
使用 Python 和 BeautifulSoup 来做爬虫抓取
互联网上有许多许多的信息使人类穷极一生也无法全部掌握。其实我们需要的不是去访问这些信息而是有一个可扩展的方法去收集,组织并分析这些信息。
这里我们需要网页抓取。
网页抓取会自动的提取数据且按照较为容易理解的格式美化数据。在本教程中,我们将重点介绍网页抓取在金融市场的应用,但是要强调的是网页抓取可以适用于各种情况。
如果你是一位狂热的投资人,获取每日的收盘价格有时候是一个挺累人的事,尤其是你需要获取的信息分布于多个页面。接下来我们将开发一个爬虫,来自动从互联网上抓取这些股票数据。

入门
我们将使用 Python 做为我们的爬取语言,再加上一个简单而强大的库, BeautifulSoup。
- 对于 Mac 用户,Python 已经预先安装在 OS X 中。打开终端并且输入
python --version。你应该看到你的 Python 版本是 2.7.x. - 对于 Windows 用户,请通过官方网站安装 Python。
接下来我们需要使用一个 Python 的包管理工具 pip 来安装 BeautifulSoup 库。
在终端输入:
easy_install pip
pip install BeautifulSoup4注意:如果你执行上面的命令行时失败量,试着增加 sudo 到每一行的前面。
基础
在我们开始进入代码部分前,让我们来了解一下 HTML 的基础以及关于爬取的一些规则。
HTML tags
如果你已经知道了 HTML 标签的含义,并且感觉很轻松的话可以跳过这部分。
<!DOCTYPE html>
<html>
<head>
</head>
<body>
<h1> First Scraping </h1>
<p> Hello World </p>
<body>
</html>这是 HTML 网页最基础的符号。每一个 <tag> 都服务于网页的一块区域:
1. <!DOCTYPE html> : HTML 文档的开头必须以一个文档类型声明开始;
2. HTML 文档被储存在 <html> 标签与 </html> 标签之间;
3. meta 声明与 script 声明必须在 <head> 标签与 </head> 标签之间 ;
4. HTML 文档可见的部分位于 <body> 标签与 </body> 标签之间;
5. 文章的抬头从大到小被定义成 <h1> 到 <h6> 标签;
6. 文章段落被定义成 <p> 标签。
其他有用的标签包括: <a> 用于超链接, <table> 用于表格, <tr> 被表示为表格的行, 以及 <td> 被表示为表格的单元格。
大部分的 HTML 会有 id 或者 class 属性, 每一个 HTML 标签只能有一个 id 属性,并且属性里的数组必须是整个 HTML 文档里唯一的。 class 属性是用来对同一个值的标签进行样式处理。我们可以利用这两个属性来定位我们想要的信息。
更多关于 HTML 标签, id 和 class ,请参阅 W3Schools 的例子。
爬取规则:
- 你需要先看下你爬取网站的使用规则和法律协议,大部分时候,他们都会规范你不能将数据用于违法行为;
- 请控制好抓取的频率,不要把别人的网站整挂了,这是非常没有礼貌的行为,一般被认为是对网站的攻击,最好表现得像一个人类在访问这些数据,最佳实践是一秒钟一个请求;
- 一般情况下,网站的结构会经常改变,所以过一段时间你就需要来检查一次,并在有必要的情况下重写你的代码。
审查页面元素
让我们来以 Bloomberg 报价 网站做为列子。
首先我们需要获取 S&P 500 的数据,在此页面右键调出浏览器菜单,选择『审查元素』:
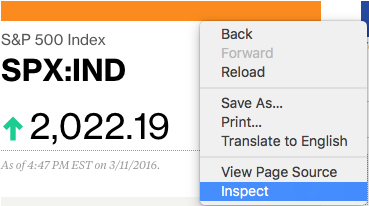
将鼠标移到价格的元素上时,应该可以看到一个小框框,点击后你应该可以看到浏览器控制台的这个元素对应的 HTML 会被选中:
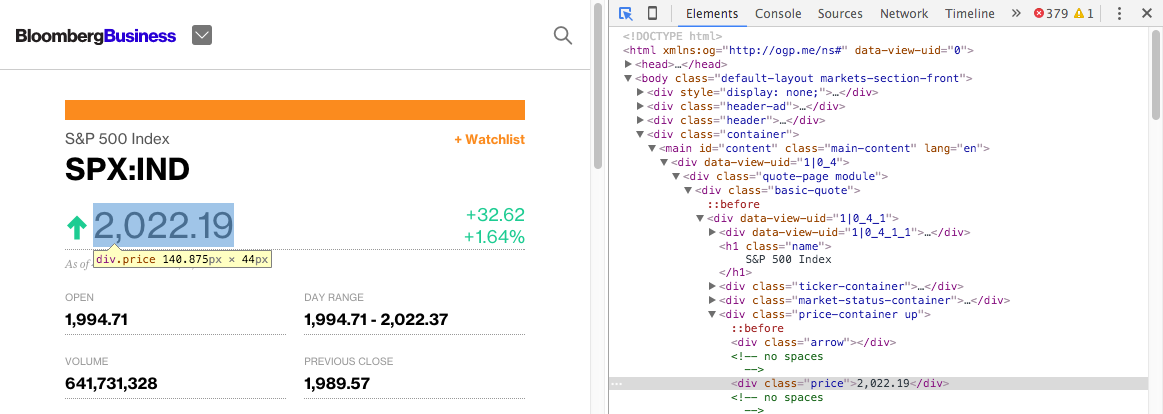
我们可以看到价格在几个层级的 HTML 标签下: <div class="basic-quote"> → <div class="price-container up">→ <div class="price">.
相同的,如果你将鼠标悬浮并点击 "S&P 500 Index" 的话,也可以看到其处于 <div class="basic-quote"> 和 <h1 class="name"> 之中。
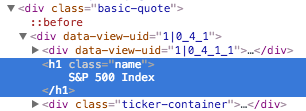
在 class 标签的帮助下,我们很轻松地定位到了我们想要的数据。
开始编写代码
现在我们知道了我们想要的数据所在的位置, 现在就可以编写我们的网络爬虫。 请打开你的文本编辑器!
首先, 我们需要导入即将需要所有的库。
导入所需要的库\ import urllib2\ from bs4 import BeautifulSoup
下一步, 定义一个变量来保存目标网页的 url 。
# 指定 url
quote_page = 'http://www.bloomberg.com/quote/SPX:IND'然后,利用 Python 的 urllib2 库获取上一步指定 url 的 HTML 源码。
# 访问这个网站并且返回这个网站的 html 源码然后保存在 ‘page’ 中
page = urllib2.urlopen(quote_page)最后,将这个 page 变量的内容用 BeautifulSoup 格式化,就可以使用BeautifulSoup 做进一步的处理。
# 使用 beautiful soup 解析这个 html 然后保存在 ‘soup’ 变量中。
soup = BeautifulSoup(page, 'html.parser')现在我们获得了一个 soup 变量,它包含了这个页面的 HTML 源码。 这就是我们开始提取我们所需要的数据的准备工作。
接下来我们可以使用 BeautifulSoup 提供的 find() 方法来定位我们的数据,因为 Class 为 name 的标签在此页面上是唯一的,所以我们可以直接利用 <div class="name"> 来获取我们的数据:
# 获取 Class 对应的标签
name_box = soup.find('h1', attrs={'class': 'name'})一旦我们获取掉标签,我们即可使用 text 方法来获取里面的内容:
name = name_box.text.strip() # strip() 用来移除首尾的空白符
print name同样的,使用以下方法来获取价格:
# 获取价格
price_box = soup.find('div', attrs={'class':'price'})
price = price_box.text
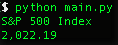
print price当你运行程序时,你应该可以看到 S&P 500 的价格:
导出 Excel CSV 格式
接下来我们需要将收集的数据导出,在导出文档格式选择中,Excel 的 CSV 逗号分隔文档是一个不错的选择,这样你就可以直接通过 Excel 打开并进行简单的数据处理。
不过我们需要先导入 Python 的 CSV 模块,请在你的模块导入区域里加上以下代码:
import csv
from datetime import datetime在代码的最底部,添加以下代码:
# 添加内容,这样就不会替换掉老数据了
with open('index.csv', 'a') as csv_file:
writer = csv.writer(csv_file)
writer.writerow([name, price, datetime.now()])现在当你允许程序时,即可看到一个 index.csv 文件,使用 Excel 打开,即可看到类似的数据:

现在你可以使用这个程序来替你获取 S&P 500 Index 的价格数据了。
更近一步 (高级用户)
多个索引
爬取一个索引对你来说不够过瘾,是吧?我们可以尝试同时提取多个索引。
首先,修改 quote_page 为一个 URL 数组。
quote_page = ['http://www.bloomberg.com/quote/SPX:IND', 'http://www.bloomberg.com/quote/CCMP:IND']接着我们把数据提取码改成 for 循环,它将逐个处理这些URL并将所有数据以元组形式存储到变量 data 中。
# for 循环
data = []
for pg in quote_page:
# 查询网站并将返回的 html 赋值给变量 `page`
page = urllib2.urlopen(pg)# 使用 beautiful soap 解析 html 并存储在变量 `soup` 中。
soup = BeautifulSoup(page, 'html.parser')# 拿出 <div> 标签的 name 并获取它的值
name_box = soup.find('h1', attrs={'class': 'name'})
name = name_box.text.strip() # strip() 用来一处开始和结尾的空白# 获取索引的 price
price_box = soup.find('div', attrs={'class':'price'})
price = price_box.text# 保存数据到元组
data.append((name, price))另外,修改保存部分以逐行保存数据。
# 以添加模式打开一个 csv 文件,这样旧数据会被擦除
with open('index.csv', 'a') as csv_file:
writer = csv.writer(csv_file)
# for 循环
for name, price in data:
writer.writerow([name, price, datetime.now()])重新运行该程序,您应该能够同时提取两个索引!
高级爬取技术
BeautifulSoup 非常简单,非常适合小规模的网页抓取。但是如果您有兴趣更大规模地抓取数据,您应该考虑使用这些其他备选方案:
- Scrapy,一个强大的 Python 爬虫框架
- 尝试将一些公共 API 整合到你的代码中。数据检索的效率远高于页面爬取。例如, 查看一下 Facebook Graph API,这将能帮你获取 Facebook 页面的隐藏数据。
- 当数据量过大的时候,考虑使用类似 MySQL 的数据库后端来存储你的数据。
采用 DRY 方法

DRY 表示 “不要重复你自己”,像 这个人 一样尝试将你的日常工作自动化。一些其他有趣的项目如考虑跟踪你 Facebook 朋友的活跃时间(当然要征得他们的同意),或者抓取论坛的主题列表并尝试一下自然语言处理(这是目前热门的人工智能话题)!
如果您有任何问题,请随时在下面留言。
参考\
http://www.gregreda.com/2013/03/03/web-scr...\
http://www.analyticsvidhya.com/blog/2015/1...
本文中的所有译文仅用于学习和交流目的,转载请务必注明文章译者、出处、和本文链接
我们的翻译工作遵照 CC 协议,如果我们的工作有侵犯到您的权益,请及时联系我们。







 关于 LearnKu
关于 LearnKu




推荐文章: