






存 省份ID,城市ID,县区ID,同时在修改时把省份城市县区名称做冗余字段{"province_name":"北京","city_name":"北京市","district_name":"朝阳区"}用于展示,既方便检索,有在展示的时候不用关联表获取区域名称,唯一缺点就是区域名称发生变更无法及时更新


用国家统一行政区域划分代码
110110113 每3位拆开。 110北京市110北京市113顺义区
中华人民共和国民政部发布的行政区划代码: www.mca.gov.cn/article/sj/xzqh/202...



uid , uname, 省, 市 ,县


e.g.:
code: 10010
name: 朝阳区
fullname: 北京市朝阳区
parent_code: 100
-----
code: 1001010
name: XXX 街道
fullname: 北京市朝阳区XXX 街道
parent_code: 10010fullname 存 string 或者是结构化数据,取决于你在前端怎么用,如果不需要对每个区域丛单独的处理,例如超链接等,那么直接存 string。



前端、数据库新手,好奇问一下:
1. 这种表结构不行嘛?
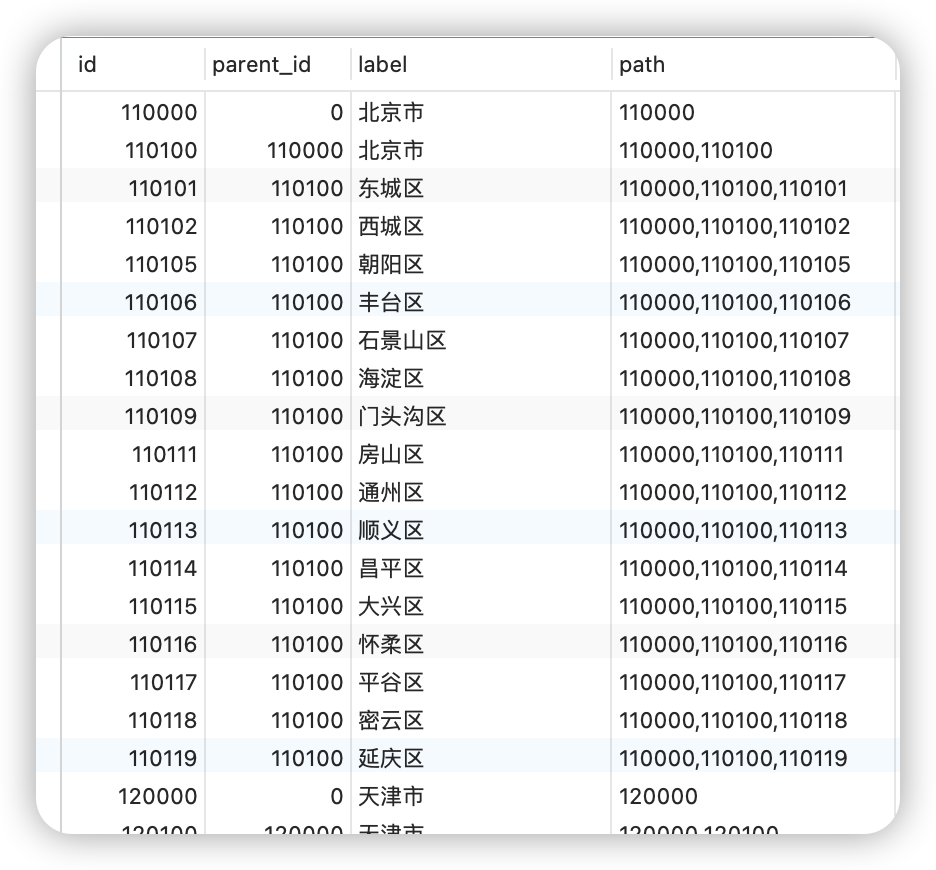
| id | level | name | parent_id | child_id_begin | child_id_end |
|---|---|---|---|---|---|
| 110000000000 | 0 | 北京市 | 0 | 110000000001 | 119999999999 |
| 110100000000 | 1 | 市辖区 | 110000000000 | 110100000001 | 110199999999 |
| 110101000000 | 2 | 东城区 | 110100000000 | 110101000001 | 110101999999 |
| 110102000000 | 2 | 西城区 | 110100000000 | 110102000001 | 110102999999 |
| 110105000000 | 2 | 朝阳区 | 110100000000 | 110105000001 | 110105999999 |
其中,parent_id、child_id_begin、child_id_end 都可自动生成
1.1 查询广东深圳下的所有区
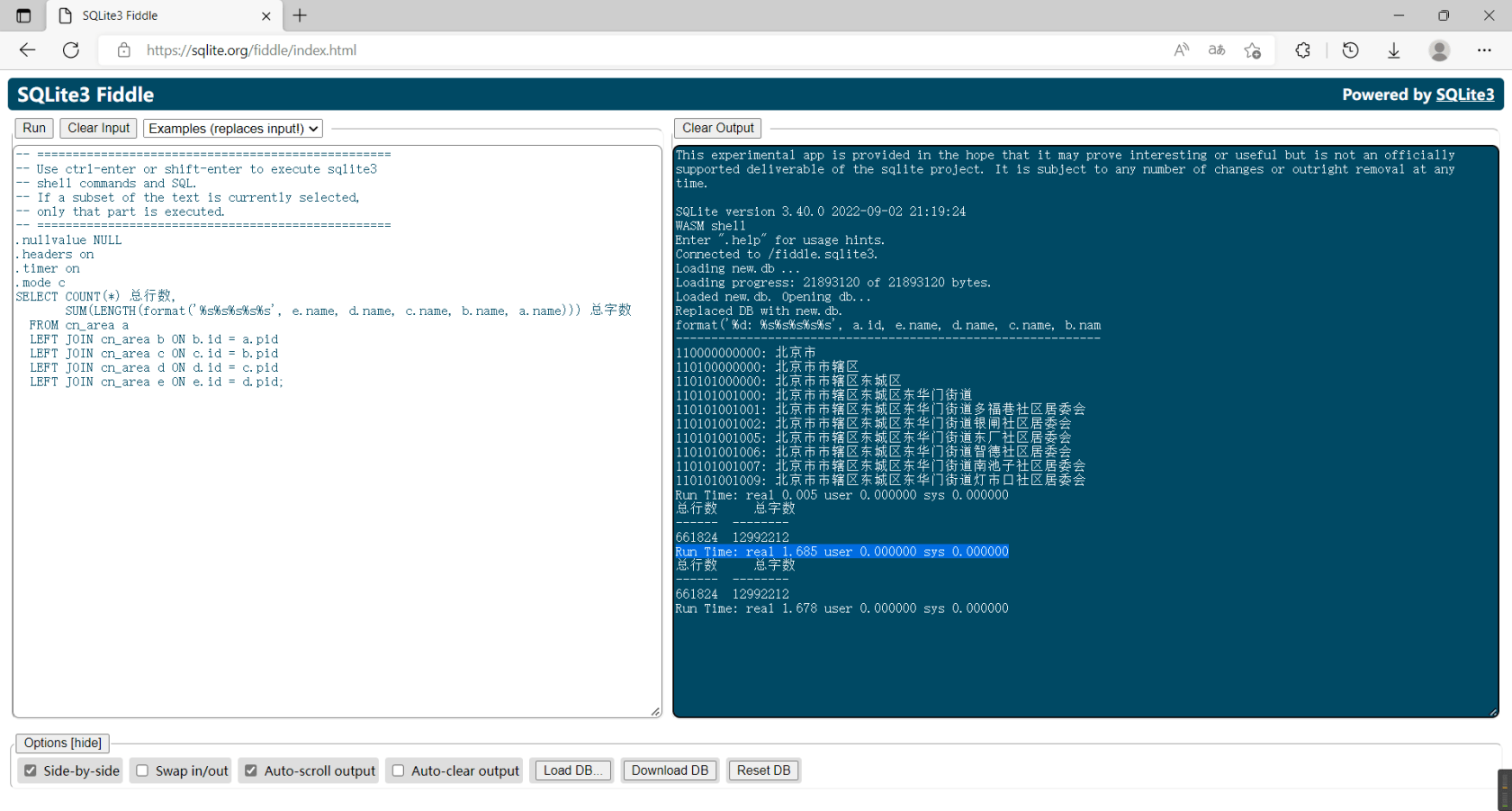
SQLite 代码
SELECT c.id, c.name
FROM cn_area a
JOIN cn_area b ON b.id BETWEEN a.cid_begin AND a.cid_end AND b.level = 1 AND b.name LIKE '%深圳%'
JOIN cn_area c ON c.id BETWEEN b.cid_begin AND b.cid_end AND c.level = 2
WHERE a.level = 0 AND a.name LIKE '%广东%';速度
| 数据库 | 表大小 | 用时 |
|---|---|---|
SQLite |
3640 行,无索引,84 KB | 0.006 秒 |
结果
| id | name |
|---|---|
| 440301000000 | 市辖区 |
| 440303000000 | 罗湖区 |
| 440304000000 | 福田区 |
| 440305000000 | 南山区 |
| 440306000000 | 宝安区 |
| 440307000000 | 龙岗区 |
| 440308000000 | 盐田区 |
| 440309000000 | 龙华区 |
| 440310000000 | 坪山区 |
| 440311000000 | 光明区 |
2. 不能在前端查询数据嘛?
2.1 作为数据库提供
SQLite 有提供 wasm 版,可不依赖后端就能完成查询
整个数据库大小才 84 KB,gzip 压缩后 42 KB,感觉代价不算大?
2.2 作为 json 提供
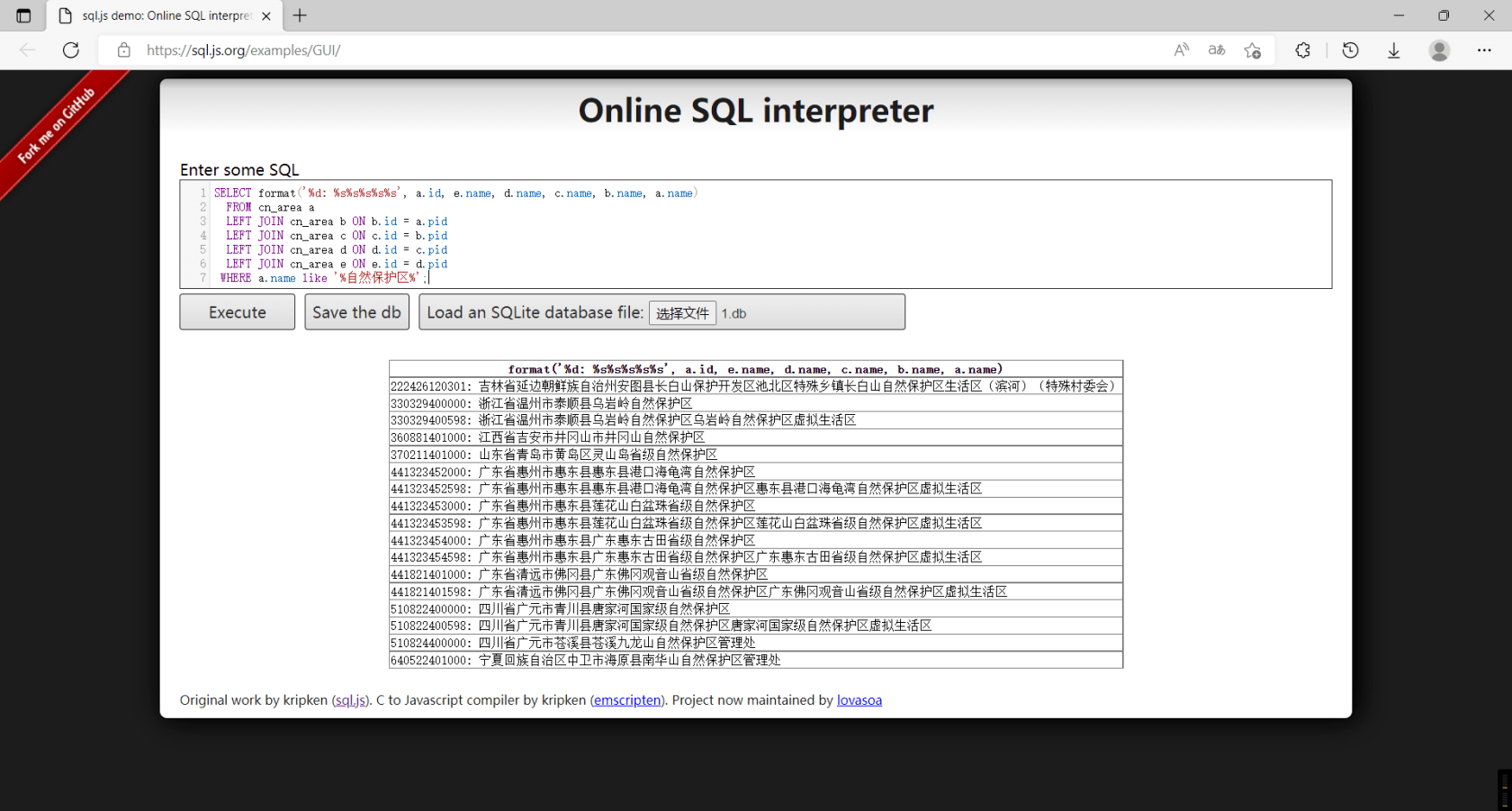
使用以下 SQL:
SELECT json_group_object(format('%d,%s', a.id, a.name),
(SELECT json_group_object(format('%d,%s', b.id, b.name),
(SELECT json_group_object(format('%d,%s', c.id, c.name), json('{}'))
FROM cn_area c
WHERE c.level = 2
AND c.id BETWEEN b.cid_begin AND b.cid_end))
FROM cn_area b
WHERE b.level = 1
AND b.id BETWEEN a.cid_begin AND a.cid_end))
FROM cn_area a
WHERE a.level = 0;输出格式化后的 json(大小:106 KB,gzip 后 27 KB):
{
"110000000000,北京市": {
"110100000000,市辖区": {
"110101000000,东城区": {},
"110102000000,西城区": {},
"110105000000,朝阳区": {},js 查询
Object.entries(data)
.filter(([k]) => k.includes('广东')).flatMap(i => Object.entries(i[1]))
.filter(([k]) => k.includes('深圳')).flatMap(i => Object.entries(i[1]))
.map(([k]) => k.split(','))结果
[
[ '440301000000', '市辖区' ],
[ '440303000000', '罗湖区' ],
[ '440304000000', '福田区' ],
[ '440305000000', '南山区' ],
[ '440306000000', '宝安区' ],
[ '440307000000', '龙岗区' ],
[ '440308000000', '盐田区' ],
[ '440309000000', '龙华区' ],
[ '440310000000', '坪山区' ],
[ '440311000000', '光明区' ]
]

一般存IP在需要的时候再查
@臭鼬 噢,我贴一下如何生成这个 66W 行数据库的备忘。(若你感兴趣,也可花一两分钟试一试)
下载并解压大佬爬好的数据:raw.githubusercontent.com/zhiguang...
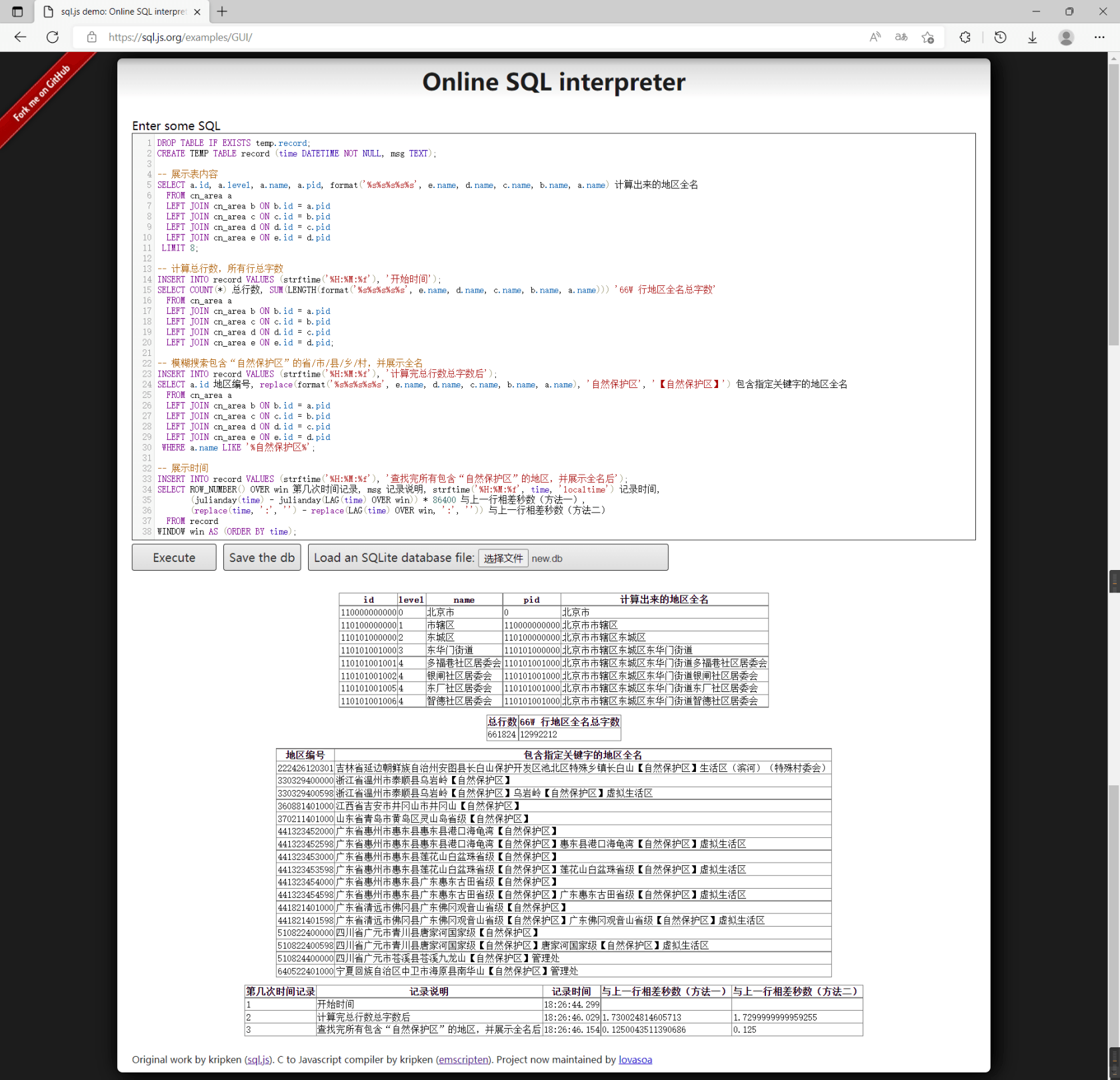
运行下列
SQL,等待几秒钟,即可生成new.db(3 级数据为 84 KB,5 级数据为 16.8 MB):(下面是
bash脚本示例)
#!/bin/bash
sqlite3 :memory: <<'EOF'
-- 采用 UTF-16 存储中文,体积较小
PRAGMA encoding = 'UTF-16';
-- 导入 csv 文件至临时表 t,第一行作为列名
.import --csv 2021-flatten-VILLAGE-data.csv t
-- 建表
CREATE TABLE cn_area (
id INTEGER PRIMARY KEY,
level INT NOT NULL,
name TEXT NOT NULL,
_MASK JSON NOT NULL AS ('[1000000000000,10000000000,100000000,1000000,1000]'),
pid INT NOT NULL AS (id - id % _MASK ->> level),
cid_end INT AS (id + _MASK ->> (level + 1) - 1),
cid_begin INT AS (id + 1)
);
-- 按格式抽取并添加需要的数据
INSERT INTO cn_area (id, level, name)
SELECT CASE WHEN code + 0 > 99 THEN code ELSE code * 10000000000 END,
'{
"PROVINCE": 0,
"CITY": 1,
"COUNTY": 2,
"TOWN": 3,
"VILLAGE": 4
}' ->> ('$.' || level),
name
FROM t
-- 如果只需要 3 级,可以过滤:
-- WHERE level IN ('PROVINCE', 'CITY', 'COUNTY')
;
-- 丢掉临时表
DROP TABLE t;
-- 整理紧实数据库后,写入磁盘
VACUUM INTO 'new.db';
EOF
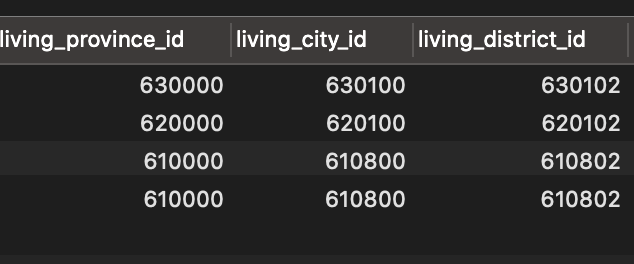
用户表字段。只存一个字段较好,因为北京直辖是没有第三级区级 code 的。
地区文字显示及地名模糊搜索。地区代码表增加全称冗余,如某省某市、某省某市某县。
三级联动。1/不查库,直接缓存全三级数据,或缓存前两级省级地级。2/查库,地区代码表加 level 字段省级1地级2区级3,由上一级向下一级查时,去掉各级的数字位,如省查市以河北为例,前两位13为省级位,like 13% and level = 2,地级查区级以石家庄市为例,前四位为地级,like 1301% and level=3。
由下一级查上一级,如 130102 为例(石家庄市长安区),那么省级 code 为 13+0000,地级 code 为 1301+00,select id,code,level from areas where code in (130102, 130100, 130000) ,再以 level 字段区别三级。

CREATE TABLE `areas` (
`id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`area_id` INT(11) NOT NULL COMMENT '地区id',
`name` VARCHAR(30) NOT NULL COMMENT '地区名称',
`short_name` VARCHAR(20) NOT NULL DEFAULT '' COMMENT '地区简称',
`path` TINYINT(4) NOT NULL DEFAULT '1' COMMENT '路径,省1 市2 区3',
`area_code` VARCHAR(4) NOT NULL COMMENT '区号',
`spell` VARCHAR(50) NOT NULL COMMENT '拼音',
`letter` VARCHAR(15) NOT NULL COMMENT '简拼',
`first_letter` VARCHAR(1) NOT NULL COMMENT '首字母',
`status` TINYINT(4) NOT NULL DEFAULT '1' COMMENT '状态 1-正常 2-禁用',
`parent_id` INT(11) NOT NULL DEFAULT '0' COMMENT '父ID,如果是省份,则父ID为0',
PRIMARY KEY (`id`) USING BTREE,
)
COMMENT='地区表'
COLLATE='utf8mb4_general_ci'
ENGINE=InnoDB;


用MySQL视图可以试试,比如区县视图,包含省市区

懒加载

这个不就是无限分级么 一个表就行 有个关键的uuid与pid就行 uuid pid name

id(自增) code(非重) name(北京) alias_name(京) level (province,city,county,town,) 四级 pid(省默认为0), province_id, province_name, city_id, city_name, county_id, county_name, town_id, town_name, area_path(北京市--北京市--xx区--xx街道--xx)
最后输出的时候 Transformer 遇到 北京市--北京市的这种情况 直接删除一个





 关于 LearnKu
关于 LearnKu




推荐文章: