
百万级数据导入(hyperf+xlswriter+task+websocket)
128 / 12 / 创建于 3年前 /
 晏南风 的个人博客
晏南风 的个人博客
需要实现的功能:
1、导入excel文件,10w条数据或者更多
2、进行入库操作
可能涉及多张表
需要进行多表数据校验(updateOrCreate)
需要保证多张表数据一致(transaction)
3、前端实时显示入库进度
实现思路:
将数据进行分块然后分配到不同进程进行数数据库导入操作,每个task worker完成后会触发onfinsh方法,监听该事件通过websocket进行进度通知
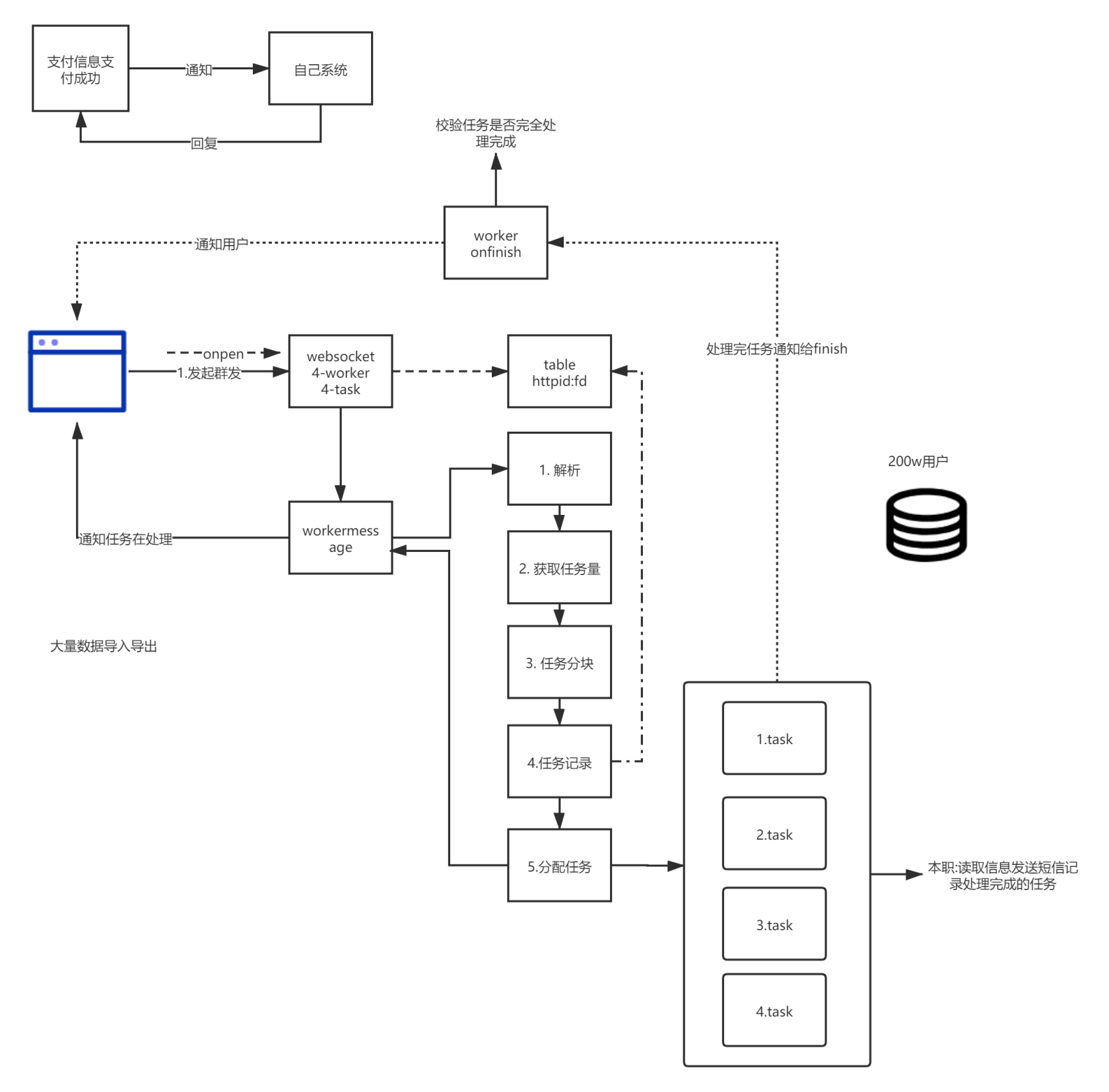
可能遇到的问题:
文件太大了,一下捞到内存,内存会爆炸
数据分块投递进程和进程消费的问题
进程消费完通知的问题
数据库写入阻塞导致导入非常慢
解决方案
1、xlsx的读取分几种模式,全量读取和游标读取,选择游标读取耗费的内存是非常小的,然后可以根据读取数量进行一次处理
while ($res = $this->xlsObj->nextRow($_dataType)) {
$data[] = $res;
$count++;
if ($count % 10000 == 0) {
//回调数据插入的方法
$closure($data);
unset($data);
}
}2、关于进行投递和消费问题,如果在传统fpm项目中,一般会选择消息中间件,先把消息推送到中间件,然后再多进程消费,但是一般投递消息是越小越好,都需要经过序列化处理、然后进程消费在进行反序列化,swoole为我们提供了一套更简单的方案,来看官方说明:

swoole默认进程间通信都是基于unix socket的,他的性能如下:

这样一来和中间件的链接耗时和传输耗时全部可以省掉,投递和消费都是基于内存的无io操作
3、进程消费的时候需要入库,虽然swoole的mysql io 已经全部协程化、因为我这里是多表检验难免需要查询校验后再进行入库,所以这里开了协程并发入库,使用 hyperf utils 里面的 parallel 设置并发数为 10,这样也快很多
4、进程消费完通知的问题我们可以通过监听OnFinish事件,进程导入结束后返回已完成条数和总条数,就可得知进度,让webscoket server 主动向 client 推送进度
实现效果
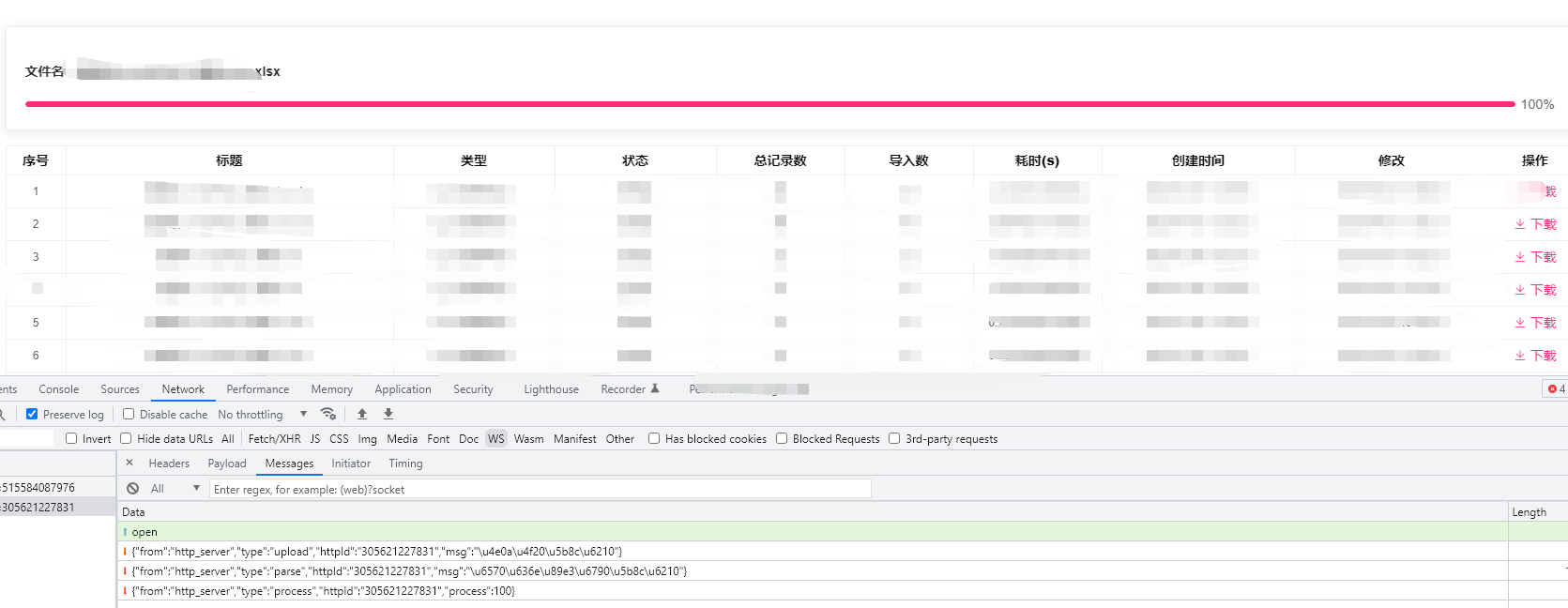
这里没分块是因为我默认是按100分块的,我的表里没那么数据,就没分块
来看看9145条数据cpu的调度率
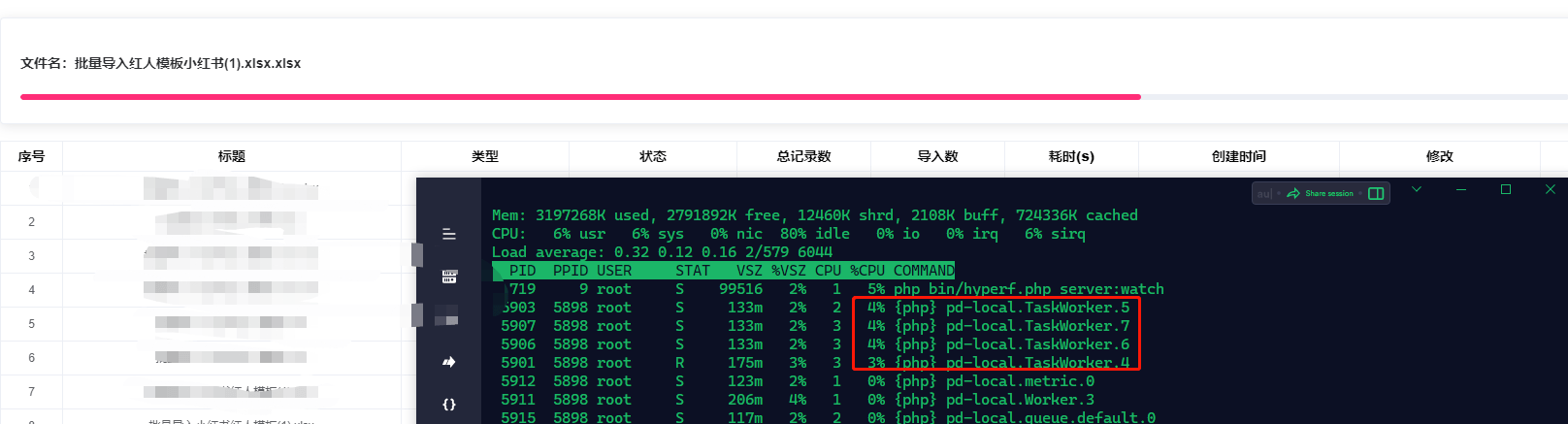
可以看到,因为均分到四个不同task worker 缘故,cpu调用不会只在一个进程上而是在多个进程均衡调度!!
技术栈
- hyperf (swoole框架)
- xlsxwriter (基于c的excel导入导出扩展)
- 多进程投递和消费 (基于swoole task的api调用)
- websocket 实时通信
注意
- 消息队列模式使用操作系统提供的内存队列存储数据,未指定
mssage_queue_key消息队列Key,将使用私有队列,在Server程序终止后会删除消息队列。 - 指定消息队列
Key后Server程序终止后,消息队列中的数据不会删除,因此进程重启后仍然能取到数据
数据分块和验证问题
虽然上面是按1W每次进行Excel文件读取,但是如果对1W条数据直接校验+入库还是很耗时的,这会导致处理时间过长前端进度条不会改变,所以再次进行分块,那么问题来了,代码该怎么写呢
/**
* $data 为 读取到的1W条数据
*/
$chunkSize = $this->config->get('ws.kol_analysis.labor_cost.import.chunkSize');
$chunks = collect($data)->chunk($chunkSize);
$chunks->each(function ($item) {
# 校验数据
$laborCostImportValidation = container()->make(LaborCostImportValidation::class, [$item->all()]);
$list = $laborCostImportValidation->getData();
# 投递数据
$task = container()->get(LaborCostImportTask::class);
$task->handle([
'list' => $list,
// ....
]);
});LaborCostImportValidation 为数据校验类,如是否为空,是否重复等等,这个根据自己的业务进行校验,如果有错误会抛出异常。
LaborCostImportTask 为Task处理类,如果校验通过后会进行任务投递,投递到不同taskWorker进行处理,我这里开了4个taskWorker,虽然是同一份代码,但是是4个进程在执行,投递的数据不用时,进程执行的结果其实也是不用的,所以这就是多进程编程。
乍一看没有什么问题,但是如果某块有异常会出现数据不一致情况
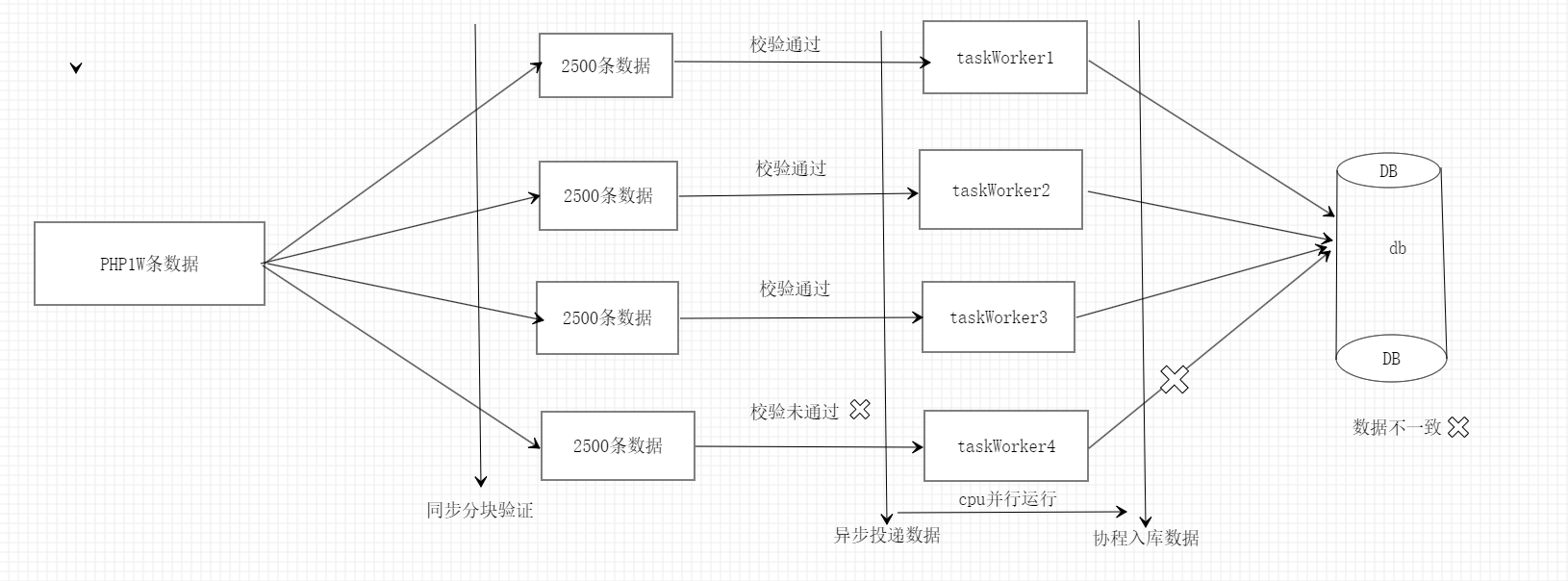
解决方案: 先分块校验再分块入库
try {
# Excel 校验组装
$chunks = $chunks->map(function($item) {
/** @var LaborCostImport $laborCostImport */
$laborCostImport = container()->make(LaborCostImport::class, [$item->all()]);
return $laborCostImport->getData();
});
} catch (\Exception $e) {
$errorMsg = $e->getMessage();
$this->importRecordService->saveInfo(['id' => $importRecordId, 'remark' => $errorMsg]);
throw new BusinessException(StatusCode::ERR_SERVER, $errorMsg);
}
# 任务投递task worker
$chunks->each(function ($item) use ($httpId, $count, $importRecordId) {
$task = container()->get(LaborCostImportTask::class);
$task->handle([
'list' => $item->all(),
'httpId' => $httpId,
'count' => $count,
'importId' => $importRecordId
]);
});本作品采用《CC 协议》,转载必须注明作者和本文链接






























 关于 LearnKu
关于 LearnKu




推荐文章: