
如何使用 Selenium 及 Xpath 在论坛网站只抓取 xpath 路径的回复内容,而不抓取引用内容?
大家好,小弟正需要对以下网站进行网路爬虫,所使用的工具是Selenium、Web Driver (chromedriver)、Python
以下是目标爬虫网站:
https://forumd.hkgolden.com/view.aspx?type...
小弟正需要针对以下帖子的每一页抓取每一位用户回复的内容,但是部分的回复内容包含了引用内容(蓝色文字),我只想抓黑色问题的内容,目前试过很多方法都未能成功。
目前我是使用了以下代码抓取回复的内容(full xpath 的绝对路径)
reply_data = driver_blank.find_element_by_xpath("/html/body/form/div[5]/div/div/div[2]/div[1]/div[5]/table[8]/tbody/tr/td/table/tbody/tr/td[2]/table/tbody/tr[1]/td/div/text()")
print(reply_data)以下图片是我需要抓取的例子,我要抓取黑色文字的内容,不要蓝色文字的内容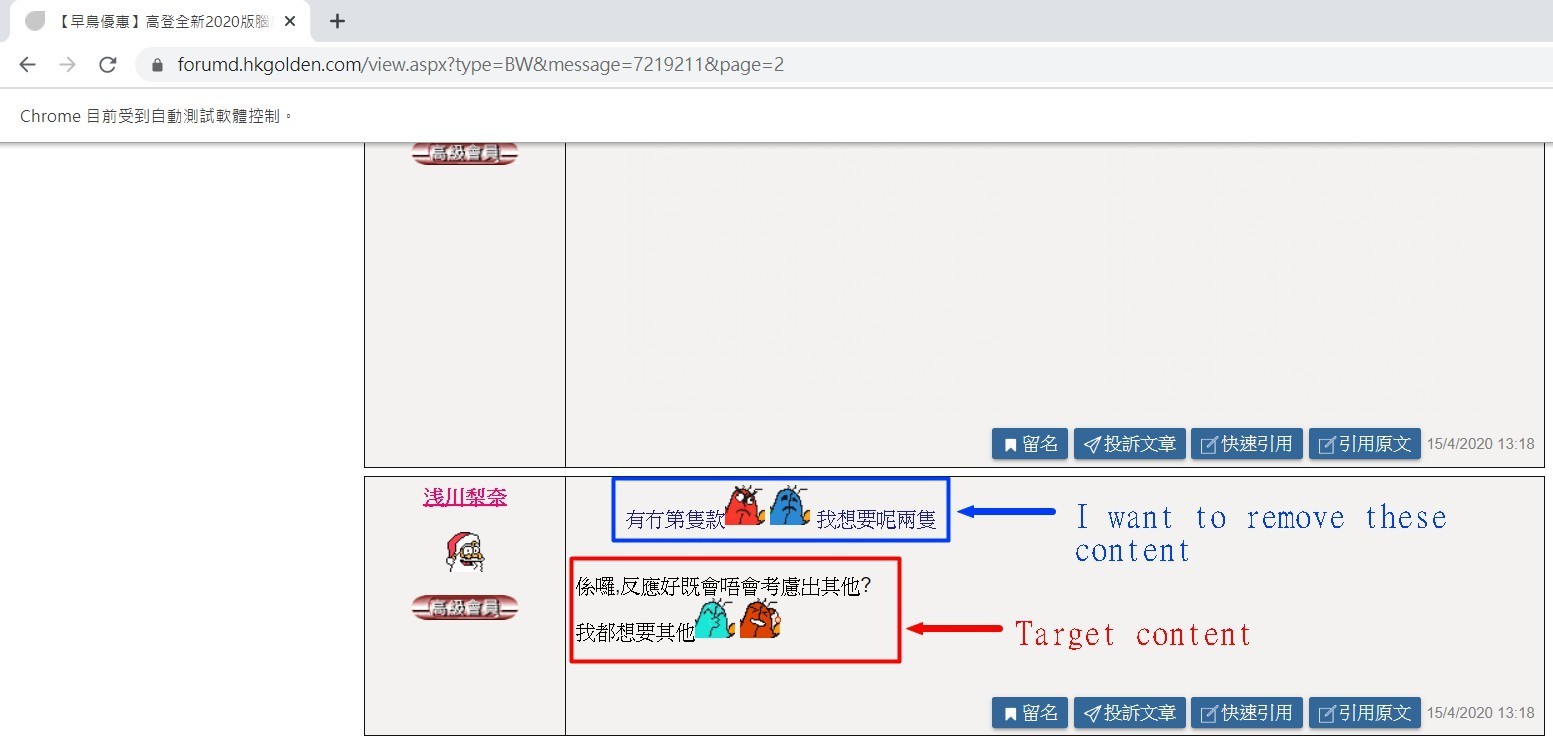
以下是回复内容的部分HTML代码:
<table class="repliers_right" cellpadding="0" cellspacing="0">
<tbody><tr>
<td style="vertical-align: top;">
<div class="ContentGrid">
<blockquote><div style="color: #0000A0;">有冇第隻款<img data-icons=":-[lm" src="/faces/lomore/angry.gif" alt=":-[lm"> <img data-icons=":-(lm" src="/faces/lomore/frown.gif" alt=":-(lm"> 我想要呢兩隻</div></blockquote><br>係囉,反應好既會唔會考慮出其他?<br>我都想要其他<img data-icons="^3^lm" src="/faces/lomore/kiss.gif" alt="^3^lm"> <img data-icons="[bomb]lm" src="/faces/lomore/bomb.gif" alt="[bomb]lm">
<br><br><br>
</div>
</td>
</tr>
<tr>
<td style="text-align: center; vertical-align: top;">
<div id="lineImage6" style="display: block; overflow: hidden;">
</div>
</td>
</tr>
<tr>
<td style="width: 100%; text-align: right;">
<div style="float: right; vertical-align: bottom; margin-top: 5px;">
<div id="lauming6" style="float: left; vertical-align: bottom;"></div>
<a class="btn btn_small btn_bookmark" href="Javascript:bookmarkThis(7219211)" id="laumingHref">留名</a>
<a class="btn btn_small btn_complain" href="contactus.aspx?messageid=7219211&replyid=275220714">投訴文章</a>
<a class="btn btn_small btn_quote" href="Javascript:QuoteReply(7219211,275220714);">快速引用</a>
<a class="btn btn_small btn_quote" href="post.aspx?mt=Y&rid=275220714&id=7219211&page=2">引用原文</a>
<span style="font-size: 12px; color:gray;">
15/4/2020 13:18
</span>
</div>
</td>
</tr>
</tbody></table>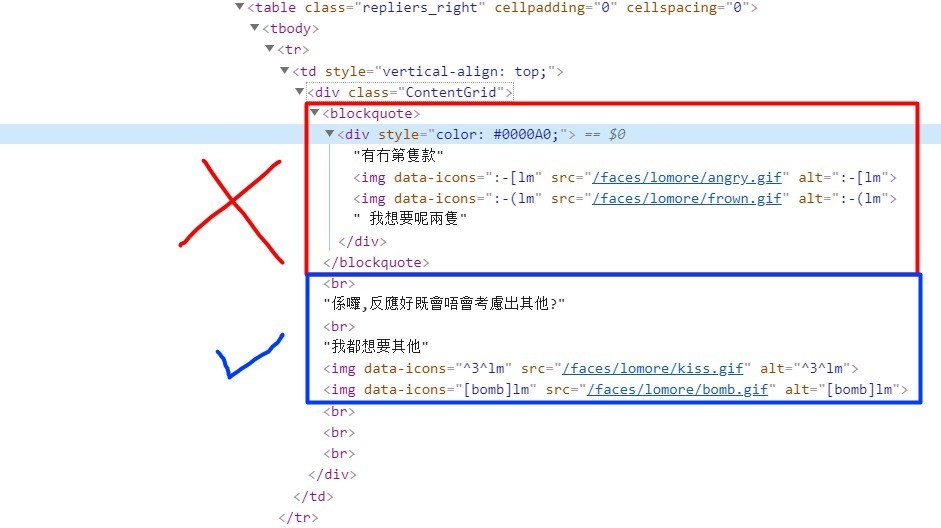
我尝试过使用start-with、contains那些,但上网找到的一些都无法让我执行成功,各位能否协助我解决这个问题,谢谢你们~








 关于 LearnKu
关于 LearnKu




推荐文章: