
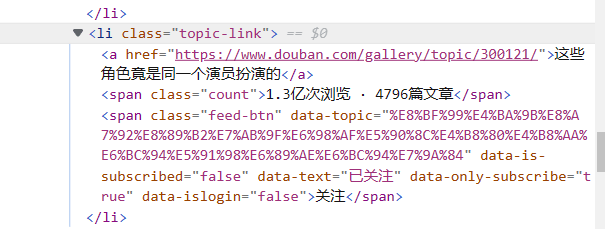
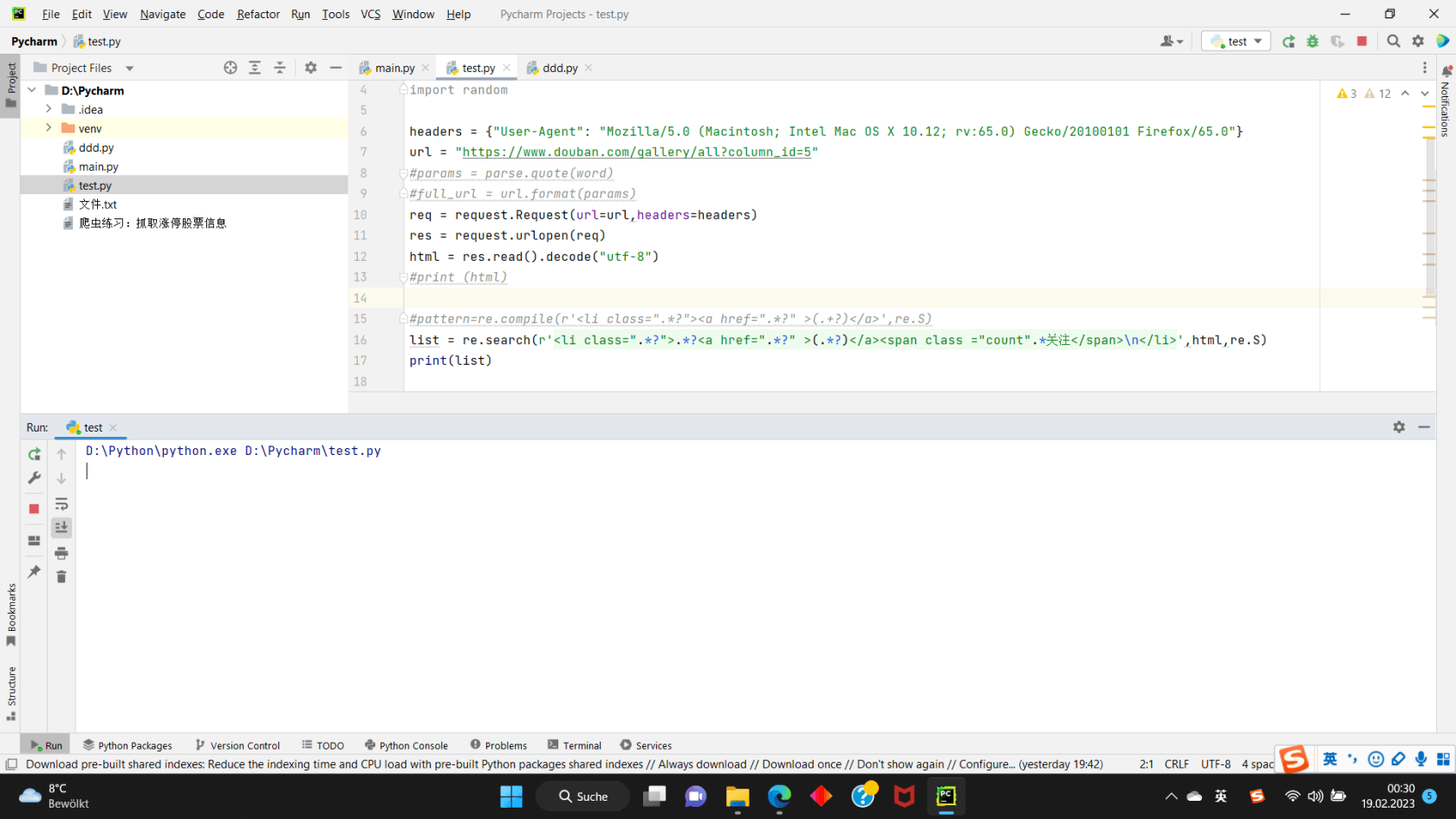

讨论数量:

把代码复制出来,不要截图
from urllib import request, parse
import re
import time
import random
import pprint
headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:65.0) Gecko/20100101 Firefox/65.0"}
url = "https://www.douban.com/gallery/all?column_id=5"
req = request.Request(url=url, headers=headers)
res = request.urlopen(req)
html = res.read().decode("utf-8")
mylist = re.findall(r'<li class="topic-link">(.*?)</li>', html, re.S)
pprint.pprint(mylist)
你是想全用标准库吗?




 关于 LearnKu
关于 LearnKu




推荐文章: