
http 框架的路由实现原理
2 / 0 / 创建于 6年前 /
 RryLee 的个人博客
RryLee 的个人博客
前不久在golang API网关中自己实现了一个api路由,最近又有机会使用了python,所以有机会对这些实现进行一个对比。其次,以前也用过很多 php 相关的框架,在这篇博客中做一个总结对比。
Thinkphp
thinkphp 早期实现路由是通过请求 uri 和框架自定义的一套目录+文件类+类方法来实现的路由映射,除此以外,早期的php框架包括 ci,yii都有这种隐式路由的实现。(thinkphp 貌似也有自定义映射关系的实现,这里不做讨论)。
就拿 /api/user/get_user_info 这样一个获取用户信息的接口来说,在 TP 里面相对的会存在以下这样一个文件,同时 Controller 里面会有一个 getUserInfo 的方法。
Application/
├── Api
│ ├── Controller
│ │ ├── UserController.class.php实现过程分为以下几步:
- 解析到 url 为 /api/user/get_user_info
- 模块为 api,文件为
UserController,方法为getUserInfo
- 模块为 api,文件为
- 判断 Api 文件夹是否存在
- 判断
UserController.class.php是否为文件,然后require该文件 - 判断对应类方法是否存在,存在就调用。
可以看到,整个实现是通过框架对目录结构,文件命名等方式进行一个统一的约束,然后实现uri匹配的。整个过程存在着大量的系统调用,不过这也是脚本语言在web场景下无法避免的事情。
通过这种方式,可能是实现一个接口最快的方式,因为你少了去定义路由的过程,但不得不得说在 restful 和 api 的语义化上可能就不能很方便的定义了。以现在的眼光来审视这些实现,可能会觉得太low,不屑一顾,不过当时解决了那么多人在web开发的问题,国内无数的商业公司在使用,足以说明他是一个牛逼的框架(这里我只是说点废话,TP已经足够好了,也不需要我的评判)。
Laravel
在过去很长很长的一段时间,我都在使用 laravel 进行开发,目前 laravel 已经成为了整个 php 生态圈最活跃,最优秀的框架之一了,在代码的架构上足够模块化,第一次接触你可能多会感叹,“哇,原来php也能写出这么优秀的代码”。整个 laravel 的源码我曾经也通读过一篇,很多日常开发中的思想和套路都是来自于此。
laravel 的 api 实现足以支持 restful 你所需要的全部功能,由于 php 每次处理请求都是一个 runtime,不可避免的也是需要像 tp 一样做很多文件加载的操作。laravel 的路由是可以进行单独定义的,类似 flask 的 get post…,或者 spring 中的注解,这些注册的接口会被添加进入一个集合。
这个集合第一层的 key 以 http method 作为入口,也就是区分不同的方法。拿 /api/user 这个接口为例子
routes: array:3 [▼
"GET" => array:1 [▼
"api/user" => Route {#114 ▶}
]
"HEAD" => array:1 [▼
"api/user" => Route {#114 ▶}
]
"POST" => array:2 [▼
"api/user/{id}/edit" => Route {#112 ▶}
]
]其实看到这里就比较清楚了,整个路由的匹配过程第一步就是获取到对应的请求方法的 Route 数组,然后对数组依次进行匹配。不过 laravel 讲匹配过程拆分为四个部分:
- 匹配 uri
- 匹配 method (laravel 有防止代理层修改 method,这里其实用 method 做了一层兼容,正常情况第一步就匹配过 method 了,不需要考虑这一部分)
- schema 匹配,http和https
- host 匹配,laravel 提供绑定域名的功能
相对来说,2,3,4都是很好理解的,这里重点看看 uri 是怎么匹配的,不过答案也只有一句话
每个route的uri匹配会编译为一个正则表达式
考虑到这个性能消耗,laravel 也只会循环到被匹配的 route 才会进行编译。
所以 laravel 做了一个路由缓存的优化,你可以手动的进行编译,laravel 会把你所有注册的 uri 全部序列化到一个文件中(这一步当然也包括正则表达式的编译),之后每次请求都直接反序列化这个路由文件,然后进行 uri 匹配。
php 其他框架
又参考了包括 FastRoute 等其他 php 中比较小,性能好的框架,基本上都是通过正则表达式进行匹配。
go httprouter
从算法上来说,httprouter 是通过前缀树来进行匹配的,前缀树相比基础的字典树来说,在匹配很长的字符串上有更好的性能,所以更适合 uri 的匹配场景。
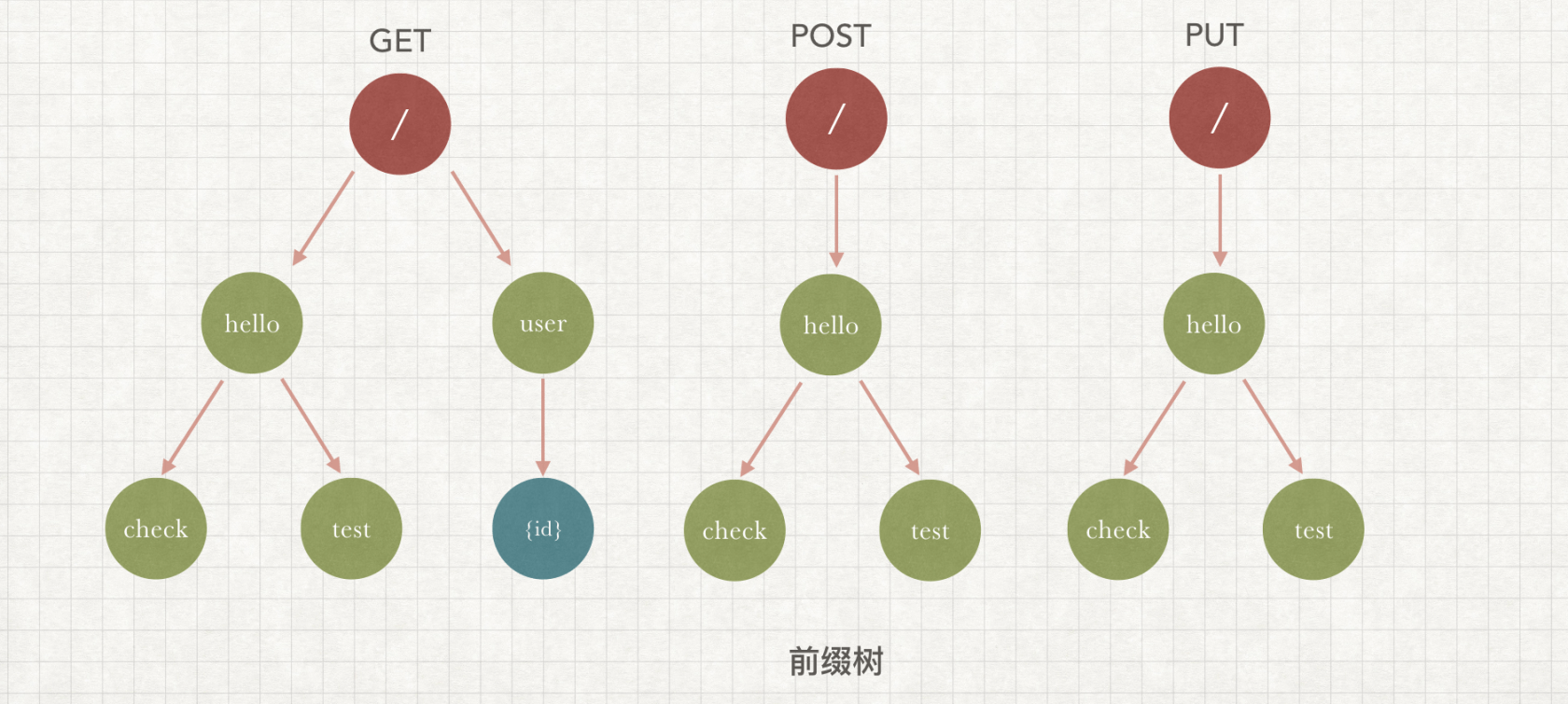
简单的来说每一个注册的 url 都会通过 / 切分为 n 个树节点(httprouter 会有一些区别,会存在根分裂),然后挂到相应 method 树上去,所以业务中有几种不同的 method 接口,就会产生对应的前缀树。在 httprouter 中,节点被分为 4 种类型:
- static - 静态节点,
/user/api这种 - root - 根结点
- param - 参数节点
/user/{id},id就是一个参数节点 - catchAll - 通配符
其实整个匹配的过程也比较简单,通过对应的 method 拿到前缀树,然后开始进行一个广度优先的匹配。
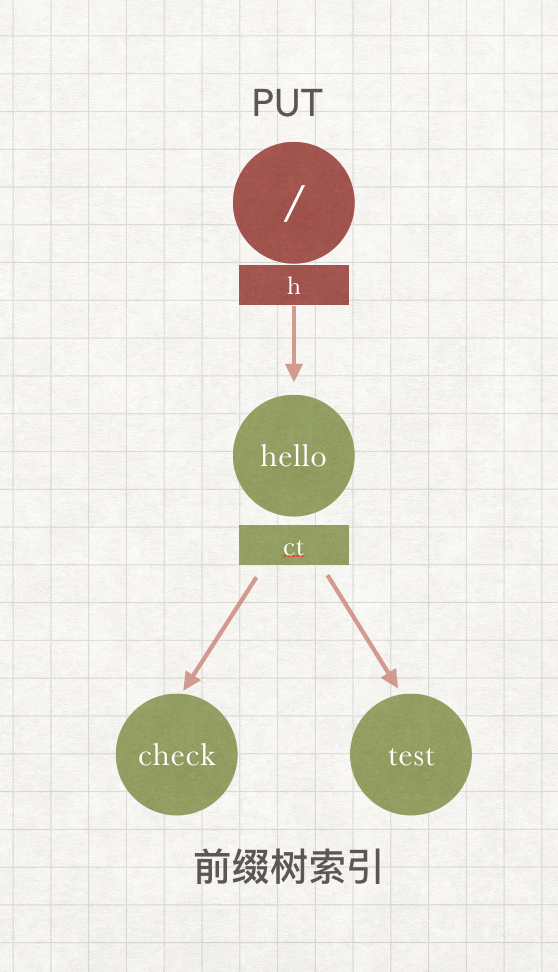
这里值得学习的一点是,httprouter 对下级节点的查找进行了优化,简单来说就是把当前节点的下级节点的首字母维护在本身,匹配时先进行索引的查找。
API proxy
这里所指的
proxy是最近开发的一个网关。
作为一个 api proxy,转发所有的请求到目标服务,请求进入之后就需要进行 api 的匹配。这个匹配规则和 httprouter 差不多,所有的 api 都会构建在一棵前缀树上,和 httprouter 的按照 method 划分不同,method 属性会在每一个 node 上面。
Python
因为使用的是 tornado 框架,所以只看了这个框架的实现,再加上 tornado 作为一个高性能的异步 HTTP 服务器,所以期待能不能收获到一些新的细节。最后大概浏览了一下,也是使用正则表达式做的匹配。
说在最后
不管动态语言,还是golang这种需要编译的语言,在路由的实现上都大同小异,最大的区别可能就是对参数定义支持到不同的程度,某些框架可能你可以定义出及其复杂规则的 url。回归到业务,我呆过的两家大公司,基本上都是 post 请求一把锁,当你考虑到 restful 的定义是否合理可能和每个人的水平有关,restful 接入方也会有额外的成本,所以很多情况下大家还是会使用 post 请求来完成你业务中绝大部分的事情。
最后欢迎大家关注我的公众号
本作品采用《CC 协议》,转载必须注明作者和本文链接







 关于 LearnKu
关于 LearnKu




推荐文章: