
数据结构之并查集
0 / 0 / 创建于 6年前 /
 codercat 的个人博客
codercat 的个人博客
定义
并查集是计算机科学中为了解决
集合之间的合并和查询操作而存在的一种树型数据结构。并查集是由若干个大小不同的子树来存储表示的,也可以把整个并查集的存储结构叫做森林,每颗子树表示一个集合。集合的数量又叫做连通分量。
基本操作
- find(查询):确定元素属于哪一个子集。它可以被用来确定两个元素是否属于同一子集。
- union(合并):将两个子集合并成同一个集合。
- isConnected(两个元素是否相连):确定两个元素是否属于同一子集或者确定两个元素是否相连。
名词解释
- 森林:由若干个大小不同的子树所表示的数据结构。
- 连通分量:在这里简单的可以理解为并查集中集合的数量。
- 树的大小:树的节点数量。
- 树中某个节点的深度:该节点到树的根节点的路径上的链接数。
- 树的高度:树中所有节点中的最大深度。
解决的问题
- 在社交网络中判断两个人是否属于同一个交际圈。
- 查询网络中的两个网络节点是否相连。
- 数学中判断两个元素是否属于同一个集合。
- 数学中把两个不相交的子集合并成一个集合。
并查集的实现
并查集有两种实现方式,分别是
quick find和quick union,其中quick union有两个优化思路,文中都会详细介绍。
quick find
为每一个集合都选取一个元素做为该集合的唯一编号,如果有两个元素它们的编号相同,那么就说明它们属于同一个集合。
初始化
初始情况下如果有
N个元素,我们认为这个N个元素之间都是相互独立的,也就是一共有N个集合,每个集合只有一个元素。定义一个叫做ids的数组用来存储每个集合的编号。每个集合的编号只需要保证不重复即可。可以循环N次为每个集合从0到N-1编号。
如图所示:

代码实现:
class UnionFind {
private:
// 并查集中的元素个数
unsigned int elementNum = 0;
// 联通分量,也是集合的数量
unsigned int connectedComponent = 0;
// 存储每个集合的编号
int *ids;
public:
UnionFind(unsigned int elementNum) {
this->elementNum = elementNum;
// 初始情况下联通分量为元素个数
this->connectedComponent = elementNum;
this->ids = new int[elementNum];
// 初始化每个集合的编号为0至size-1
for (int i = 0; i < elementNum; i++) {
this->ids[i] = i;
}
}
};查询
查询一个元素属于哪个集合,只需要查看这个元素的
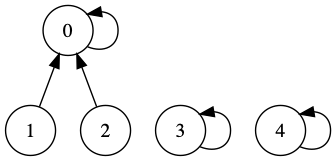
id。这也是为什么叫quick find,因为查询操作只需要O(1)的时间复杂度。
下图中0,1,2这三个元素的id都是0,元素3和元素4的id分别是3和4。
代码实现:
int find(element) {
return this->ids[element];
}两个元素是否相连
判断两个元素是否属于同一个集合时,只需要对比两个元素的id是否相等即可。
下图中0,1,2这三个元素的id都是0,所以它们是相连的。节点3和元素0,1,2都不相连,因为它们id不同。
代码实现:
bool isConnected(int p ,int q) {
return this->find( p) == this->find(q);
}合并
合并两个集合时,只需要把任意其中一个集合中的所有元素的
id修改成另外一个集合的id即可,这样一来原先的两个集合都指向了同一个id,就完成了合并操作。
如果我们需要把上图中元素3和元素2合并,就有两个办法分别是:
-
把元素
2所在的集合的所有元素的id修改成元素3所在集合的id。
-
把元素
3所在的集合的所有元素修改成元素2所在集合的id。
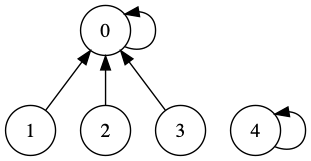
不管选择哪一种方法最终所表示的集合都是等价的,所以两种方法都可以。
代码实现:
void unionElement(int p, int q) {
int pId = this->find(p);
int qId = this->find(q);
// 如果p和q本来就相连就不需要合并
if (pId == qId) {
return;
}
for (int i = 0; i < this->size; i ++) {
// 把其中一个集合中的所有元素的id修改成另外一个集合的id
if (this->id[i] == pId) {
this->ids[i] = qId;
}
}
// 合并之后少了一个集合,connectedComponent就应该-1
this->connectedComponent --;
}quick find这种实现方式,它的优点在于可以快速的查询元素属于哪一个集合。缺点是在每次做合并的时候都需要遍历整个ids数组然后去修改其中一个集合的所有元素的id,这样就会导致合并操作在数据量大的时候时间复杂度很高。
quick union
把每个元素看成一个
节点,每个节点指向该节点的父节点。这一点跟传统的树行结构不太一样,传统的树行结构是节点指向该节点的孩子节点。并查集中的每棵树都表示一个集合,整个并查集所表示的就是一个森林。每棵树会选取一个节点作为代表,用来代表这棵树所表示的集合,这个代表节点也是树的根节点。如果两个元素的根节点相同则它们属于同一棵树也就是属于同一个集合。
初始化
初始情况下,我们还是认为每个
元素(节点)之间相互独立,每棵树只有一个根节点就是其本身,这个根节点用来代表这棵树所表示的集合。定义一个叫做parents的数组用来存储每个节点的父节点。
如图所示:
代码实现:
class UnionFind {
private:
// 并查集中的元素个数
unsigned int elementNum = 0;
// 联通分量,也是集合的数量
unsigned int connectedComponent = 0;
// 存储每个节点的父节点
int *parents;
public:
UnionFind(unsigned int elementNum) {
this->elementNum = elementNum;
// 初始情况下联通分量为元素个数
this->connectedComponent = elementNum;
this->parents = new int[elementNum];
// 初始化每个节点的父节点是其本身
for (int i = 0; i < elementNum; i++) {
this->parents[i] = i;
}
}
};查询
查询一个元素属于哪个集合,只需要查看该元素所在树的根节点的那个元素是谁,就属于哪个集合。
下图中0,1,2,3这四个元素的根节点都是0,元素3的根节点是3。整个并查集是由两棵树组成的一个森林。
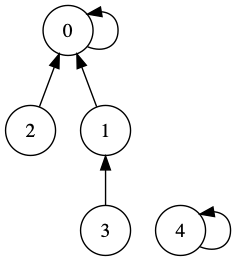
如果要查询节点3属于哪一个集合就需要在parents数组中递归去寻找树的根节点,直到找到某个节点的父节点是其本身的一个节点,这个节点就是树的根节点。
递归实现:
int find(element) {
int parent = parents[element];
// 如果某个节点的父节点是其本身的一个节点,那么就是一个根节点
if (parent == element) {
return parent;
}
// 继续递归查询
return this->find(parent);
}循环实现:
int find(element) {
while (parents[element] != element) {
element = parents[element];
}
return element;
}两个元素是否相连
判断两个元素是否属于同一个集合时,只需要对比两个元素所在树的根节点是否是否是同一个节点即可。
下图中0,1,2,3这四个元素的根节点都是0,证明它们属于同一棵树且相连。元素3的根节点是3。所以节点3和元素0,1,2,3都不相连,因为它们的根节点不同。
代码实现:
bool isConnected(int p ,int q) {
return this->find( p) == this->find(q);
}合并
合并两个集合时,只需要把其中任意一颗树的根节点的父节点修改成另一个颗树的根节点,这样一来原先两颗树的根节点都是同一个节点,就完成了合并操作。
下图中有两个集合,包含的元素分别是0,1,2,3和4,5,6。对应的两棵树的根节点分别是0和4。当合并这两个集合时,我们可以把这两棵树中的任意一棵树的根节点的父节点修改成另一棵树的根节点就可以完成合并操作。

我们把根节点为4的这棵树的根节点的父节点修改成0,就合并成了一个集合。树的形状也就变成了下面这个样子:

代码实现:
void unionElement(int p, int q) {
int pRoot = this->find(p);
int qRoot = this->find(q);
// 如果两个元素的根节点相同,则代表它们属于同一个集合,就不再需要合并
if ( pRoot == qRoot ) {
return;
}
// 修改其中一棵树根节点的父节点
this->parents[qRoot] = pRoot;
// 合并之后少了一个集合,connectedComponent就应该-1
this->connectedComponent --;
}
加权quick union
quick union合并时存在的问题
下图中两棵树所表示的集合相同,都分别表示的是拥有0,1,2,3,4这5个元素的一个集合。

左边树中节点4的深度为3,而右边树中节点4的深度则为1。通过quick union的find的实现可以知道,当在左边树中执行find(4)时需要的时间复杂度是要高于右边树中执行find(4)的,因为。所以得出一个结论就是:quick union中的find操作的时间复杂度是跟要查找节点在树中的深度相关的。find操作需要一直向上寻找根节点,如果要查找的节点在树中深度很深,那么需要寻找根节点的次数也就会越多。
优化思路
由于在quick union中对两个集合进行union操作时,不管是哪棵树的根节点的父节点修改成另外一棵树的根节点最终所得到的新树所表示的集合都是等价的。
所以我们可以在union操作时把树的高度较小的那棵树的根节点的父节点修改成树的高度较大的那颗树的根节点,在两棵树的高度相等时,就跟先前一样不管是哪棵树的根节点的父节点修改成另外一棵树的根节点最终所得到的新树所表示的集合和新树的高度都是一样的。
优化思路证明
存在两颗树分别是A和B,它们树的高度分别是Ah和Bh且Ah <Bh。我们有两种办法可以来完成union操作,分别是:
-
树
A的根节点的父节点修改成树B的根节点(优化思路)修改之后由于在原来树
A的根节点新增了一个节点,所以在新的树中原来树A的高度为Ah+1。由于Ah <Bh,所以Ah+1<=Bh。得到新树的最大深度为Bh。 -
树
B的根节点的父节点修改成树A的根节点修改之后由于在原来树
B的根节点新增了一个节点,所以在新的树中原来树B的高度为Bh+1。由于Ah <Bh,所以Ah<Bh+1。得到新树的最大深度为Bh+1。
得到结果Bh<Bh+1就可以证明我们的优化思路是可以降低节点在树中的深度的。
具体实现
初始化的时候跟
quick union一样,只是多了数组用来存放每个节点的深度,我们定义这个数组叫ranks。初始化情况下我们让每个节点在树中的深度为1。find和isConnected的实现跟之前的quick union一样。
代码实现:
class UnionFind {
private:
// 并查集中的元素个数
unsigned int elementNum = 0;
// 联通分量,也是集合的数量
unsigned int connectedComponent = 0;
// 存储每个节点的父节点
int *parents;
// 记录每个根节点所在树的深度
int *ranks;
public:
UnionFind(unsigned int elementNum) {
this->elementNum = elementNum;
// 初始情况下联通分量为元素个数
this->connectedComponent = elementNum;
this->parents = new int[elementNum];
this->ranks = new int[elementNum];
for (int i = 0; i < elementNum; i++) {
// 初始化每个节点的父节点是其本身
this->parents[i] = i;
this->ranks[i] = 1;
}
}
// 合并元素
void unionElement(int p, int q) {
int pRoot = this->find(p);
int qRoot = this->find(q);
// 如果两个元素的根节点相同,则代表它们属于同一个集合,就不再需要合并
if (pRoot == qRoot) {
return;
}
int pRank = this->ranks[pRoot];
int qRank = this->ranks[qRoot];
// 把深度低的树的根节点指向深度高的树的根节点。
if (pRank > qRank) {
this->parents[qRoot] = pRoot;
} else if (pRank < qRank) {
this->parents[pRoot] = qRoot;
} else {
this->parents[pRoot] = qRoot;
this->ranks[qRoot]++;
}
// 合并之后少了一个集合,connectedComponent就应该-1
this->connectedComponent --;
}
};路径压缩
最优树结构
通过我们优化之后的加权quick union还是没有达到我们最优树结构。下图的两棵树都表示的是两个相同的集合。左边树中的每个节点与根节点的距离大于等于1。右边树中的每个节点与根节点的距离等于1,也就是我们想要的最优树结构。
我们需要一个算法要压缩路径使得树中的每个节点与根节点的距离为1。
路径压缩思路
把某个节点的父节点修改成该节点
父节点的父节点,一直向上对这条链接上的每个节点做相同的操作直到遇到根节点终止,就可以压缩每个节点到根节点的距离。
路径压缩过程演示
左边树中节点4的父节点的父节点是2,所以把左边树中节点4的父节点修改成2,得到右边的树:

左边树中节点4的父节点的父节点是0,所以把左边树中节点4的父节点修改成0,得到右边的树:

左边树中节点3的父节点的父节点是0,所以最后把左边树中节点3的父节点修改成0,就得到右边的树:

这样一番操作之后最终得到结果就是我们想要的树结构。
具体实现
由于路径压缩的过程跟
find操作有些类似,都是向上寻找节点,且都是遇到根节点终止,所以把路径压缩的过程就直接放在了find操作中。union操作不需要做任何改动。
find代码实现:
int find(int element) {
int parent = parents[element];
if (parent == element) {
return parent;
}
// 路径压缩,parents[parent]得到的就是当前节点父节点的父节点
parents[element] = parents[parent];
return this->find(parents[element]);
}完整源代码
源代码:https://github.com/acodercat/cpp-algorithm...
使用示例:https://github.com/acodercat/cpp-algorithm...
本作品采用《CC 协议》,转载必须注明作者和本文链接











 关于 LearnKu
关于 LearnKu




推荐文章: