
爬虫select问题:无法得到预期结果
#/usr/bin/env python
#-- coding:utf-8 --
import requests
from bs4 import BeautifulSoup
#需求:爬取小说所有的章节标题和章节内容fanqienovel.com/page/6844802947079...
if name ==”main“:
#对首页的页面数据进行爬取
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.74 Safari/537.36 Edg/99.0.1150.55"
}
url="https://fanqienovel.com/page/6844802947079998468?enter_from=Rank"
page_text=requests.get(url=url,headers=headers).text
#在首页解析出章节的标题和详情页的url
#1.实例化BeautifulSoup对象,需要将页面源码数据加载到该对象中
soup=BeautifulSoup(page_text,"lxml")
#解析章节标题和详情页的url
li_list=soup.select(".div.volume volume_first > div.chapter > div")#很有可能是这里出现了问题,所以我感觉我就是不会去寻找这个层级什么的,希望老师帮忙解答一下,谢谢老师
fp=open("./fanqie.text","w",encoding="utf-8")
for div in li_list:
title=div.a.string
detail_url="https://fanqienovel.com/"+div.a["href"]
#对详情页发起请求,解析出章节内容
detal_page_text=requests.get(url=detail_url,headers=headers).text
#解析出详情页中相关的章节内容
detal_soup=BeautifulSoup(detal_page_text,"lxml")
div_tag=detal_soup.find("div",class_="muye-reader-content noselect")
#解析到了章节的内容
content=div_tag.text
fp.write(title+":"+content+"\n")
print(title,"爬取成功!!!!")








 关于 LearnKu
关于 LearnKu




基本上,
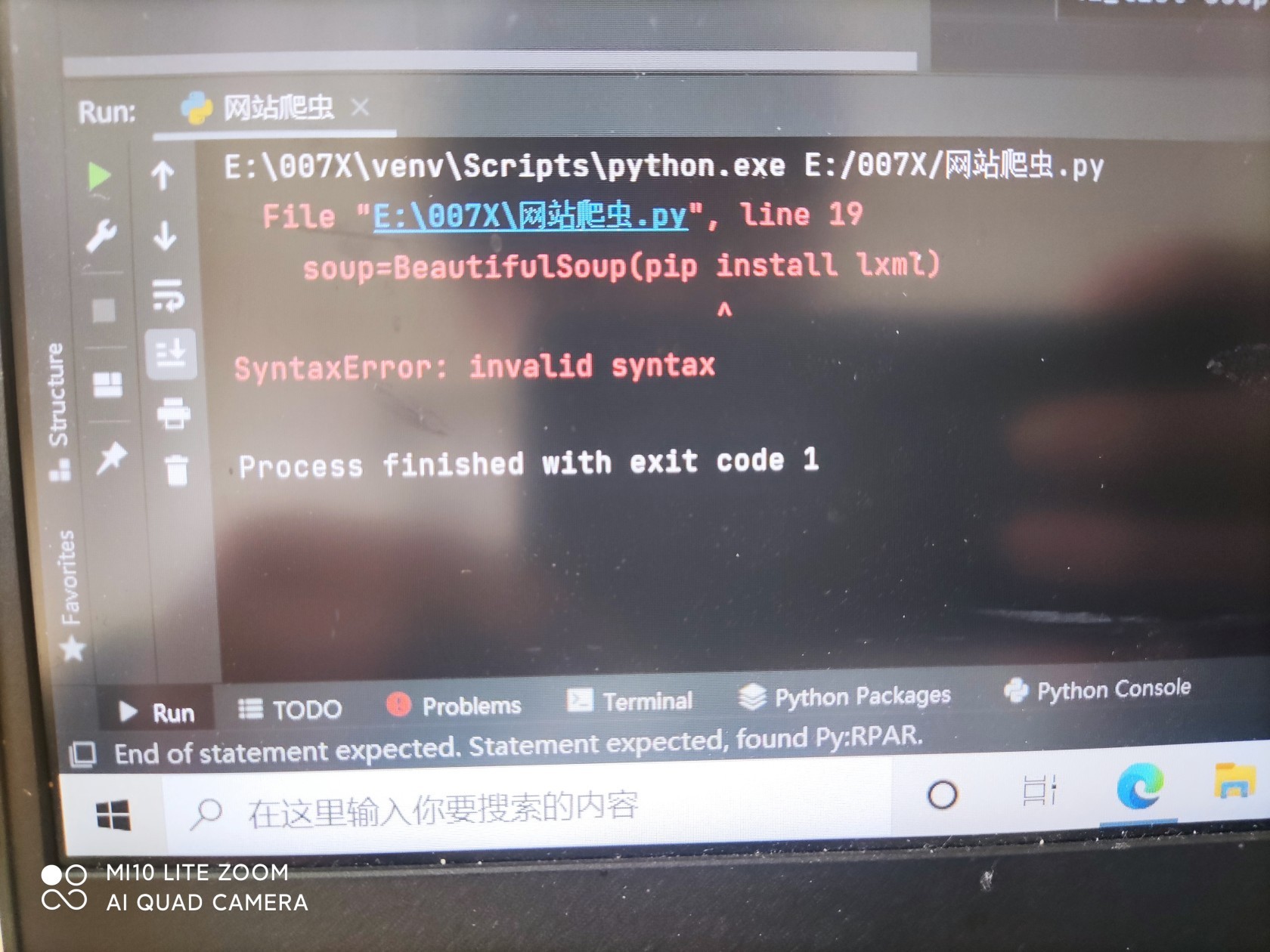
Process finished with exit code 0基本上, 代表代码运行正常结束.这句话对事情没有帮助, 至少得说一下, 报什么错啊 ?!
不可以嗎 ? 為什麼 ? 出什么错了 ?!
更新后代码
代码运行结果