickly if the SELECT retrieves from one table, no other columns are retrieved, and there is no WHERE clause.
对于 InnoDB 来说,COUNT(*) 和 COUNT(1) 是完全一致的,并没有什么不同
对于 MyISAM 来说,如果没有带上 WHERE 语句,则会非常快的返回结果,比如:
mysql> SELECT COUNT(*) FROM student;这种优化也仅仅适用于 MyISAM,因为这种存储引擎存储了精确的行数。
个人经验而言,我认为是没有什么差别的
count(*), count(1), count(id)



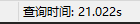

简单的count(*)应该不会花这么多时间吧 ,可能你的是InnoDB 因为stackoverflow上有人是这么说的 COUNT() with InnoDB is slower than COUNT(ID) because InnoDB doesn’t cache the row count. :joy:我没验证过就是了。我在MyISAM下测试的结果:加上where,count() ,count(1)和count(索引字段) 是一样的速度,where条件有索引也比没索引快,count(id)跟其他没索引的字段一样慢,count一个空字段就更慢了。所以我想还是 count( *),再给where字段加合适的索引



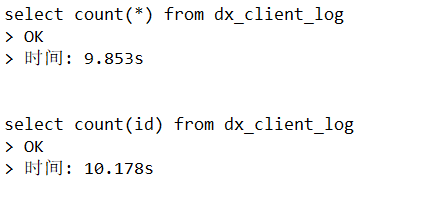



同感,我10万条的一个测试表,有个字段是json,大概50kB一个json,count(*)要十多秒。。。后来删掉这个json字段分其他表存储之后,count(*)只需要最多30毫秒,芜湖起飞!
(count(*)的SQL执行倒是不慢,但是模型加载会很慢)

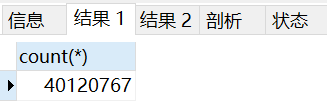
没区别呀 他们命中的 rows 都是相同数量
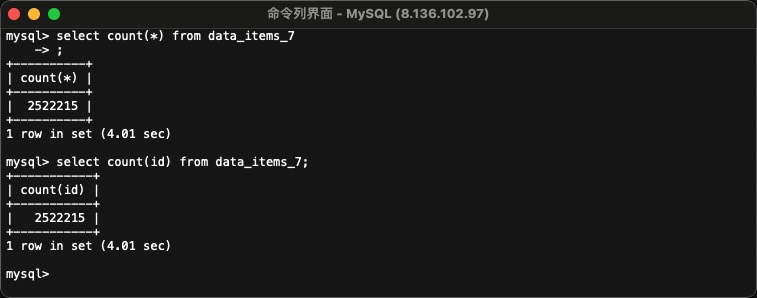
select count(*)
select count(id)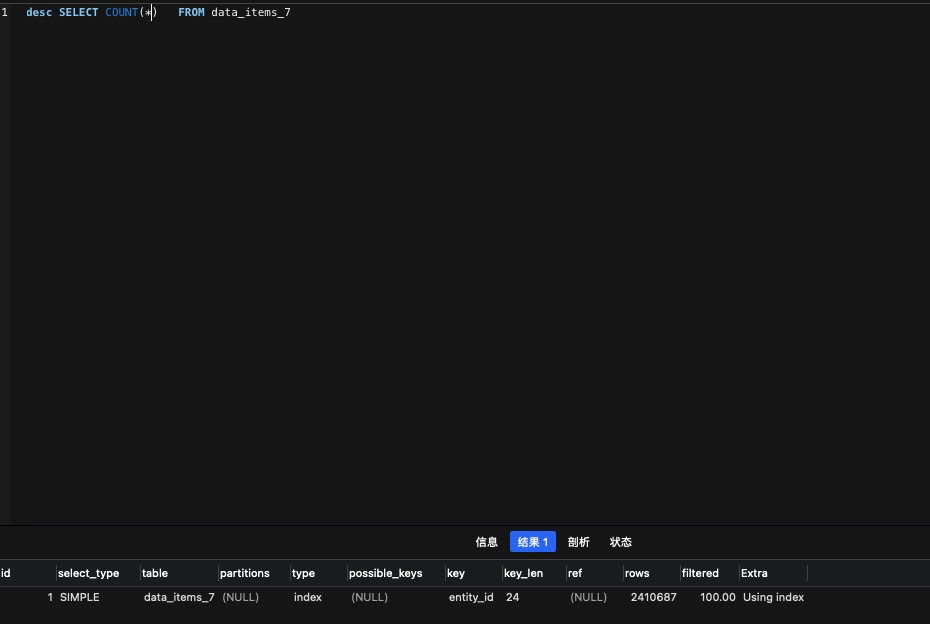
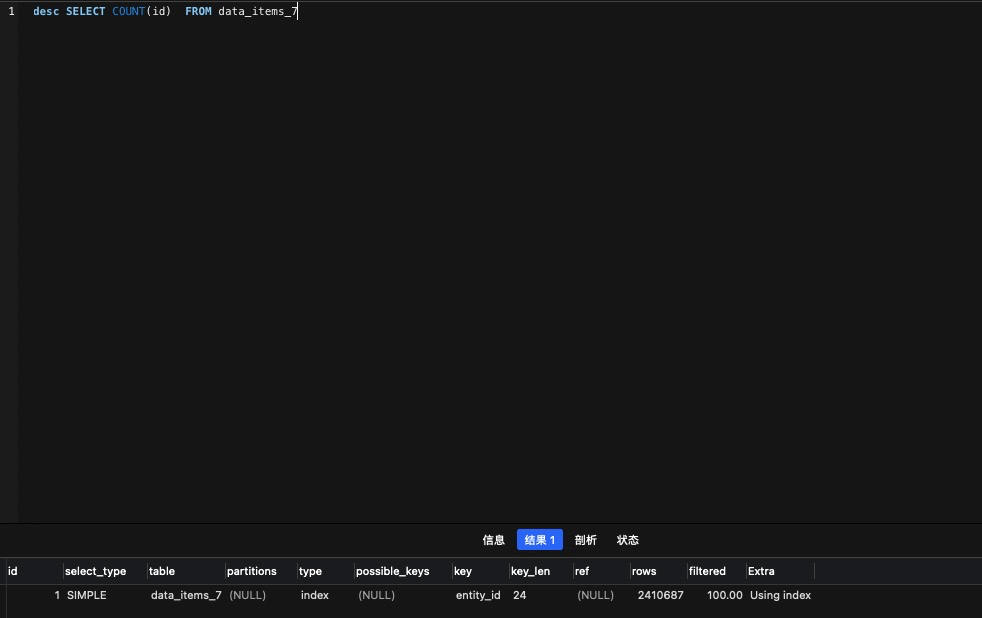
实查效率也没有区别200W的表





 关于 LearnKu
关于 LearnKu




推荐文章: