





这样的项目我做过,我来说一下吧,现在我们需要假设一个前提,就是你的无限级,实际可能会最多有多少级,这个假设要有个度,你不要动不动就说,我有几万级、几十万级,脱离了实际的问题,谈解决没有意义。
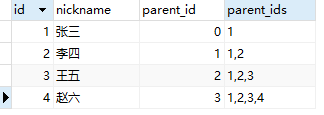
说一下以前我做的无限级项目,那项目以前就是采用上面的人说的,每人存了自己上级的所有id,类似1,2,3,4这样存的,查询是使用到了find_in_set来查的,我们一开始,实际数据级数也就10级以下,跑起来还好,后面过了两三年,多的已经有接近100级了,这时候我发现,很多业务,会频繁出现慢查询了,我们那时候也挺烦恼的。
后面我们改了一下,把用户关系,不在使用1,2,3,4这样存储父级关系,我们采用了左右树编码(这里不详细介绍左右树,可以自己百度)来存用户关系,左右树的关系设计,在关系查询的时候,比逗号隔开的时候,是有非常大的区别和提升的,但是这个数据结构,难点不在于查询,而在于移动、删除节点的操作,还好我们项目删除节点也不是特别频繁吧,然后更新的话,有索引,批量更新左右值,也勉强能接受,反正主要是解决查询速度问题就好了。



我也不知道...






也不是不可以 ,可以试试下面的思路
CREATE TABLE `teamlevel` (
`Id` bigint(20) NOT NULL,
`UserId` varchar(50) DEFAULT NULL COMMENT '用户Id',
`ParentId` varchar(50) DEFAULT NULL COMMENT '推荐人Id',
`Level` int(10) DEFAULT NULL COMMENT '层级',
PRIMARY KEY (`Id`)
)把用户上面的所有上级都展开存,如图
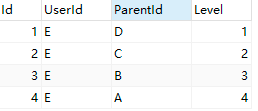 查A的所有下级
查A的所有下级
select UserId from teamlevel where ParentId=A这样存可以查指定的第级,但是实时查数据量大了后还是有很大挑战的。
这样的项目我做过,我来说一下吧,现在我们需要假设一个前提,就是你的无限级,实际可能会最多有多少级,这个假设要有个度,你不要动不动就说,我有几万级、几十万级,脱离了实际的问题,谈解决没有意义。
说一下以前我做的无限级项目,那项目以前就是采用上面的人说的,每人存了自己上级的所有id,类似1,2,3,4这样存的,查询是使用到了find_in_set来查的,我们一开始,实际数据级数也就10级以下,跑起来还好,后面过了两三年,多的已经有接近100级了,这时候我发现,很多业务,会频繁出现慢查询了,我们那时候也挺烦恼的。
后面我们改了一下,把用户关系,不在使用1,2,3,4这样存储父级关系,我们采用了左右树编码(这里不详细介绍左右树,可以自己百度)来存用户关系,左右树的关系设计,在关系查询的时候,比逗号隔开的时候,是有非常大的区别和提升的,但是这个数据结构,难点不在于查询,而在于移动、删除节点的操作,还好我们项目删除节点也不是特别频繁吧,然后更新的话,有索引,批量更新左右值,也勉强能接受,反正主要是解决查询速度问题就好了。

关联查询多对多,下级加入成员,找出当前相关的人员,加入当前分销,查询的时候直接in子查询




老铁啊,场景都不要想啊,传销违法,开发相关的系统也同样违法,回头是岸。

上面说的嵌套集合模型是种不错的方式
如果表结构不满足这种方式,可能就要依赖复杂的 SQL 自己来实现这种效果
另外 mysql8 的 with 递归公用表表达式也能实现类似的效果
如果你说的这种表有 100 万以上的数据
建议把统计相关的数据迁移到其他服务, 比如 clickHouse




这种把模型简化出来其实就是N叉树,使用N叉树的遍历就可以实现你说的,表就设计成有 pid 把树的数据结构定义好。

用个字段将所有得上级id全部存储起来,比如pids:1,3,4,5,6,7,在用个pid记录自己得上级 如果想累计团队销售就用find_in_set去查询pids有这个值就ok,这个拆解插入也比较简单 但是数据量大的时候我没尝试过查询时候的速度。


 关于 LearnKu
关于 LearnKu




推荐文章: