
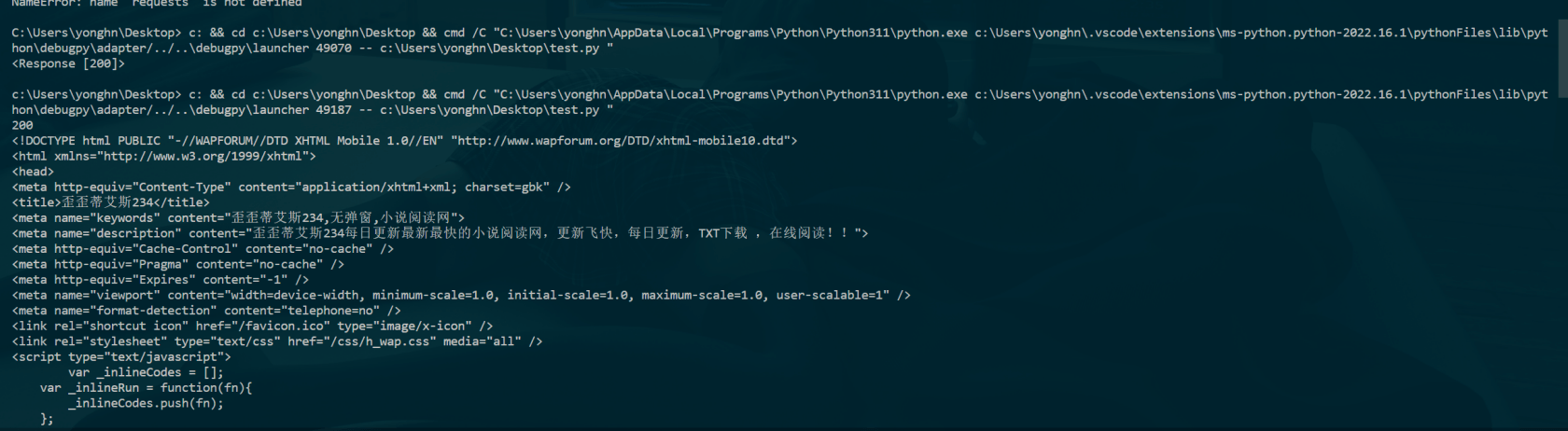
为什么postman能访问,而python无法爬取该网站
会返回403错误,headers我换了好几次了,还去手机上chrome的去取headers还是没用,但是postman和浏览器是可以访问,这是用了啥反爬虫机制?
url = 'https://yydstxt234.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Linux;Android 12;M2011K2C) AppleWebKit/537.36 (KHTML,like Gecko) Chrome/107.0.0.0 Mobile Safari/537.36',
'sec-ch-ua': '"Chromium";V="107","Not=A?Brand";V="24"',
'sec-ch-ua-mobile': '?1',
'sec-ch-ua-platform': "Android",
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1'
}
r = requests.get(url, headers=headers, timeout=15)
print(r)









 关于 LearnKu
关于 LearnKu




推荐文章: