
Xpath 定位元素,为何网页可以定位到,代码捕捉不到?
测试网址:www.daomubiji.com/
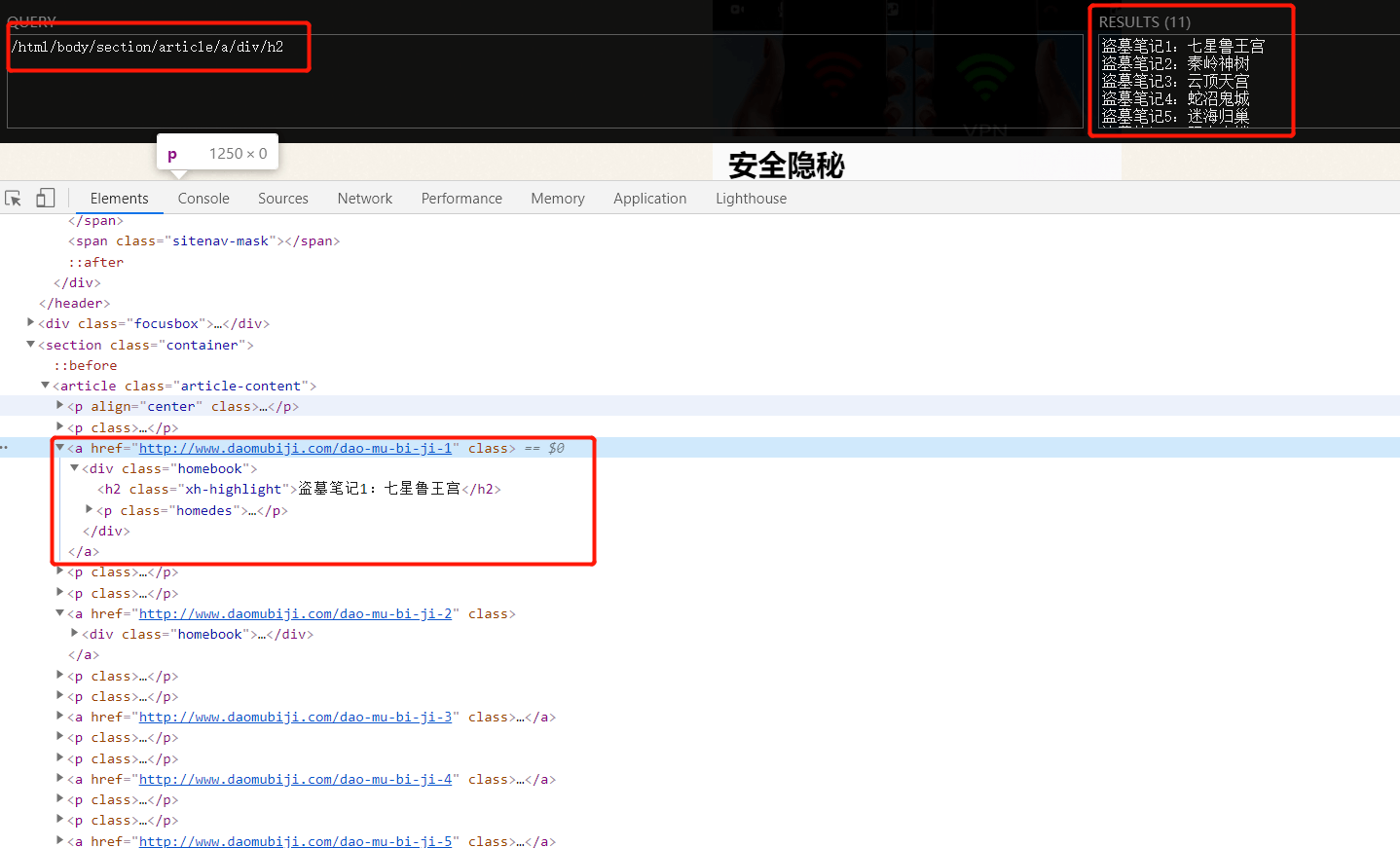
问题:网页可以定位到元素,但是通过代码请求,获取不到信息
附上代码:
import requests
from lxml import etree
city_url = "http://www.daomubiji.com/"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.113 Safari/537.36"}
response = requests.get(url=city_url,headers=headers)
html = etree.HTML(response.text)
result = html.xpath('/html/body/section/article/a/div/h2/text()')
print(result)
# 结果为空 []










 关于 LearnKu
关于 LearnKu




推荐文章: