
pandas 中聚合分组功能的使用问题
假设我有一个ratings=pd.DataFrame(),数据如下
代码:ratings = pd.DataFrame([[1,2,3],[2,3,4],[3,4,5],[1,3,4],[1,4,5],[6,7,3],[3,8,1],[5,9,2]], columns=['userID','itemID','rating']) ratings['label']= ratings['rating'] ratings['label'][ratings['rating']>=4] = 1.0 ratings['label'][ratings['rating']<4] = 0.0如果想实现以下数据分组
我可以通过interact_status = ratings.groupby('userID')['itemID'].apply(set).reset_index().rename( columns={'itemID': 'interacted_items'})来实现上述结果
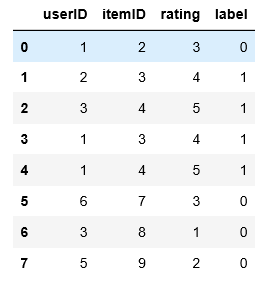
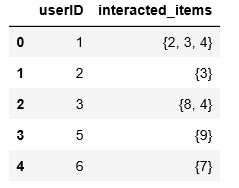
现在我想实现以下的数据分组,将itemID和rating用列表整合(以userID=1为例),这个问题我不知道怎么解决
希望有懂pandas使用的朋友解答一下,不甚感激!





 关于 LearnKu
关于 LearnKu




推荐文章: