
想爬取51拍卖房网站信息,请大家帮看看,点拨一下我。
想要爬取51拍卖房的房源信息,最后保存到EXCEL中(网址 https://www.51paimaifang.com/)。
很奇怪的是我爬取到的信息与网站显示的不同。并且网站翻页后,网址没有变化。
不知如何才能爬到多页的房源信息,请大家帮看看,点拨一下我。
下面附上我自己的代码,以及爬取到的信息和网站信息对比的异常结果。
import requests
from bs4 import BeautifulSoup
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"
}
url = "https://www.51paimaifang.com/index.html?province=14&provincec=上海市"
response = requests.get(url=url,headers=headers)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text,"html.parser")
print(soup)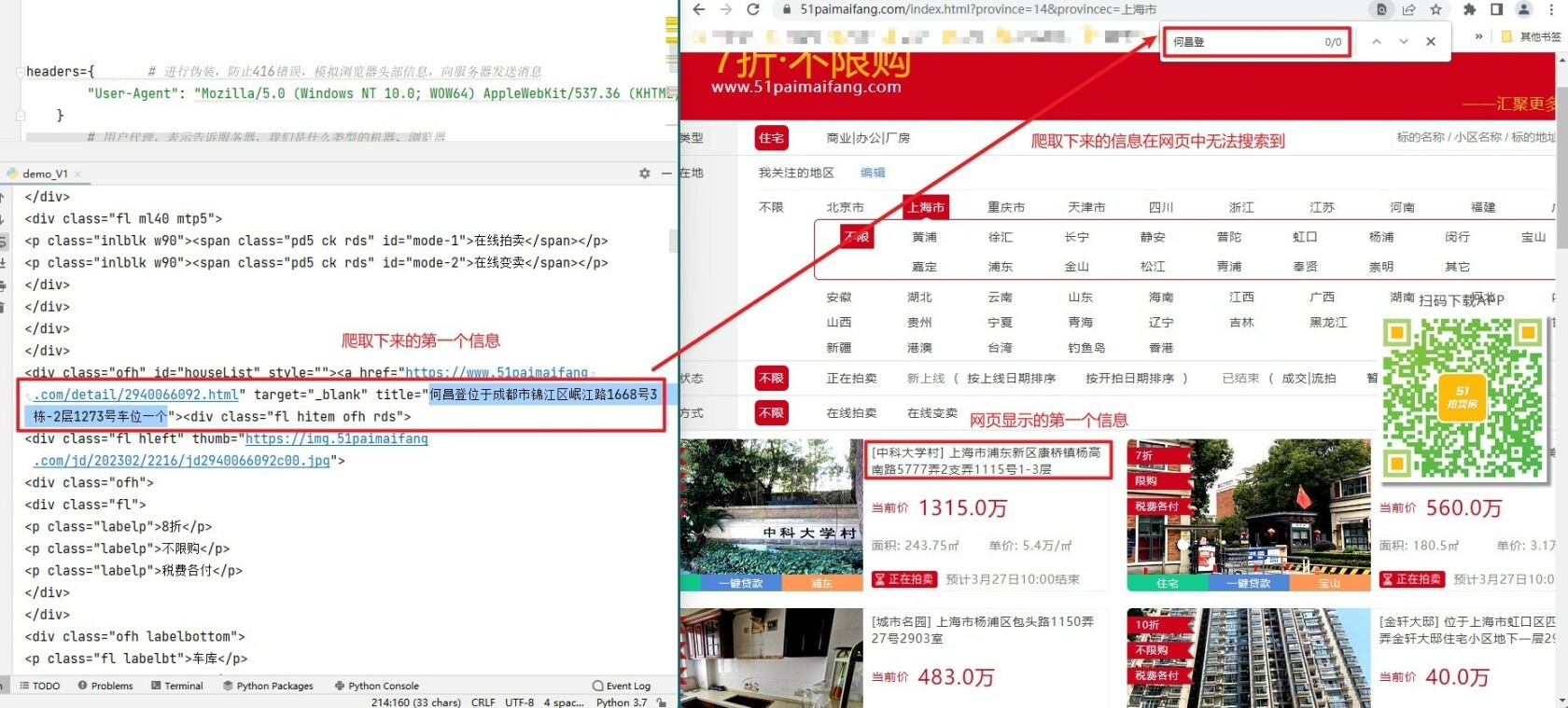
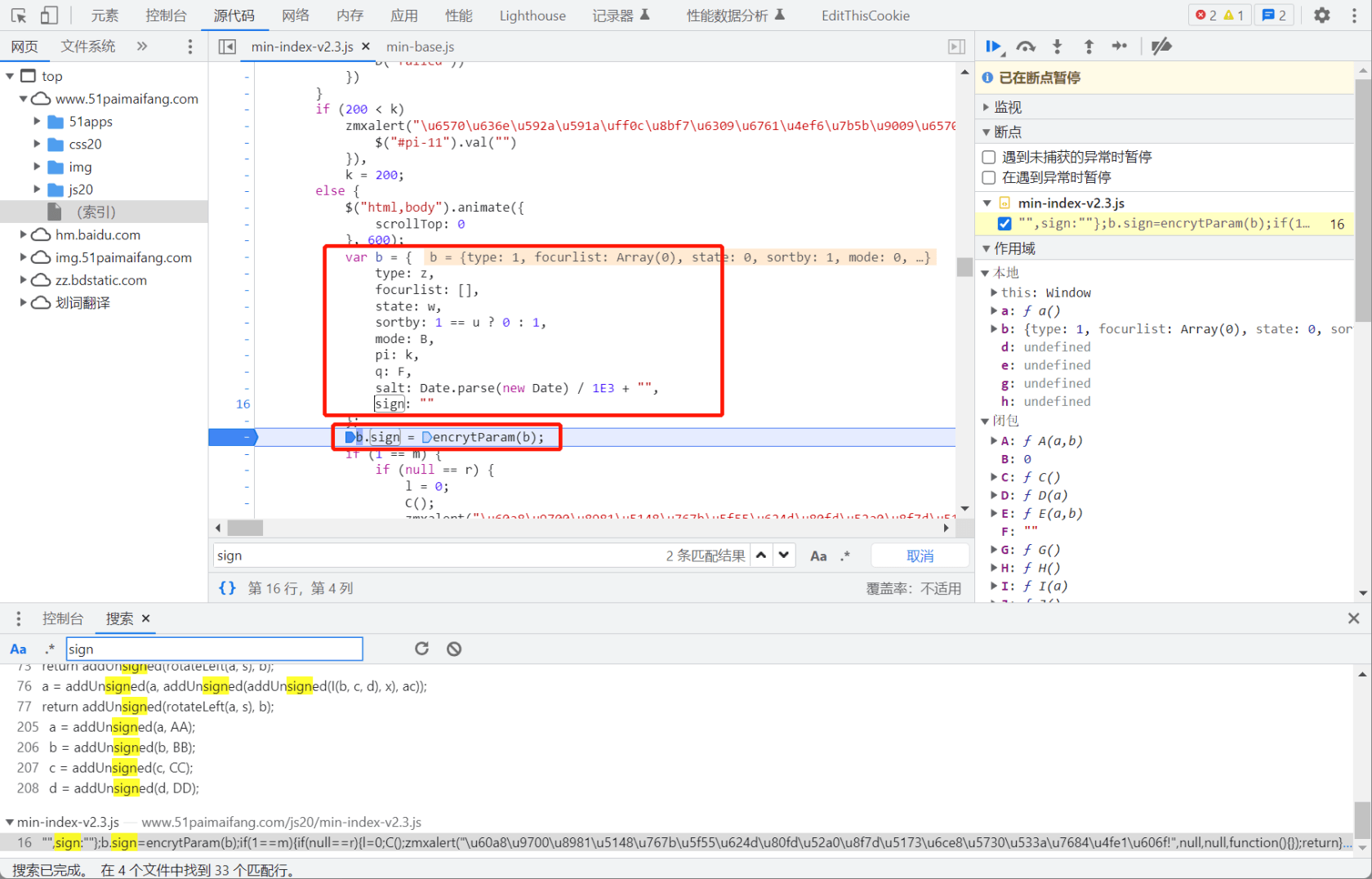
如上图所示,爬取下来的第一个信息和网站显示的第一个信息完全不同,而且爬取下来的信息在网页中无法搜索到。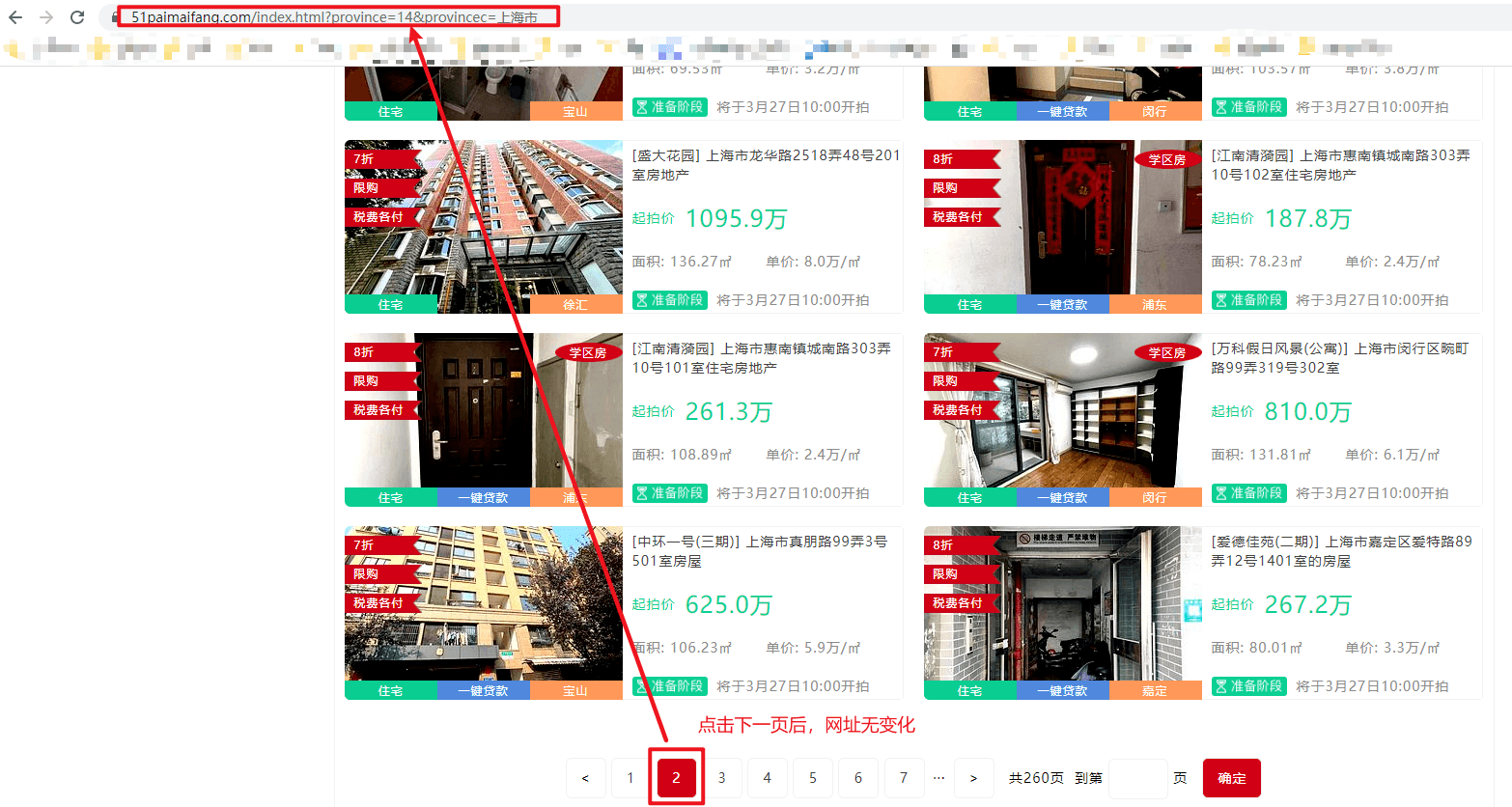
如上图所示,点击第二页后,网址无变化。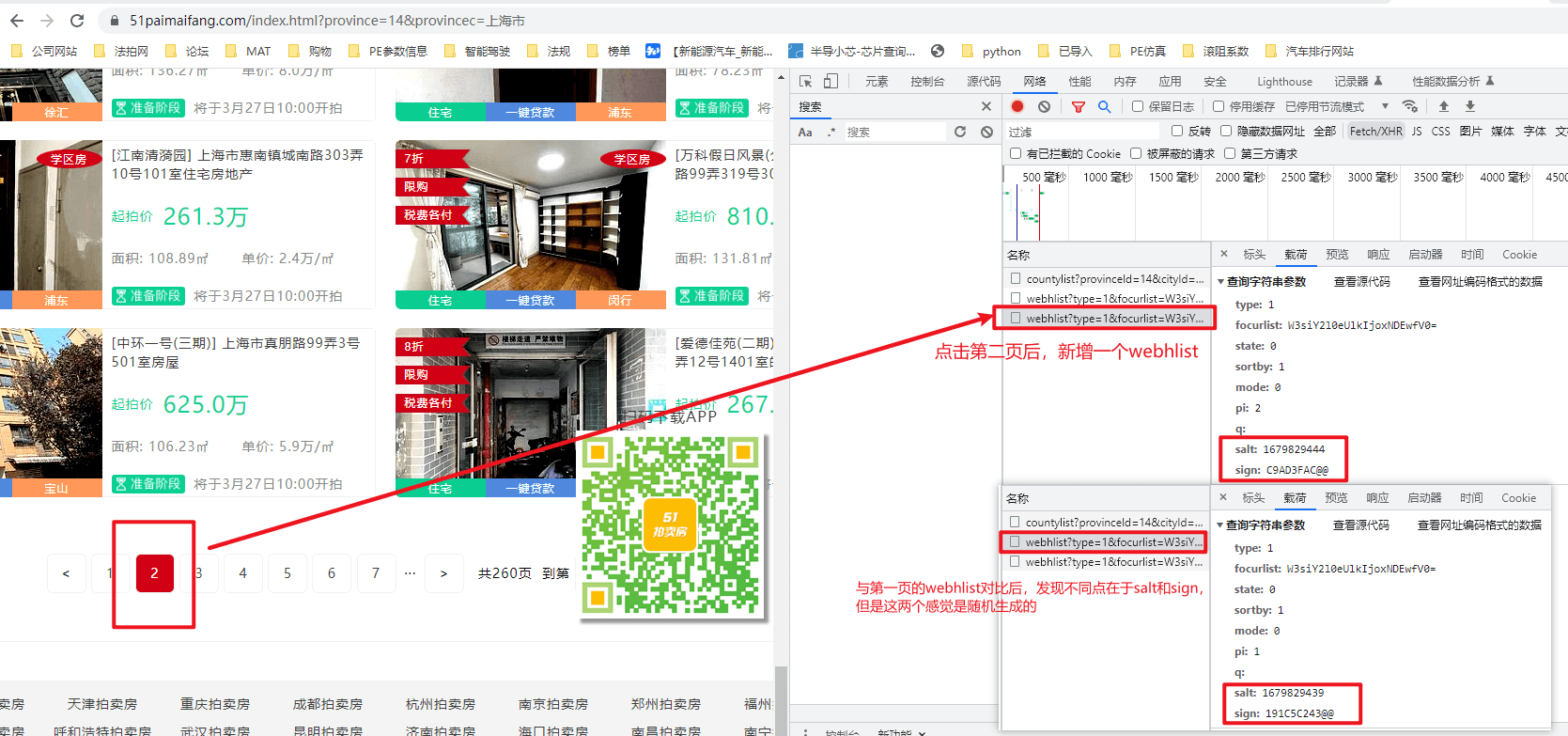
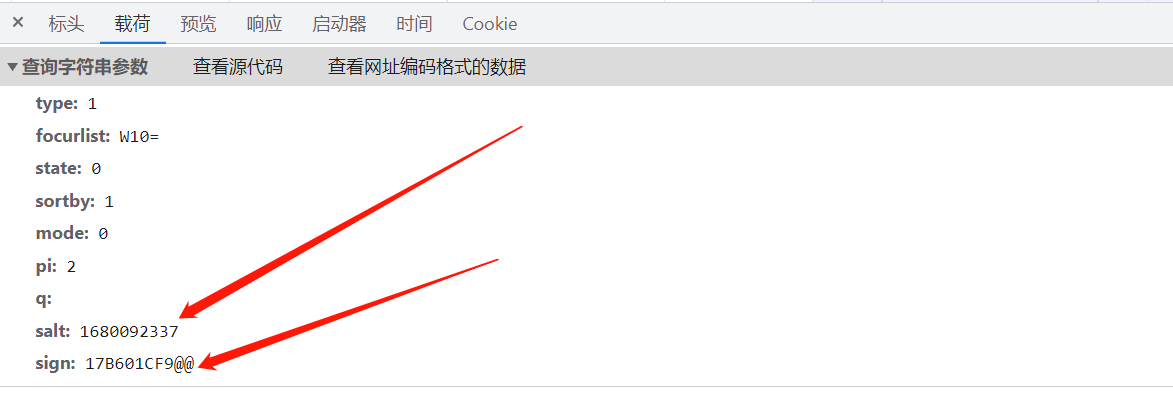
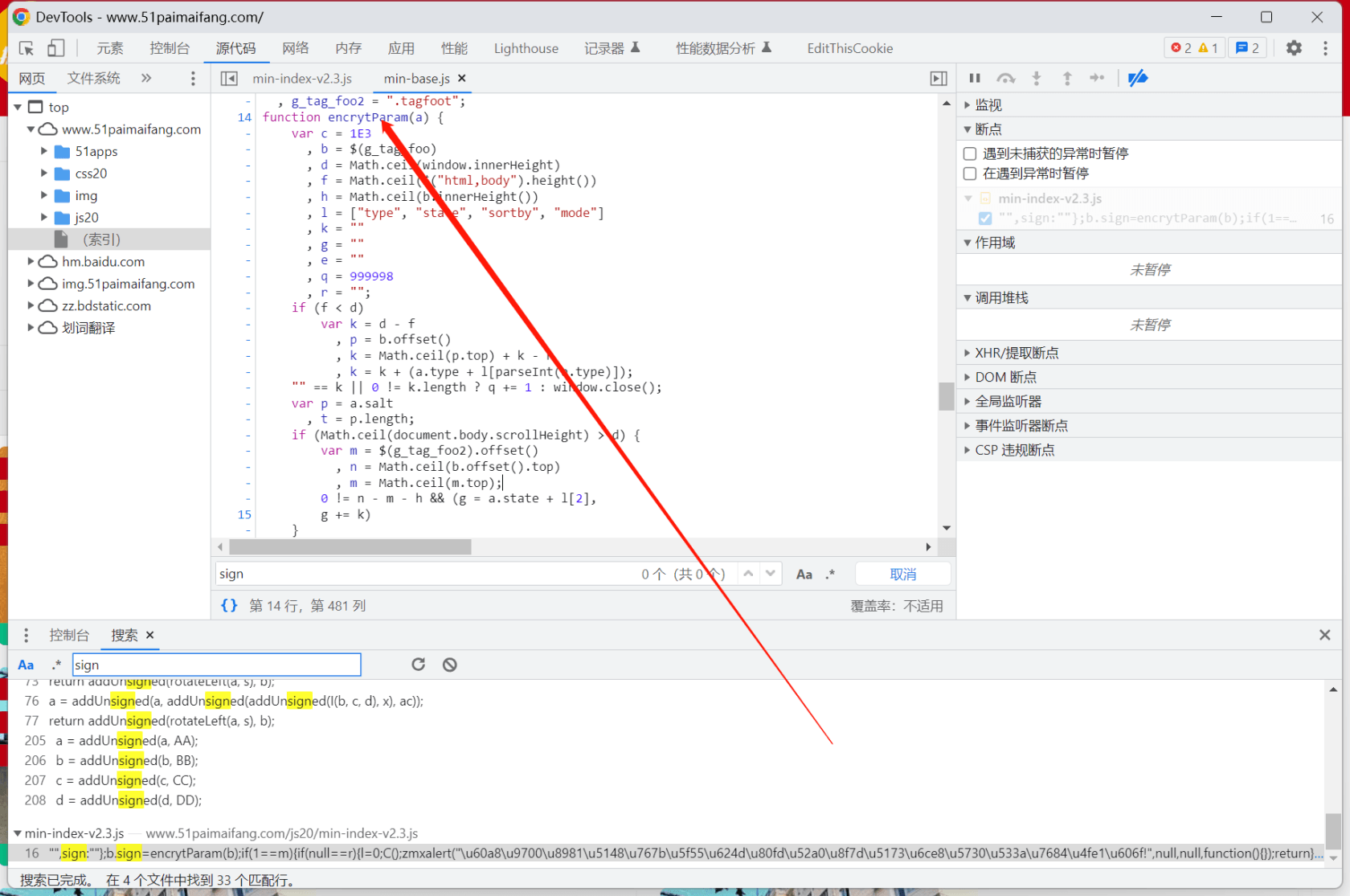
如上图所示,点击第二页后,发现webhlist新增了一行,对比不同点发现有两个随机生成的部分。









 关于 LearnKu
关于 LearnKu




推荐文章: