
在输出矩阵的时候,终端中有省略号,怎样让输出的矩阵显示完整
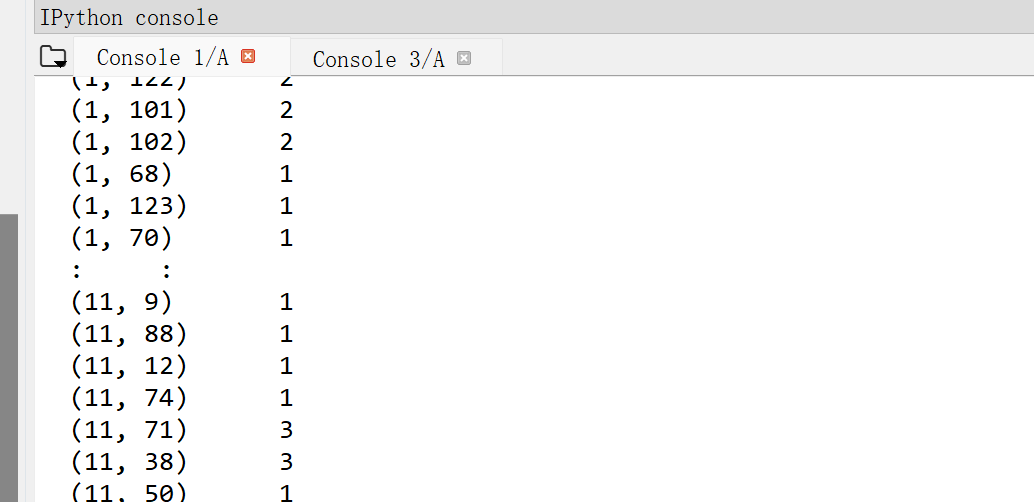
另外我在百度找到了把结果输出到txt文件的方法,但是输出后和实际结果不一样为什么呢 ;txt中的数字变成了0
;txt中的数字变成了0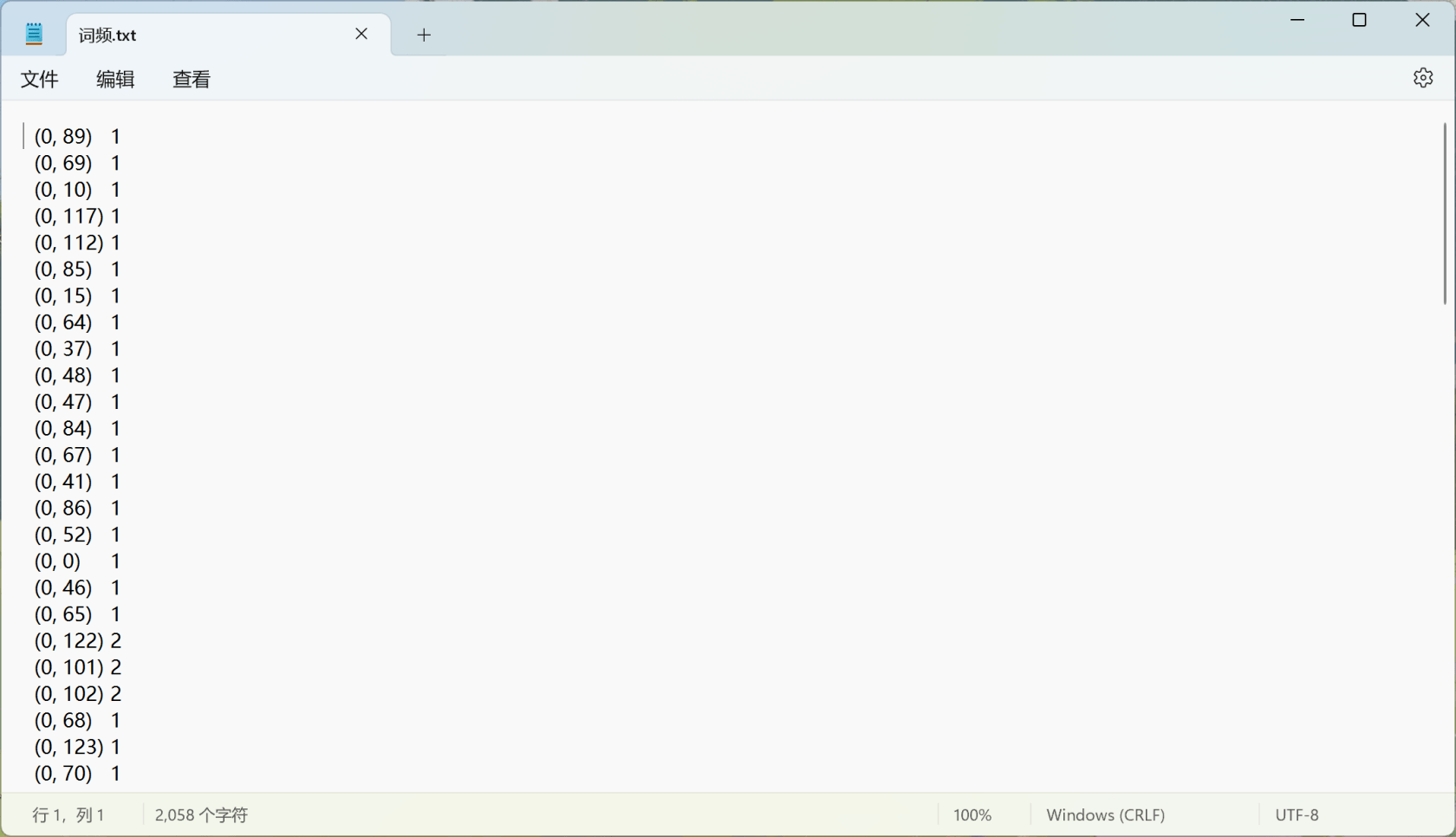
下面是代码
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from sklearn import metrics
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
import numpy as np
import jieba.analyse
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
# 示例文本数据"
texts = [
"五块钱的桂林米粉",
"我是广西的!我有话语权! 南宁的酸嘢最好吃,红糖酸嘢是特色!老友粉也尝一尝哦,小吃可以去夜市,比较齐全。 柳州的特色是螺蛳粉、螺丝鸭脚煲,有时间尝试一下当地的真的好吃,如果来不及南宁也有好吃的螺蛳粉跟螺丝鸭脚煲。 桂林的话就是山水,天气好的时候值得来看看,适合带长辈。桂林米粉。",
"快来南宁 南宁是广西首都 吃肯定是南宁全面一点酸嘢南宁哒",
"必须柳州,之前男朋友在柳州上班,我去柳州玩了一个月,真的太好吃了 ",
"宝宝我去年去过北海和桂林玩!漂亮的",
"南宁夜市最多 水果也便宜 酸野到处都有 ,柳州 螺蛳粉多 其他没什么好玩的城市很小, 桂林景色美(近期不建议来下大雨水很混 体验感会差),只考虑吃的话推选南宁!夜市真的很多 吃的琳琅满目 去南宁吧",
"我广西银!!但我其实也没玩透广西,去年寒假我去了柳州,那的早市好多吃的,有三块钱的玉米汁还有很多糯米饭糯叽叽糕点,融安金桔也可甜可美味!还有必不可少的阿嬷手作!这个在柳州南宁这些城市都有~~广西的夜市还是蛮多的,所有城市!在深夜来碗豆浆配刚出锅的油条[哇][哇]",
"快来柳州吃螺蛳粉",
"好多酸粉!",
"全逛万象城 买东西去了",
"我可太爱南宁了,不知道去哪的时候就想去南宁!!生榨粉卷筒粉老友粉各种粉太好吃啦!!!",
"我没吃过广西的,但是我去福建吃的酸嘢也好好吃,厦门的阿忠水果,是腌水果,超级好吃,水果新鲜,脆脆的口感无敌好吃,回来以后还想这一口[泪][泪] ",
"来桂林市区!!这边桂林米粉很好吃!也有很多公园!!还有糯米饭醋血鸭水麻糍!",
"南宁和柳州都好吃",
"这个我知道 南宁!我就是广西人"
]
# 使用jieba进行分词
def tokenize(text):
return " ".join(jieba.cut(text))
tokenized_texts = [tokenize(text) for text in texts]
# 计算词频 TF-IDF值及 TF-IDF矩阵
vector = CountVectorizer()
train_data = vector.fit_transform(tokenized_texts)
#np.set_printoptions(threshold=np.nan) # 设置显示矩阵所有行列
print('特征个数:', len(vector.get_feature_names()))
print('特征词:', vector.vocabulary_)
print('词频:', train_data)
with open('C:/Users/15213/Desktop/词频.txt', 'w') as f:
for item in train_data: # 假设your_iterable是你的数据
f.write(str(item) + '\r')
transfomer = TfidfTransformer()
tf_train_data = transfomer.fit_transform(train_data)
print('词频矩阵TF-IDF值', tf_train_data)
with open('C:/Users/15213/Desktop/词频矩阵.txt', 'w') as f:
for item in tf_train_data: # 假设your_iterable是你的数据
f.write(str(item) + '\r')
# 使用KMeans进行聚类
n_clusters = 5
kmeans = KMeans(n_clusters=n_clusters, random_state=0).fit(tf_train_data)
inertias = kmeans.inertia_
#nertias 是K均值模型对象的属性,表示样本距离最近的聚类中心的总和 该值越小越好,值越小证明样本在类间的分布越集中,即类内的距离越小。
print(inertias)
# 输出聚类结果
for i, label in enumerate(kmeans.labels_):
print(f"文本{i}的聚类标签为:{label}")求求各位大佬帮忙









 关于 LearnKu
关于 LearnKu




推荐文章: