


讨论数量:

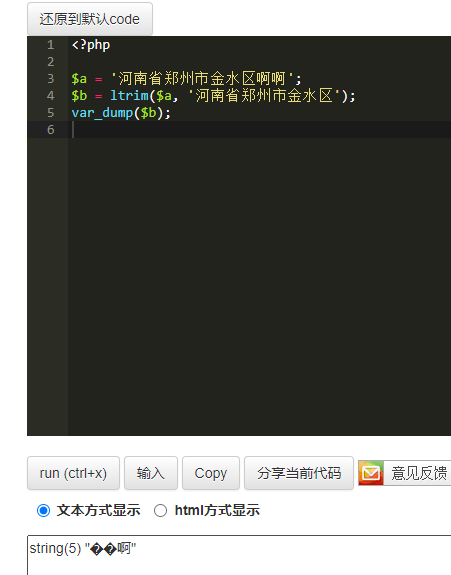
str_replace('河南省郑州市金水区','','河南省郑州市金水区啊啊')


仔细审题呀兄弟,我也能列出 N 种替代方案,但是发出此贴主要还是想知道为什么 ltrim 会出错。@yema


受 @dengminfeng 启发,将 区 与 啊 转换为 字节 后,得出 区 为 0xe5 0x8c 0xba 三字节组成,而 啊 则是由 0xe5 0x95 0x8a 组成,由于有共同的 0xe5,所以会多除去一个字节,导致乱码。
同时发现,所有中文字符的第一字节均为 0xe5 或 0xe6,所以 "区" 后无论跟任何中文字符,都会多除去一个字节。





 关于 LearnKu
关于 LearnKu




推荐文章: