
Python 爬虫入门问题
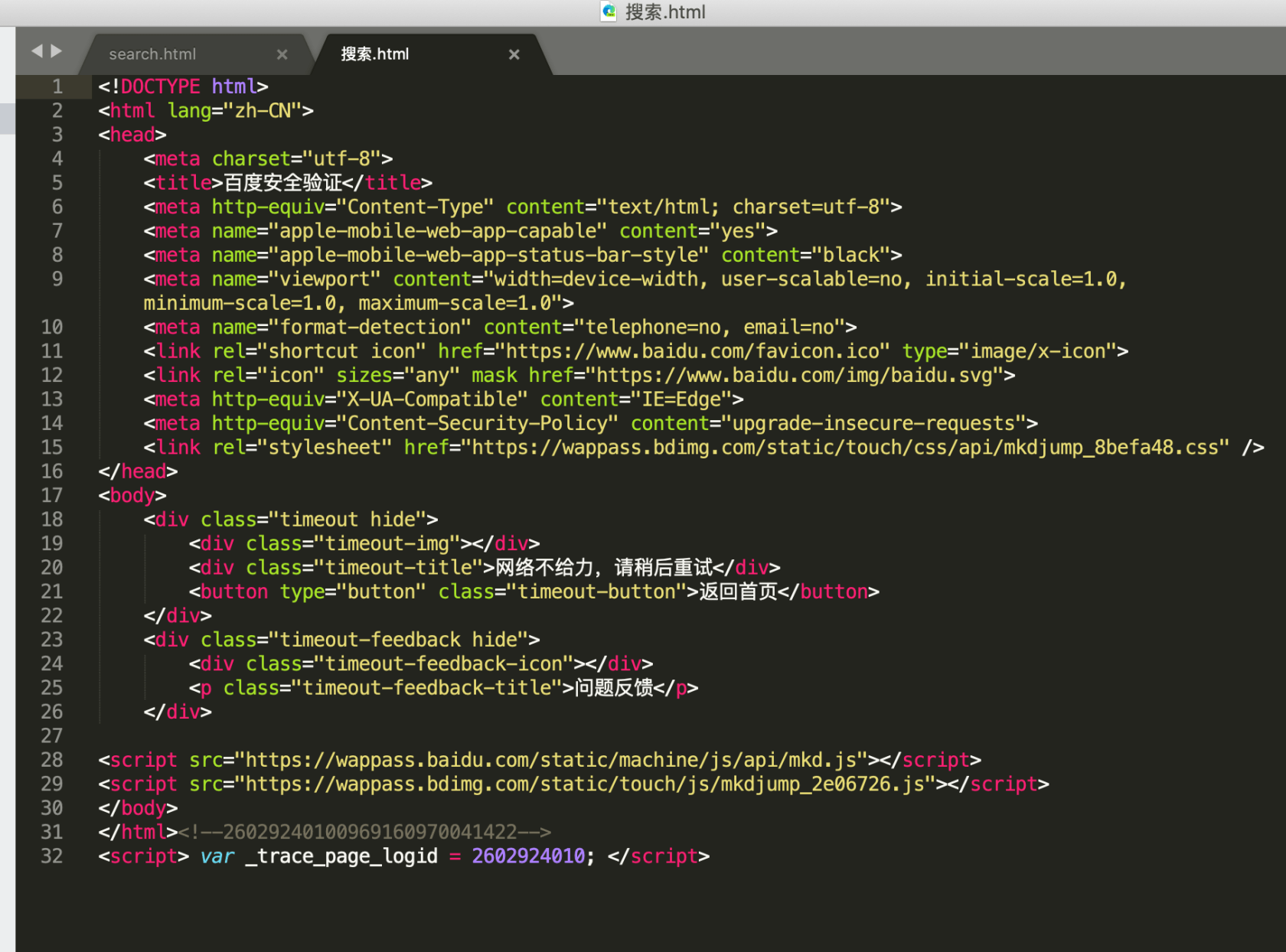
我这个代码运行后,输入任意中文,然后用编译器打搜索.html,为啥会呈现图片中的文字:网络不给力,请稍后重试,不理解。希望得到解答,谢谢。
import urllib.request
import urllib.parse
# 拼接URL
basedurl = "http://baidu.com/s?"
key = input("请输入要搜索的内容:")
# 进行urlencode()编码
wd = {"wd": key}
key = urllib.parse.urlencode(wd)
url = basedurl + key
headers = {"User-Agent": "Mozilla/5.0"}
# 创建请求对象
req = urllib.request.Request(url, headers=headers)
# 获取响应对象
res = urllib.request.urlopen(req)
html = res.read().decode("utf-8")
# 写入本地文件
with open("搜索.html", "w", encoding="utf-8") as f:
f.write(html)








 关于 LearnKu
关于 LearnKu




推荐文章: