
有道翻译网页端 data 数据查找问题
import urllib.request
import urllib.parse
import json
# 请输入你要翻译的内容
key = input("请输入要翻译的内容:")
# 把提交的form表单数据转为bytes数据类型
data = {"i": key,
"from":"AUTO",
"to":"AUTO",
"smartresult":"dict",
"client":"fanyideskweb",
"salt":"1540373170893",
"sign":"a5d9b838efd03c9b383dc1dccb742038",
"doctype":"json",
"version":"2.1",
"keyfrom":"fanyi.web",
"action":"FY_BY_REALTIME",
"typoResult":"false"
}
# 字符串 i=python&from=auto....
data = urllib.parse.urlencode(data)
data = bytes(data,"utf-8")
# 发请求,获取响应
# url为POST的地址,抓包工具抓到的,此处去掉 _o
url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule"
headers = {"User-Agent":"Mozilla/5.0"}
# 此处data为form表单数据,为bytes数据类型
req = urllib.request.Request(url,data=data,headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode("utf-8")
# 把json格式字符串转换为Python中字典
r_dict = json.loads(html)
print(r_dict)
我想知道下面这张图在网页端怎么查找相关数据,我没找到。。。我是看别人的代码的,自己不知道怎么找,找了好几次都没找到。
http://fanyi.youdao.com/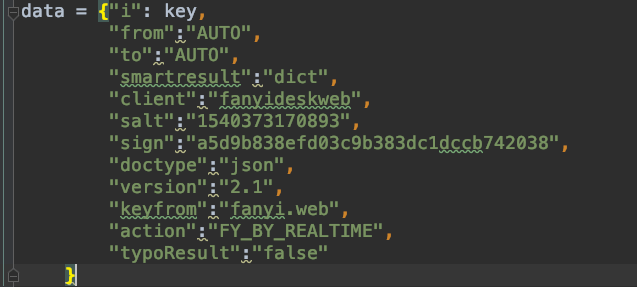
我这是用Charles 找的,不知道对不对?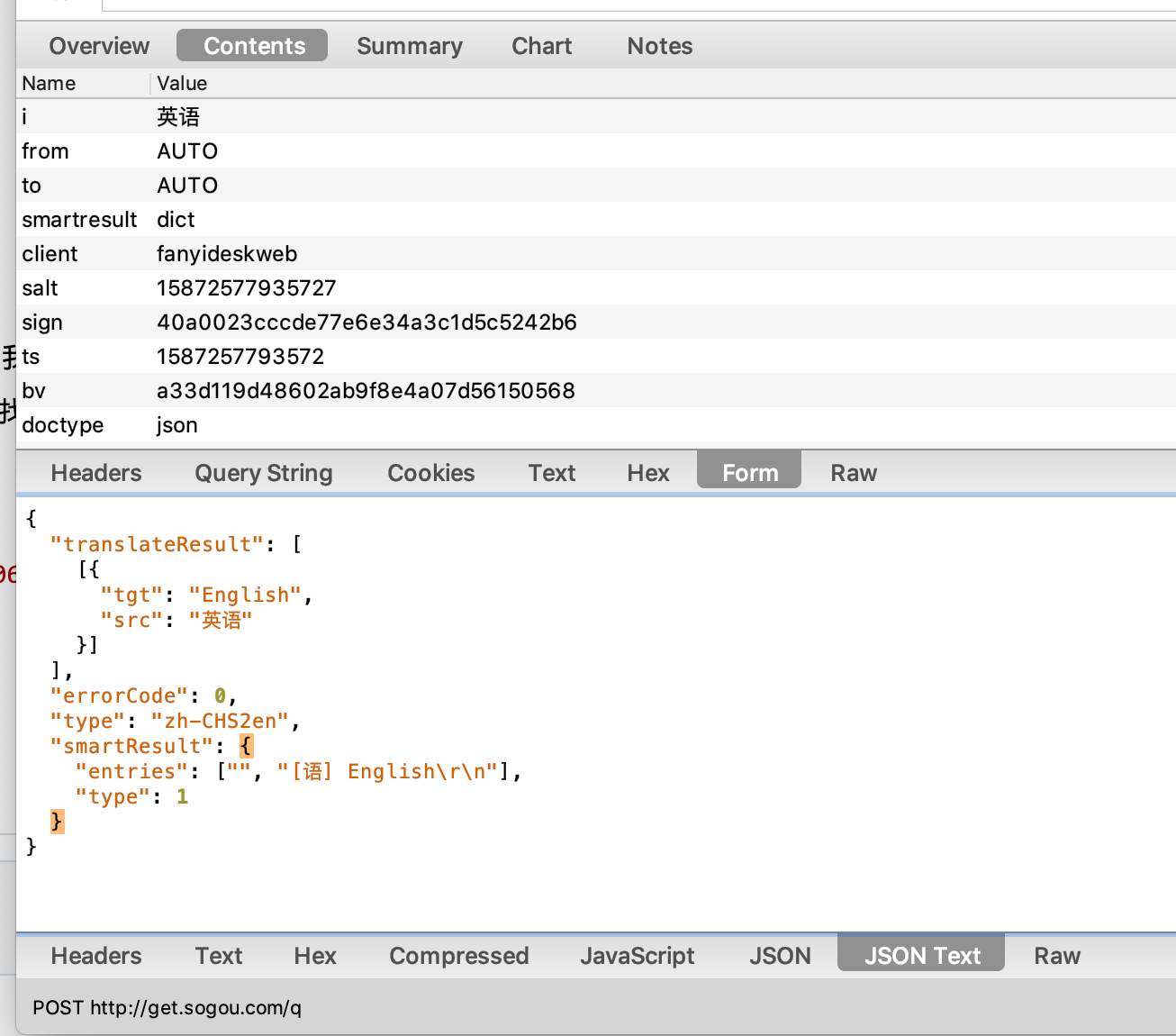







 关于 LearnKu
关于 LearnKu




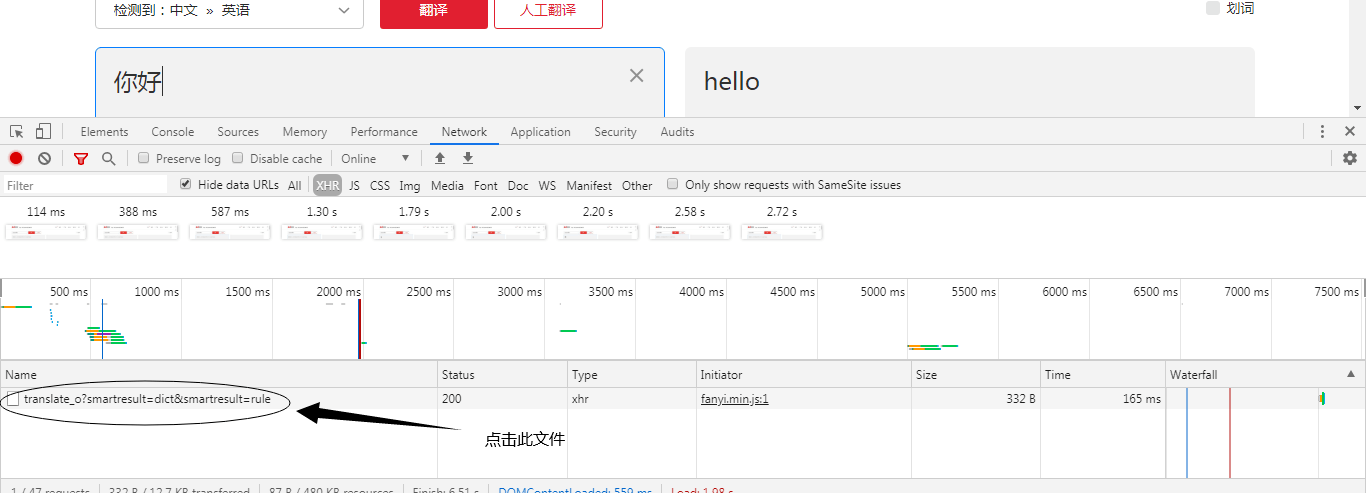
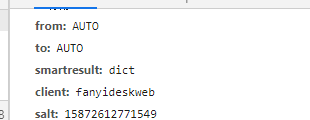
首先,你要准备好google chrome(爬虫必备)。进入到有道翻译,点F12调出开发者工具,接着选择network-xhr文件,最后F5刷新一下网页。刷新完之后,随便输入一段译文,翻译结果出来后,你会发现一个新的网站文件,如图所示:
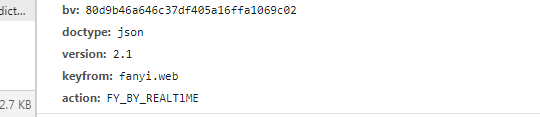
之后点击圈住的文件,翻到最底部的数据,你就可以看到data数据了,看吧,参数和代码中的一模一样。只不过是把i改成了其它的译文。
这个时候,你只要复制并且加上双引号就行了
对了,确实有一个不同点,那就是网站文件里面没有写typoResult参数。这个typoResult其实不用加的,去掉也无所谓。
如果你觉得我讲得还不够详细,可以去看一下我的博客,有一篇文章叫“python 爬虫 爬取百度翻译”。里面也有讲过找data数据,可以去看一下。