
讨论数量:

f.read(size)从参考位置读取一定数量的数据,读取後参考位置後移。
所以是读取的内容不一样了, 而不是内容不见了.
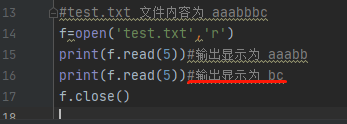
f = open('D:/test.txt', 'rt') # content of test.txt : "aaabbbc"
print("Position:", f.tell()) # reference position is 0 when open
print(f.read(5)) # 5 chars read is "aaabb"
print("Position:", f.tell()) # reference position is 5 after 5 chars read
print(f.read(5)) # 5 chars to read, but only 2 chars left, so just "bc"
print("Position:", f.tell()) # reference position is 7 after 5 chars read
f.close()Position: 0
aaabb
Position: 5
bc
Position: 7
多谢大神指点!我是初学者,在使用map函数和filter函数时,也出现过这种情况。在Python中,还有哪些函数会出现这种情况?请赐教,多谢
基本上, 每次调用函数或方法其结果不一样的都是这样, 只是这里应对的是固定的对象, 比如文件的内容, 列表的内容, 序列的内容, 每次只抽取一部份的内容,直到已无内容.
map, filter 的结果就是一个迭代器.
迭代器是一个实现next的对象,它预期将返回返回它的可迭代对象的下一个元素,并在没有更多元素可用时引发StopIteration异常.
多谢大神。还有一个问题,类似map, f.read这样的函数,除了print,其他的命令或调用是否会出现读取後参考位置后移?如果有,在哪里能查到这些东西的清单?
print 与读取后参考位置后移无关 !!
每一个函数或方法怎么工作没有一定的方式, 依其定义的方式而定, 可以这么说, 这样的函数或方法有无限多个, 无所谓的清单, 你必须对你要调用的函数或方法有所了解才行.
map 与 f.read 的工作方式并不一样
# map 类似的方式
def mapping(func, sequence):
for item in sequence:
yield func(item)
for x in mapping(int, [1.5, 2.6, -3.0]):
print(x)# f.read 类似的方式
class File():
def __init__(self, sequence):
self.sequence = sequence
self.pointer = 0
def read(self, size=None):
if size == None:
data = self.sequence[self.pointer:]
self.pointer = len(self.sequence)
elif size <= 0:
return None
elif size > 0:
data = self.sequence[self.pointer:self.pointer+size]
self.pointer = min(len(self.sequence), self.pointer+size)
if not data:
return None
return data>>> f = File("aaabbbc")
>>> a = f.read(5)
>>> print(a)
aaabb
>>> b = f.read(5)
>>> print(b)
bc
>>> c = f.read(5)
>>> print(c)
None我暂时还不能很理解大神说的,可能是因为初学,水平限制。我再学习学习,多谢大神了





 关于 LearnKu
关于 LearnKu




推荐文章: