
Laravel 中间件实现原理
4 / 2 / 创建于 6年前 /
 Remember 的个人博客
Remember 的个人博客
开篇介绍
这两天对 Laravel 中间件极其感兴趣,索性花时间看了几篇深度好文,结合着底层的源码。虽然中间件源码的分析文章已经很多了,但是也有必要根据自己的理解写篇文章,加深印象。文章的最后,会放上相关的文章链接,因为这里面很多都是在他们文章的基础上理解的。
故事的开始
先不着急着分析源码 ps:前戏得足 我们需要模拟出一个场景带入。假设我们现在需要计算这样的一个值,后面的结果都依赖于前面计算的值,现在我就是要通过中间件去实现这个功能。
为了减少计算量,这里我们主要看E这个计算公式部分,我们把整个E 也看成4个部分,1+增值税税率(即count1),1/count1(即count2),count2 * 核定应税所得率(即count3) 以及 count3 * 倒算适用表税率(即count4).
场景出来了,我们创建四个类,分别代表4个中间件,count1……,这里我们再强行制造一个场景,我们在计算 count3 的 时候,需要依赖于 count4 的计算结果,但是由于某些不可描述的约束,count3 又必须在 count4 之前进行一些条件的验证,也就是说 count3 的中间件走在 count4 的前面,但是计算却要依赖 count4 的结果处理。然后我们创建了四个类,把上面的四个步骤计算分别放入到这四个类中,我们也和平时使用中间件一样,增加一个 handle() 方法。
class Count1
{
public function handle($value, \Closure $next)
{
$value += 1;
var_dump('count1计算出来的值:' . $value);
if ($value < 0) {
return "系统异常";
}
return $next($value);
}
}class Count2
{
public function handle($value, \Closure $next)
{
$value = 1 / $value;
var_dump("count2 计算出来的值:$value") . PHP_EOL;
return $next($value);
}
}class Count3
{
//核定应税所得率依赖于后面的结果
public function handle($value, \Closure $next)
{
$res = $next($value);
var_dump("核定应税所得率收到的结果:$res") . PHP_EOL;
return $res* 0.5;
}
}class Count4
{
//倒算税率值0.5
public function handle($value, \Closure $next)
{
$value *= 0.5;
var_dump("倒算税率值计算后的值:$value") . PHP_EOL;
return $next($value);
}
}Pipeline 组件
Laravel 中间件处理的核心就是 Illuminate\Pipeline 这个组件类,在了解这个类之前,我们先看看中间件在 Larave 中扮演的角色。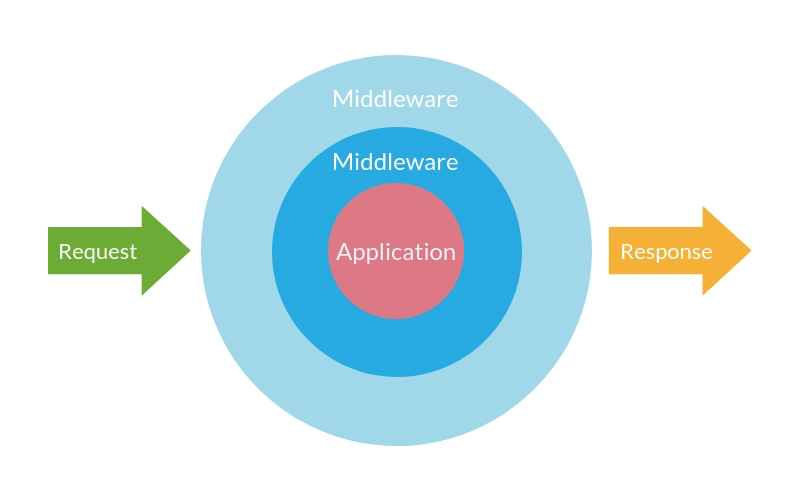
在到达 Application 之前的中间件是前置中间件,比如一些验证 csrf,判断是否登录,是否有权限。在 Application 之后的是后置中间件,就是格外的处理一些逻辑,比如给响应添加请求头,cookie……。
你看上面的类格式是不是很像你们平常写的中间件代码。唯一不同的是,我们现在不走路由或者其他方式走中间件,而是直接把底层处理中间件的 Pipeline 类(一般说管道)拿出来,执行代码。我们运行实验类的 test 方法
public function test()
{
$pipes = [(new Count1), (new Count2), (new Count3), (new Count4)];
$this->dispatcher(1, $pipes);
}
//count4 算完之后的处理 处理结果返回到count3
public function additionalHandle()
{
return function ($value) {
return $value < 0.1 ? $value : $value * 0.5;
};
}
public function dispatcher($value, $pipes)
{
$result = (new Pipeline)->send($value)->through($pipes)->then($this->additionalHandle());
echo "最终结果: " . $result;
}
这个流程中,先实例化了 Pipeline 类,调用send 方法,传入我们初始化的值,也就是1,赋值给变量passable, 返回本身,继续调用 through, 定义的四个中间件类赋值给变量 pipes,然后继续调用 then,该方法需要传入一个闭包函数。这个闭包函数就是上面的 additionalHandle 函数返回的闭包。我们再来看结果,先经过前置中间件 count 1,2,4,到达另类的 Application,到达这里后,我们开始响应了,把结果返回给后置中间键 count3 进行计算,count3 前面已经没有其他的后置处理了,最终由 count3 返回最终的结果。最终结果:
有注意到在count1 中的一个判断吗
我们现在传入 -2 ,然后打印结果
这样的话,不满足条件,就再也进不了下一层(前置)中间件了。
我们可以开始分析源码,试着去找出 Laravel 是如何优雅的实现这个流程的。直接查看 then
public function then(Closure $destination)
{
//$destination 就是我们传入的additionalHandle返回的闭包
// return function ($value) {
// return $value < 0.1 ? $value : $value * 0.5;
// };
// $this->>pipes 就是传入中间件count1 2 3 4
$pipeline = array_reduce(
array_reverse($this->pipes), $this->carry(), $this->prepareDestination($destination)
);
//$this->passable 就是$value值,初始的时候传入的是1
return $pipeline($this->passable);
}处理的核心就是在这行代码里面了,在继续分析代码之前,我们有必要了解一下 array_reduce 这个函数。可以说,Laravel 中的中间件完全依赖于这个函数。
array-reduce 函数
本来想想还是直接用一句:这个函数具体使用去查看文档,问了就是查文档。但是因为这个函数的重要性,还是写个没有 变异的案例吧。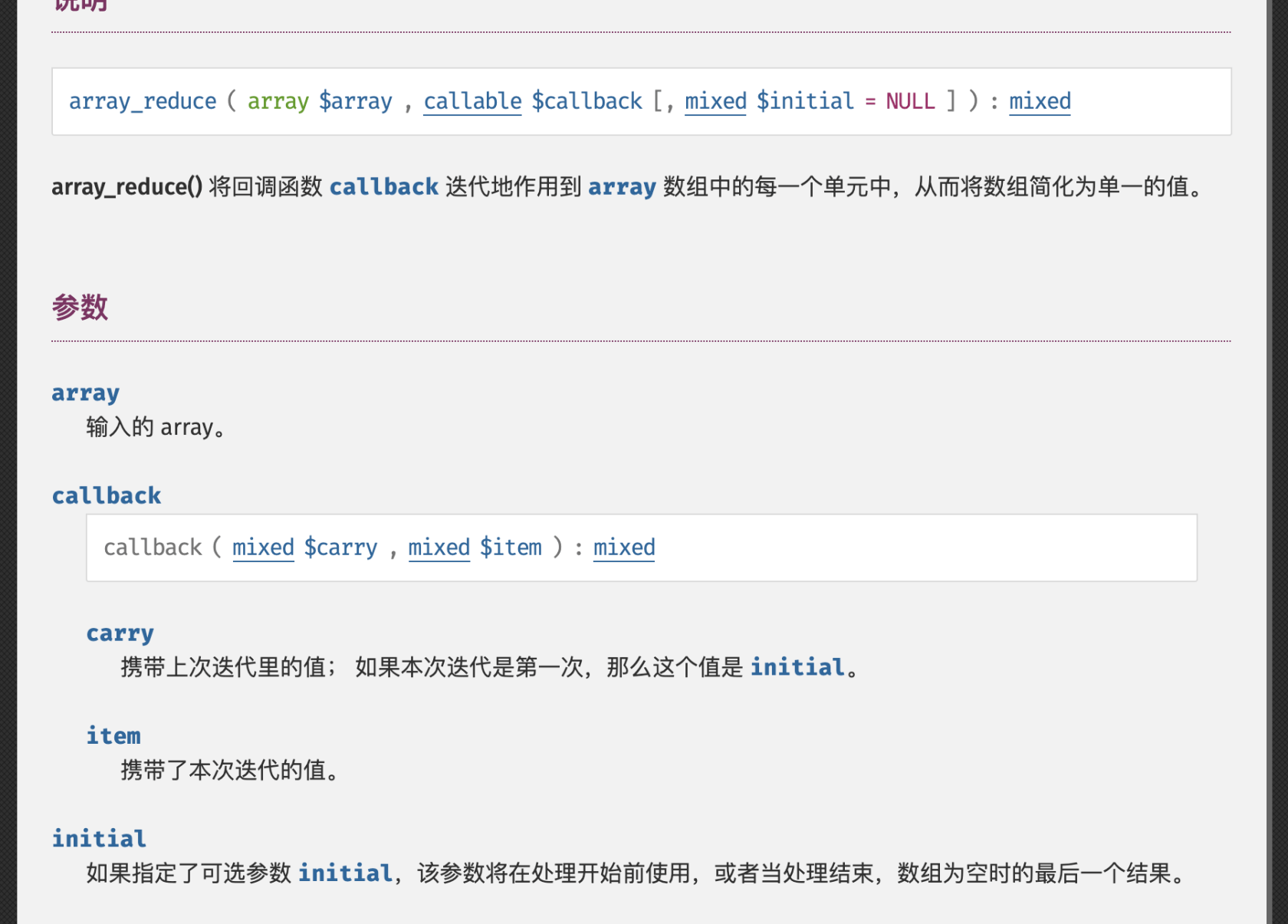
假如我们需要把数组里的数求和
$data = [1, 2, 3, 4];
$res = array_reduce($data, function ($carry, $item) {
return $carry + $item;
});
var_dump($res).PHP_EOL;
//有初始值5,那么传入第三个参数
$res = array_reduce($data, function ($carry, $item) {
return $carry + $item;
},5);
var_dump($res);
够简单了吧。稍微了解一下 array_reduce 函数我们可以往下走了。我们重新回到之前的这段代码:
$pipeline = array_reduce(
array_reverse($this->pipes), $this->carry(), $this->prepareDestination($destination)
); 现在你已经知道三个参数在函数中的含义了。 array_reverse 会将我们定义的四个中间件全部通过 carry 函数处理 。我们来看看carry 方法里面是啥。
/**
* Get a Closure that represents a slice of the application onion.
*
* @return \Closure
*/
protected function carry()
{
return function ($stack, $pipe) {
return function ($passable) use ($stack, $pipe) {
if (is_callable($pipe)) {
// If the pipe is an instance of a Closure, we will just call it directly but
// otherwise we'll resolve the pipes out of the container and call it with
// the appropriate method and arguments, returning the results back out.
return $pipe($passable, $stack);
} elseif (!is_object($pipe)) {
list($name, $parameters) = $this->parsePipeString($pipe);
// If the pipe is a string we will parse the string and resolve the class out
// of the dependency injection container. We can then build a callable and
// execute the pipe function giving in the parameters that are required.
$pipe = $this->getContainer()->make($name);
$parameters = array_merge([$passable, $stack], $parameters);
} else {
// If the pipe is already an object we'll just make a callable and pass it to
// the pipe as-is. There is no need to do any extra parsing and formatting
// since the object we're given was already a fully instantiated object.
$parameters = [$passable, $stack];
}
return method_exists($pipe, $this->method)
? $pipe->{$this->method}(...$parameters)
: $pipe(...$parameters);
};
};
}可以看到,最终运行返回的是一个闭包函数,引用了外部的两个变量,stack和 pipe。其中 $stack 第一次执行的时候,它的值就是定义的additionalHandle 方法中返回的闭包函数(注意:此时并不是真的执行闭包函数里面的逻辑)。第二次执行的时候就是第一次执行返回的闭包函数,第三次执行的时候…..以此类推。
至于 pipe 则是每次迭代时的中间件类,第一次就是上面定义的 count4 ? 为什么不是count 1,因为使用了 array_reverse 函数。有人会说,这个 carry 好复杂啊,迭代的时候我的脑子想下面的运行逻辑根本就想不下去。其实,在执行 array_reverse 函数的时候,你完全不用考虑下面的逻辑🙅♂️,每次迭代的时候仅仅只是返回一个变量,只是这个变量有点特殊,是个闭包函数。并不是直接执行里面的逻辑,等到真正调用这个变量(闭包函数)的时候才执行代码。我们来看一个简单的不能再简单的例子:
$res = function ($item) {
return $item * 10;
};
这个变量的值会是2吗?不会。它的值就是一个闭包函数,引用了一个外部的变量。既然值是闭包函数,那我可以调用吧:
$res(3)这时候才是真正执行闭包函数的时候,传入了一个环境变量3,执行闭包函数的逻辑,得到结果。
好了,现在我们可以知道array_reverse 函数运行的整个流程。
第一下迭代:
$stack就是我们定义的additionalHandle闭包函数。pipe就是第一个中间件count4,
第二次迭代:$stack是第一次执行返回的闭包函数,pipe是count3中间件
第三次迭代:$stack是第二次执行返回的闭包函数,pipe是count2中间件
第四次迭代:$stack是第三次执行返回的闭包函数,pipe是count1中间件
现在迭代完毕,即 array_reverse 函数执行完毕,结果就是得到第四次迭代返回的闭包。然后运行这个闭包:
//$this->passable 就是$value值,还记得我们上面传入的是1
//$this->dispatcher(1, $pipes);
return $pipeline($this->passable);此时当前闭包 use 的就是 count1 这个类,然后我们可以开始看闭包里面的逻辑了,有三个分支
if (is_callable($pipe)) {
return $pipe($passable, $stack);
} elseif (!is_object($pipe)) {
list($name, $parameters) = $this->parsePipeString($pipe);
$pipe = $this->getContainer()->make($name);
$parameters = array_merge([$passable, $stack], $parameters);
} else {
$parameters = [$passable, $stack];
}对于我们现在的场景来说,走的是 else 分支。把初始值以及上一次迭代返回的闭包都存入parameters 数组中。 为什么是走 else 分支,还记得我们这个示例是咋么操作的嘛:
$pipes = [(new Count1), (new Count2), (new Count3), (new Count4)];
$this->dispatcher(1, $pipes);此时的 pipe 已然是个对象不需要去解析,前面的分支都和他没关系。继续往下走。
return method_exists($pipe, $this->method)
? $pipe->{$this->method}(...$parameters)
: $pipe(...$parameters);/**
protected $method = 'handle';现在知道为什么你的中间件默认都需要 handle 方法了吧。查看类中的 handle 方法。
public function handle($value, \Closure $next)
{
$value += 1;
var_dump('count1计算出来的值:' . $value);
if ($value < 0) {
return "系统异常";
}
return $next($value);
}现在是到了第一个中间件核心处理的地方了,先简单的对变量进行处理,然后增加了过滤条件,如果不符合,直接打回去,这样就进不了下一层中间件了。也就是一开始说的那个demo。如果要进入下一个中间件,那么就必须执行:
return $next($value);为什么?因为上面说的 parameters 变量除了存储初始值之外,还存储了上一次迭代返回的闭包函数,此时你想进入下一层中间件,那么就必然要执行这个闭包函数,那为什么要 return ,这就是中间件的模型了,前置中间件处理完之后,到达 Application 然后开始执行后置中间件,一层层返回了。假设我们把 count 4 的 return 去掉,你应该能理解了吧。
class Count4
{
//倒算税率值0.5
public function handle($value, \Closure $next)
{
$value *= 0.5;
var_dump("count4 倒算税率值计算后的值:$value") . PHP_EOL;
$next($value);
}
}
写到这里,也就分析的差不多了,一个小小的 array_reverse 函数,竟能玩出花。不得不佩服底层设计的巧妙。
结尾
最后,我很赞同 chongyi 在他的那篇文章说的一句话:要知道,再强大的 PHP 框架都是用 PHP 写出来的,本质上依旧是在一个大的基础上构建小型世界。
以下是我参考的文章链接:
博客:[单篇] Laravel Pipeline 组件的实现原理
博客:Laravel 管道流原理
本作品采用《CC 协议》,转载必须注明作者和本文链接












 关于 LearnKu
关于 LearnKu




推荐文章: