
讨论个问题!微信朋友圈的数据库是怎么设计的?
抱歉各位,是我提的问题有问题,我应该提的详细点,这样的讨论太片面了。我觉得就讨论一个点吧!
比如我发了一个朋友圈,部分人可见,评论点赞好友之间可见(我的好友之间非好友不可见),朋友的朋友圈及时获取所有好友动态。简单的数据存储肯定是不难,难的是如何高效获取数据,数据如何存储?看到的相关方案说什么链表存储,其实想讨论的就是这个数据怎么存储相关数据关系。


















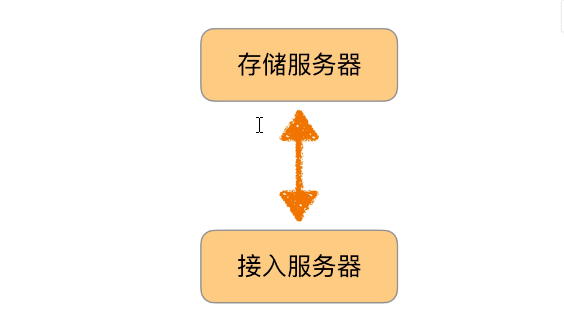
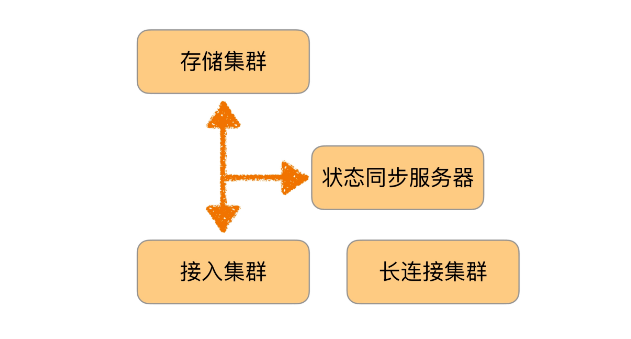
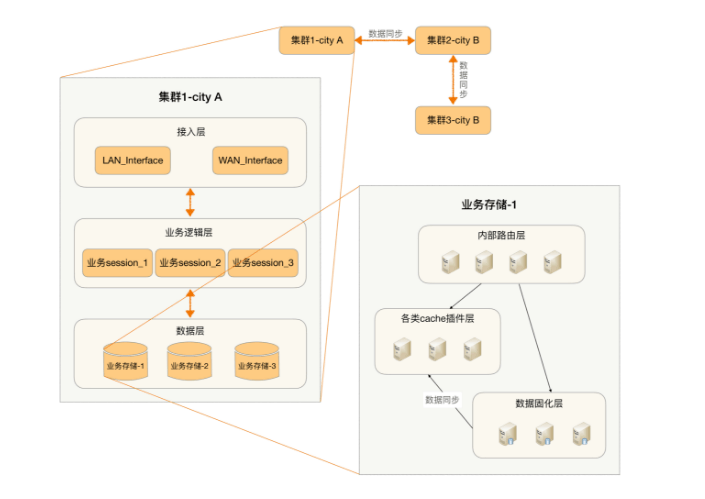 通信架构:
通信架构: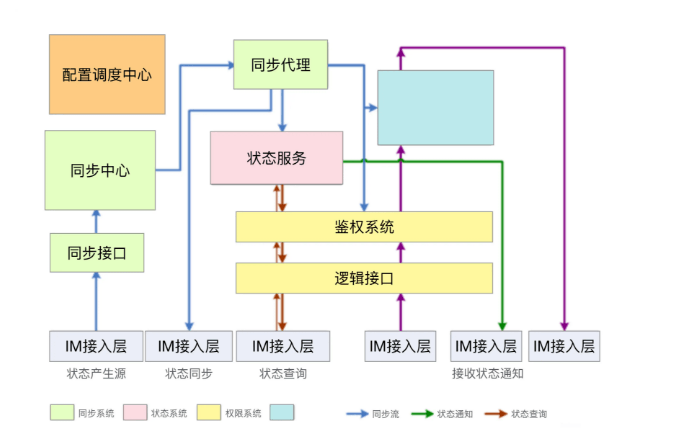 参考文献:《QQ 1.4 亿在线背后的故事》
参考文献:《QQ 1.4 亿在线背后的故事》
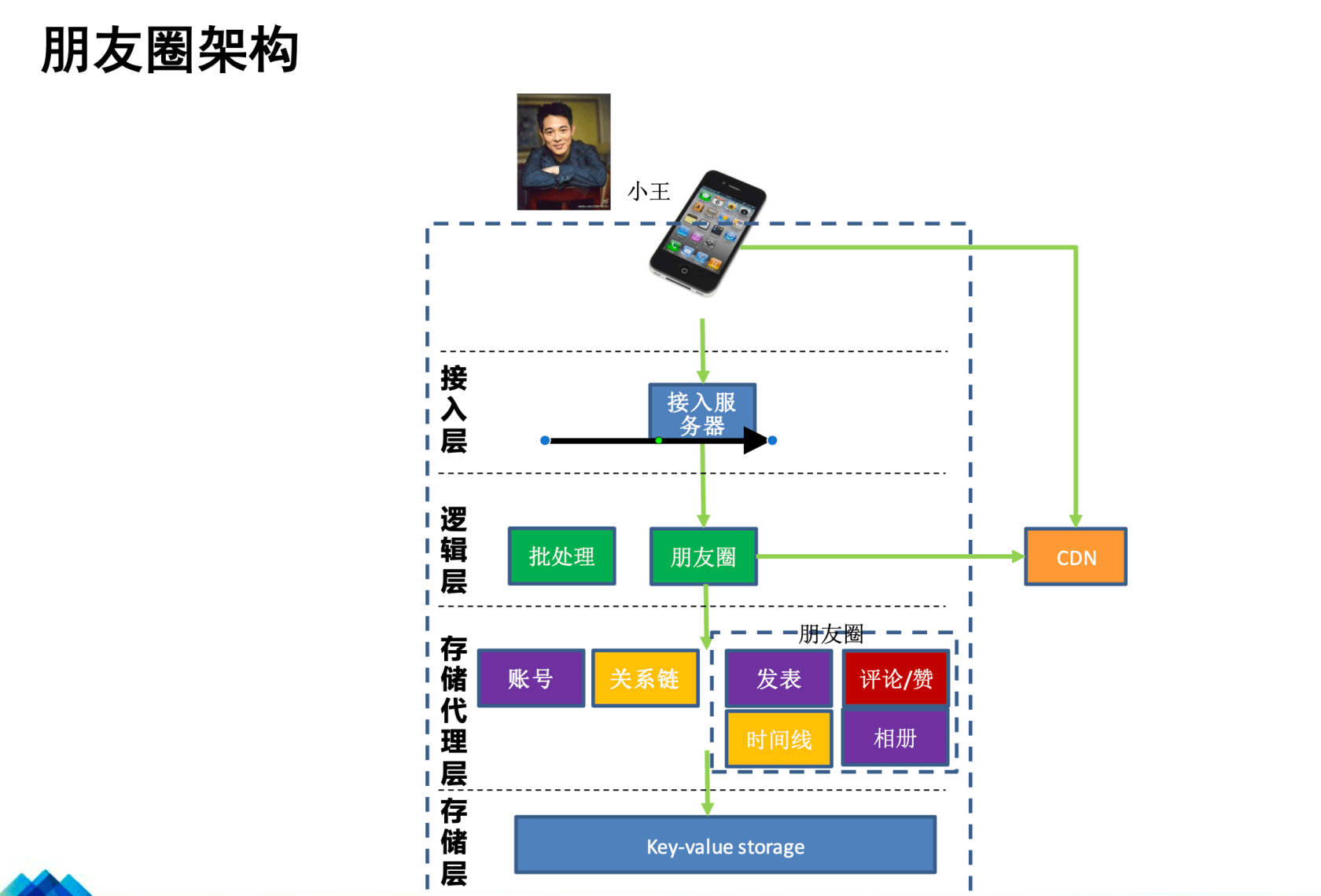
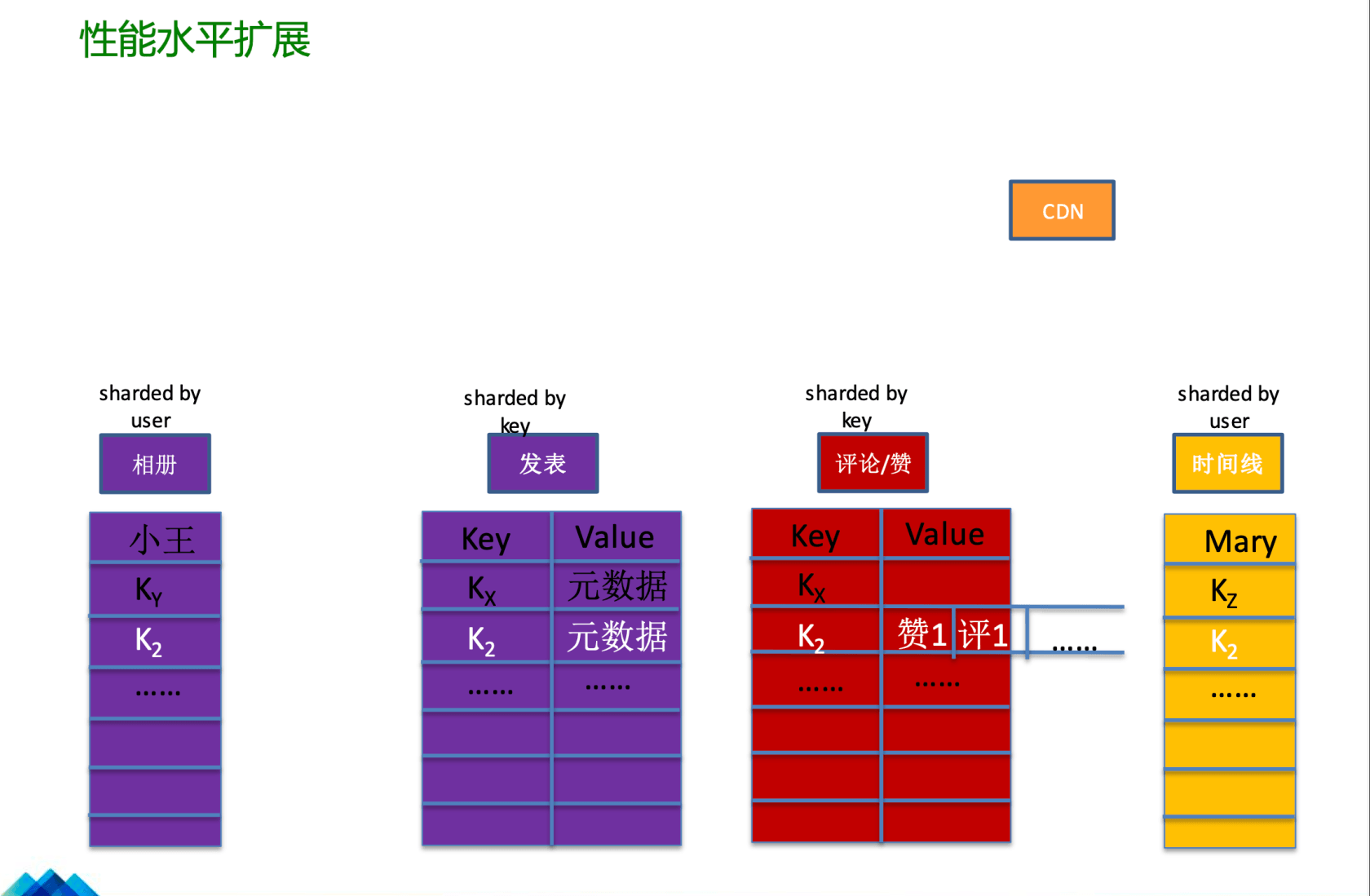
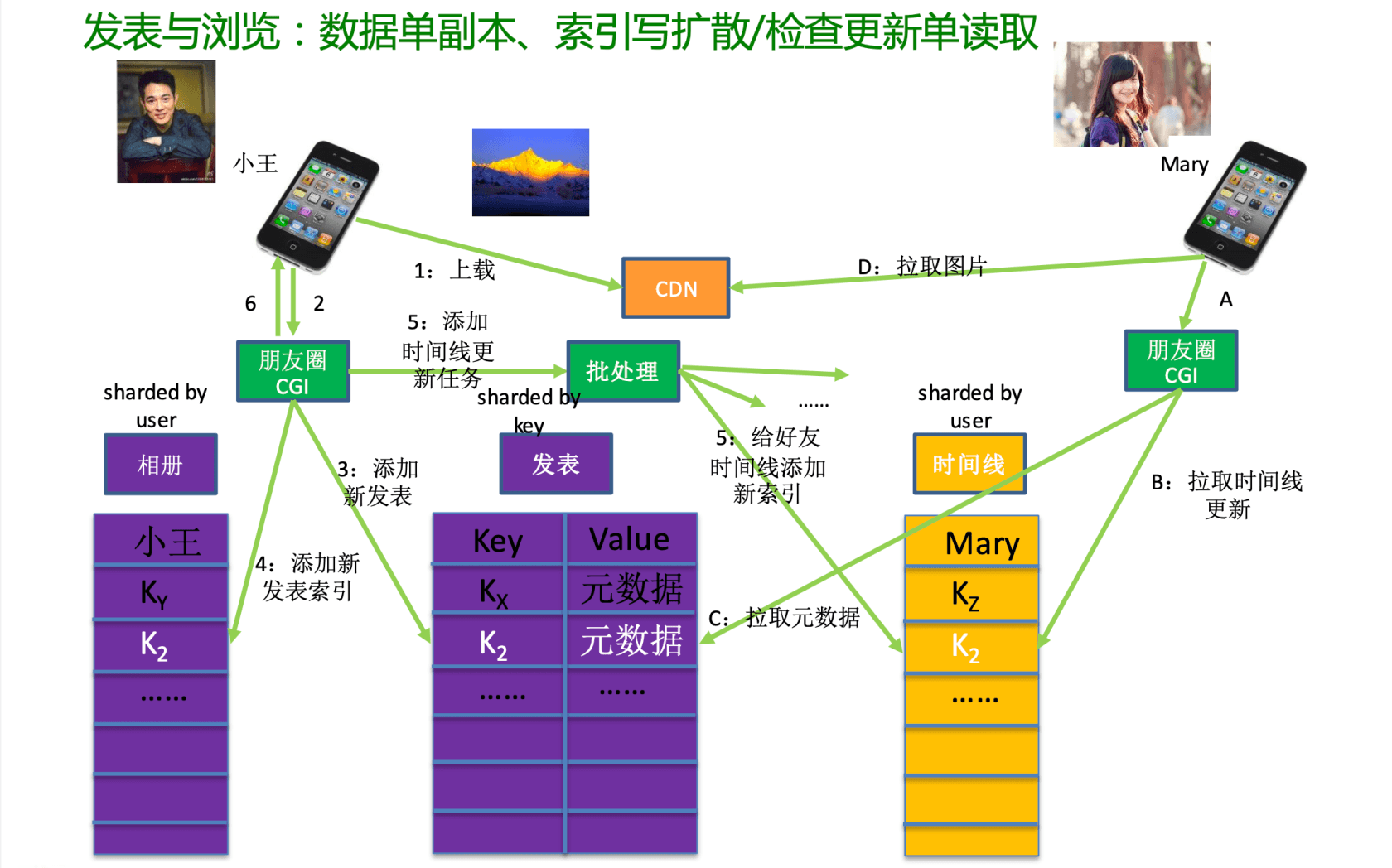
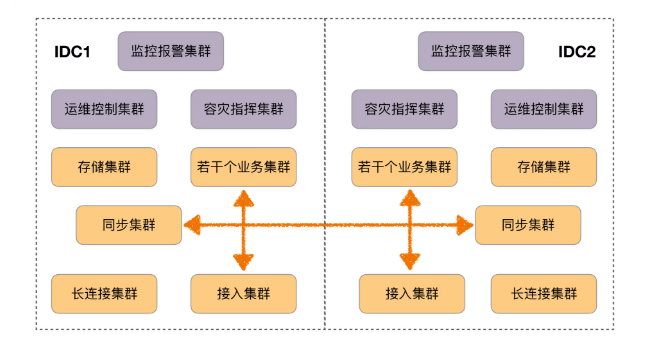
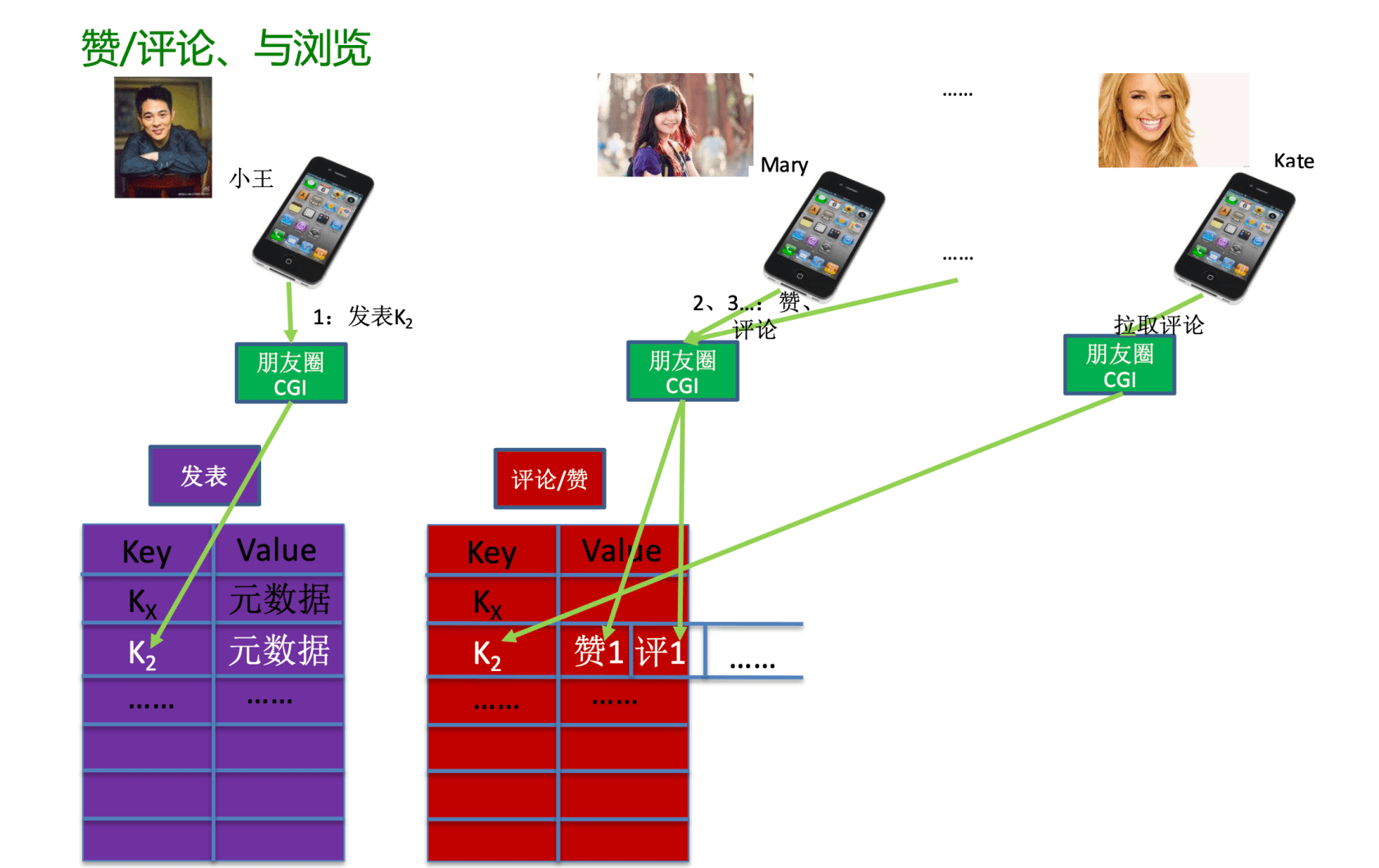 相关的技术架构截图,请参考
相关的技术架构截图,请参考




 关于 LearnKu
关于 LearnKu




推荐文章: