
如何提高读取csv档案所执行的时间~?
大家好,小弟有一个程式码是读取csv档案,里面总共有100多万行,然后有10栏,以下程式码是可以正常执行,但是以下程式码会读了10次100多万行而导致很花时间,读取所花的时间大概80几秒。
import os
import sys
import csv
import time
tStart = time.time()#計時開始
def _input_file_(file_name,line_num):
with open(file_name, newline='', encoding='utf-8') as csvfile:
lines = csv.reader(csvfile)
columns = [line[line_num] for line in lines]
return columns
def _output_file_(file_name, file_type, D0):
with open(file_name, file_type, newline='', encoding='utf-8') as csvfile:
csvfile.writelines(D0)
input_file = '10_CA_BQ_Author_Merge/CA_Original_Data_Merge_BQ_Author_Num.csv'
#output_file = '10_CA_BQ_Author_Merge/CA_Complete_Data.csv'
col_0 = _input_file_(input_file,0) #帖子編號
col_1 = _input_file_(input_file,1) #帖子標題
col_2 = _input_file_(input_file,2) #發言作者
col_3 = _input_file_(input_file,3) #發表時間
col_4 = _input_file_(input_file,4) #發言內容
col_5 = _input_file_(input_file,5) #是否第一作者?
col_6 = _input_file_(input_file,6) #引用作者
col_7 = _input_file_(input_file,7) #引用內容
col_8 = _input_file_(input_file,8) #是否有引用?
col_9 = _input_file_(input_file,9) #num
print(len(col_0))
print(len(col_1))
print(len(col_2))
print(len(col_3))
print(len(col_4))
print(len(col_5))
print(len(col_6))
print(len(col_7))
print(len(col_8))
print(len(col_9))
#程式執行完成
tEnd = time.time()#計時結束
#列印結果
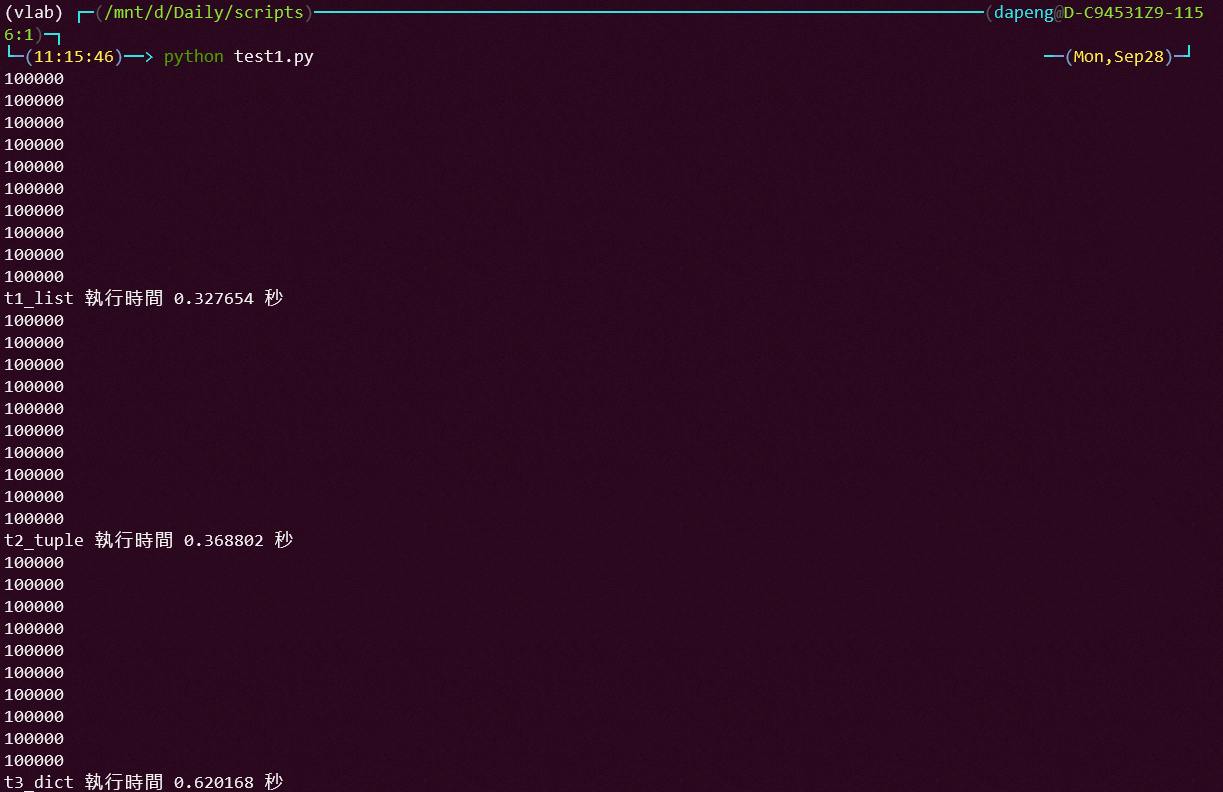
print("執行時間 %f 秒" % (tEnd - tStart))#會自動做近位对于以上程式码的设计,我目前还不知道有什么方式可以让程式不会重复10次读100多万行资料,我是想把每个栏位的每行存成一个list,希望大家可以协助以下我解决这个问题,谢谢你们。







 关于 LearnKu
关于 LearnKu




试试这个, col[0] ~ col[9]