
我是如何使用 Laravel 来构建一个网站监控 SAAS 产品的
简介
嗨,大家好!这是我的第一篇文章,所以可能写的不是很完美 😇。
差不多在一年前,我决定建立一个用来监测网站正常运行的服务,这个决定导致了 pingr.io 的诞生。
它是一个网络应用,可以持续检查你的 URL 状态码是否正确响应为 200。当然,也可以检查其它状态码。
这个想法是非常简单直接的。你可能会认为这又不难,毕竟只是一个 HTTP 请求。
但它花了我一年的时间。😱
在本文中,我想描述一下它的工作原理。
在开始前我想说明一下,我不认为这个应用的架构设计是符合标准的。
因为这个架构对我而言是在某种程度上、尽快推出产品和设计优秀架构之间的折中选择。
我不想再花一年的时间让它变得很完美,因为在开发的过程中很难保持动力。
我很想听听哪些地方可以改进,哪些地方我做得有问题。
让我们一起潜心研究吧。
要求
乍一看,发出一个 HTTP 请求似乎是一件很容易的事情。然而,服务做什么、怎么做应该有很多要求。
比如:
- URL 应该从分布在世界各地的多个节点进行检查
- 最小检查频率为1分钟
- 应该可以添加新的节点
- 每个节点每分钟都应该发出相当数量的 HTTP 请求。一开始,我还能接受 500-1000 个。但当用户数量增长时,可能会更多
- 除了 HTTP 检查,还应该检查 SSL 证书(是否有效/即将到期等)
- 显示 URL 状态的 UI 应该实时更新
- 根据用户的选择,应通过不同的方式通知用户正常运行时间/停机时间的事件
VPS 提供商和服务器
我认为,如果你想让你的产品尽快投入运行,支付一些的服务费是可以接受的。
所以我尝试了 ScaleWay 和 Digital Ocean ,但最终还是把我所有的服务器移到了Digital Ocean ,因为我更喜欢它。
我拥有的VPS:
- 使用 MySQL 的 Ubuntu . 3 GB / 1 vCPU
- 5个位于世界不同地区的 Ubuntu VPS . 3 GB / 1 vCPU
- 主要核心服务器的 Ubuntu VPS . 4 GB / 2 vCPUs
- Redis 数据库: 1 GB RAM / 1vCPU
关于 MySQL 。 一开始,我使用了他们的 RDS 用作数据库,而且一切都很顺利。 但是,当我无法修改 my.cnf 时, 并且我喜欢拥有所有文件权限,至少在我刚开始学习的时候。
所以,我决定只使用安装了 MySQL 的 VPS,因为它可以给我更多的控制权。
为什么要安装 MySQL?我不知道。我只用过这个数据库。
为什么是 Ubuntu?我也不知道。我只在这个操作系统上工作过。😝
我使用到的技术
- Laravel ,用于后端开发
- VueJS,用于前端开发
- MySQL
- Redis,用来处理队列
- Guzzle库,用于 CURL 请求
- Supervisord,保持 worker 的正常运行
- …
- 从中获得收益!
artisan 命令列表
当我在写这篇文章的时候, 我觉得如果我在这里列出所有使用到的 Laravel 命令可能对你们会有很大帮助:
php artisan monitor:run-uptime-checks {--frequency=1}- 用于调度任务正常运行时间的检查,通过 cron 每分钟运行一次。php artisan checks:push- 从本地 Redis 数据库中获取结果存入临时的 MySQL 表中。由 Supervisord 不间断运行。php artisan checks: pull- 从临时的 MySQL 表中获取结果,并计算监控状态/正常运行时间/其他索引。由 Supervisord 不间断运行。
节点是如何工作的
这是本篇文章最重要的部分之一,它描述了单个节点的工作原理。
I should note that I have a Monitor entity, representing a URL that should be checked.
Getting monitors ready for uptime check
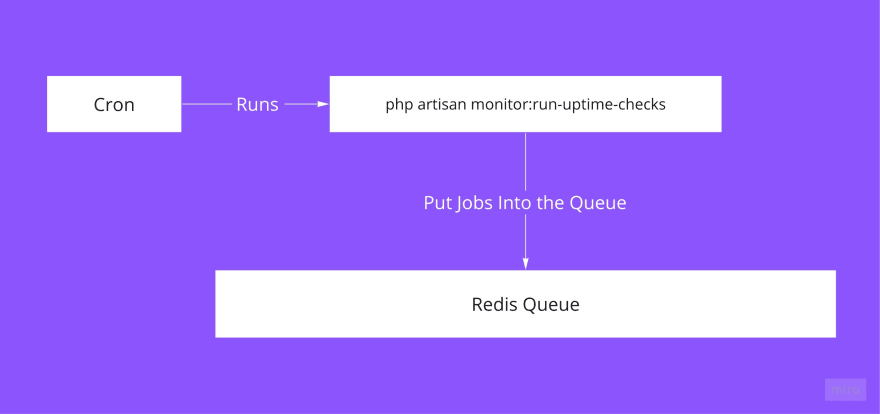
The php artisan monitor:run-uptime-checks command fetches monitors from the database based on some conditions.
One of the requirements is uptime check frequency, which means how often we should check the monitor. Not every user wants to check their sites every minute.
Then, using Laravel scheduling mechanisim, it’s easy to setup running this command with different frequencies.
Passing frequency as an argument helps me to get only the monitors I need to check, depending on what frequency the user has set.
// In the RunUptimeChecks command, we fetch monitors by frequency specified by the user
$schedule->command(RunUptimeChecks::class, ['--frequency=1'])
->everyMinute();
$schedule->command(RunUptimeChecks::class, ['--frequency=5'])
->everyFiveMinutes();
$schedule->command(RunUptimeChecks::class, ['--frequency=10'])
->everyTenMinutes();
$schedule->command(RunUptimeChecks::class, ['--frequency=15'])
->everyFifteenMinutes();
$schedule->command(RunUptimeChecks::class, ['--frequency=30'])
->everyThirtyMinutes();
$schedule->command(RunUptimeChecks::class, ['--frequency=60'])
->hourly();
Filling up the queue
Then I put the uptime check jobs into the Redis queue for every monitor I have. This is what happens in RunUptimeChecks command:
foreach ($monitors as $monitor) {
RunUptimeCheck::dispatch(
(object) $monitor->toArray(),
$node->id
);
}
👉 You may notice here something strange: (object) $monitor->toArray().
At first, I passed the Monitor model to the job. However, there is a significant difference: when you pass a model to a job, it stores just a model id in the queue. Then, when the job is being executed, Laravel connects to the database to fetch the model, which resulted in hundreds of unnecessary connections.
This is why I passed an object instead of the actual model, which serialized quite well.
Another possible approach is removing the SerializesModels trait from the job, which also might work, but I haven’t tried that.
So after this operation, we have some number of jobs in the queue ready to be executed.
Running uptime checks
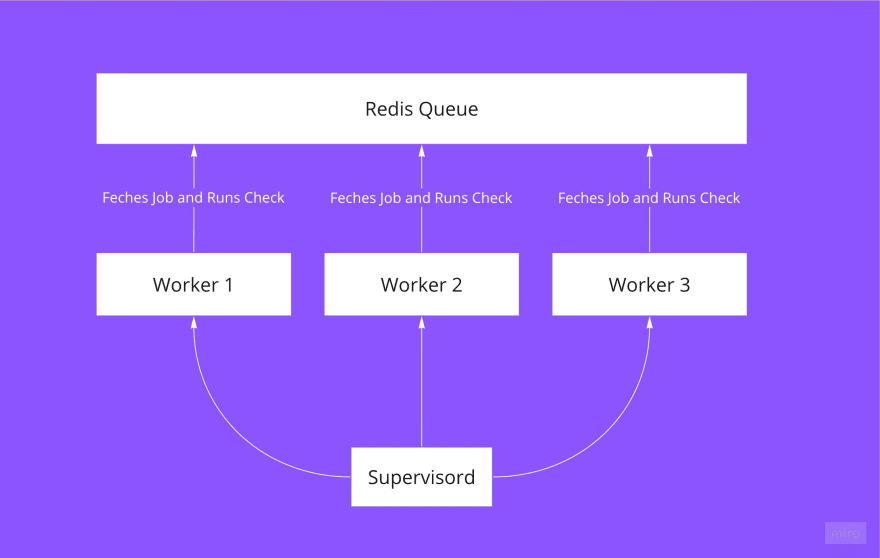
To execute the jobs, we need to run the php artisan queue:work command.
What we also need is:
- Many instances of the command running, because we need to do as many checks as we can per minute
- If the command fails, we need to revoke it and run again.
For this purpose, I used Supervisord.
What it does is it spawns N number of PHP processes, every process is queue:work command. If it fails, Supervisord will rerun it.
Depending on VPS Memory and CPU cores, we might vary the number of processes. Thus, we can increase the number of uptime checks performed per minute.
Storing the temporary result

Now, after we ran a check, we need to store it somewhere.
First, I store the check result in the local Redis database.
Since there might be many processes that continuously push data to the queue, it fits perfectly for this purpose, since Redis is an in-memory database and is very fast.
Then I have another command php artisan checks:push that fetches the checks from the Redis database and does the batch insert into the raw_checks MySQL table.
So I got two tables: monitor_checks and raw_checks. The first one contains the latest successful check of a monitor and all of its failed checks. I do not store every check of every node per minute, since it’ll result in billions of records and it doesn’t provide much value for end-users.
The raw_checks table serves as a bridge between the core server and all nodes servers.
After each check we need to do a lot of stuff:
- Recalculate uptime of every node
- Recalculate the average response time of every node
- Recalculate monitors uptime/response time based on nodes info
- Send notifications if needed
It would be much more reasonable to fetch many checks at once and do all calculations on a server located close to the MySQL server.
For example, the connection between the Indian node and the MySQL server located in Germany is relatively slow.
So the aim is to make the nodes as independent as they can be.
All they do regarding MySQL connection is: fetch monitors which should be checked & store results of checks. That’s it.
How the core server works
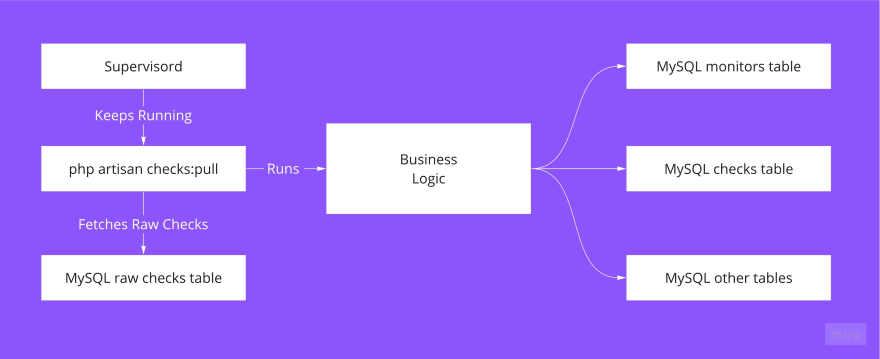
At the core server, I run the php artisan:checks-pull command, which behaves like a daemon: it has an infinite loop that fetches checks from the raw_checks table and calculates such things as average uptime, response time, and some others.
Apart from that, it is responsible for queueing jobs for downtime notifications.
That’s actually it: we have monitors with updated status, uptime & response time attributes.
Updating realtime data
In order to update monitor status on the web app, I use Pusher and Laravel’s broadcasting feature.
So the setup is straightforward.
php artisan checks:pullgets a check from the raw table, sees if the monitor is online, and if it’s not, it fires theMonitorOfflineevent, which is broadcasted using Pusher.Web app sees the new event from Pushed and marks the monitor as offline
To sum up
So, to sum up:
- Every node has a cron job, which fetches the monitor list and put the uptime check jobs into the local Redis queue
- A lot of threads ran by Supevrisord check the queue and make the HTTP requests
- The result is stored in Redis
- Then bunch of checks stored in local Redis moved to the raw checks table in the MySQL server
- The core server fetches the checks and do the calculations.
Every node has the same mechanism. Now, having a constant stream of checks from the raw table, the core server can do many things like calculated average response time from a node, etc.
If I want to extend the number of nodes, I’ll just clone the node server, do some small configuration, and that’s it.
What didn’t work
At first, I stored ALL checks in the database. Both failed and successful. It resulted in billions of records. But users mostly don’t need it. Now instead, I have an aggregation table which stores uptime and response time by an hour
At first, the uptime check job did all the logic itself: I didn’t have any temporary/bridge databases. So it connected to the MySQL server, calculated new uptime etc. Which immediately didn’t work as soon as the number of monitors increased up to ~100. Because every check job did maybe 10-20 queries. 10-20 queries * 5 nodes * 100 monitors. So yeah, it wasn’t scalable at all
Using a dedicated Redis server instead of the
raw_checkstable. Since the raw checks table behaves like a cache, it might be reasonable to consider using Redis for this purpose. But for some reason, I kept losing checks data.
I tried both the sub/pub features of Redis and just storing the data. So I gave up and used a mechanism that is familiar for me: MySQL.
Also, I think I’ve read somewhere that Redis is not the best solution if we need 100% confidence in storing data.
Why did it take so long?
Because of multiple factors.
- I work at a full-time job, so I could work only in the evenings.
- I haven’t had such experience before. Every project is a unique one.
- I had some psychological problems which I’ve described in this article
- I’ve checked many different ways of making this work with a high number of monitors. So I was kind of rebuilding the same thing many times
- Take into account that I also built a UI and did everything alone.
本文中的所有译文仅用于学习和交流目的,转载请务必注明文章译者、出处、和本文链接
我们的翻译工作遵照 CC 协议,如果我们的工作有侵犯到您的权益,请及时联系我们。





















 关于 LearnKu
关于 LearnKu




推荐文章: