
easycar 一个用go实现的分布式事务框架
0 / 0 / 创建于 3年前 /
 Remember 的个人博客
Remember 的个人博客
easycar是什么
easycar 是一个用go实现的支持两阶段提交协议的分布式事务框架。目前还只支持TCC,SAGA 模式,其他模式待开发。
在介绍easycar 之前,先简单介绍几个角色。
Transaction Coordinator(TC)
负责全局事务的管理,所有参与分布式事务的分支都会注册到coordinator,回给每个分布式事务分配一个唯一id,
当然还包括驱动全局 begin / commit /abort(我喜欢称rollback)。
Transaction Manager (TM)
有些时候也叫 Transaction Client,当然不同的实现也许都会换个名字,但是职责都大差不差。
一般通过TM对每个参与的RM发起一阶段的请求,如果一阶段的RM全部成功,那么TM会向TC发起commit请求,否则发起rollback。
Resource Manager(RM)
用户维度的角色,管理本地事务处理的资源。其实你可以这么理解,假设你的订单服务部分接口参与了分布式事务,无论是第一阶段TM调用接口,还是TC第二阶段调用接口,你的订单服务都会去负责本地的事务修改。
那么 easycar 上述角色有什么不同吗?
有的。既然TC负责的就是全局事务的管理,那么我把职责都给了它。即由TC像每个参与的RM发起一阶段的请求,然后再根据一阶段的结果,发起二阶段的请求。由TC接管整个分布式事务的生命周期。
是的,我弱化了上面TM的能力。在我眼里,TM本质上就是一个客户端。客户端只需要做一些数据封装,简便化操作即可。所以即使没有客户端,其他语言的用户也可以直接通过http请求easycar服务接口。
架构图

服务注册与发现
由于easycar底层基于gRPC, 通过自定义Resolver接口还是很容易实现的。
负载均衡
客户端负载均衡,目前支持
round-robinrandompower of 2 random choiceconsistent haship-hashleast-load
easycar 特性
支持协议和事务模式同时混用
参与分布式事务的服务往往由不同的多个部门维护,或者部分新老项目交错,可能无法保证服务的协议是一致的。
另外,不同的服务所采用的事务模式具体是由:业务场景以及构造的成本来决定的。所以参与分布式事务之间所使用的事务模式不一定是统一的。
在这些基础上,easycar支持协议混用(目前支持http和原生的grpc服务),支持部分事务模式混用(目前支持TCC,Saga)。
支持并发执行
假如现在有 order,account以及stock三个服务。
由这三个服务组成一个分布式事务。 当用户下单时,需要经过这三个服务中内部一些接口(account 扣钱,stock减库存,order 创建订单)。
如果只是同步执行第一阶段,那么第一阶段总执行时间= (account+stock+order)。
很多场景下,分布式事务之间并不会存在执行依赖先后的关系。所以多个子事务一阶段可以同时并发执行。
流程就像这样:
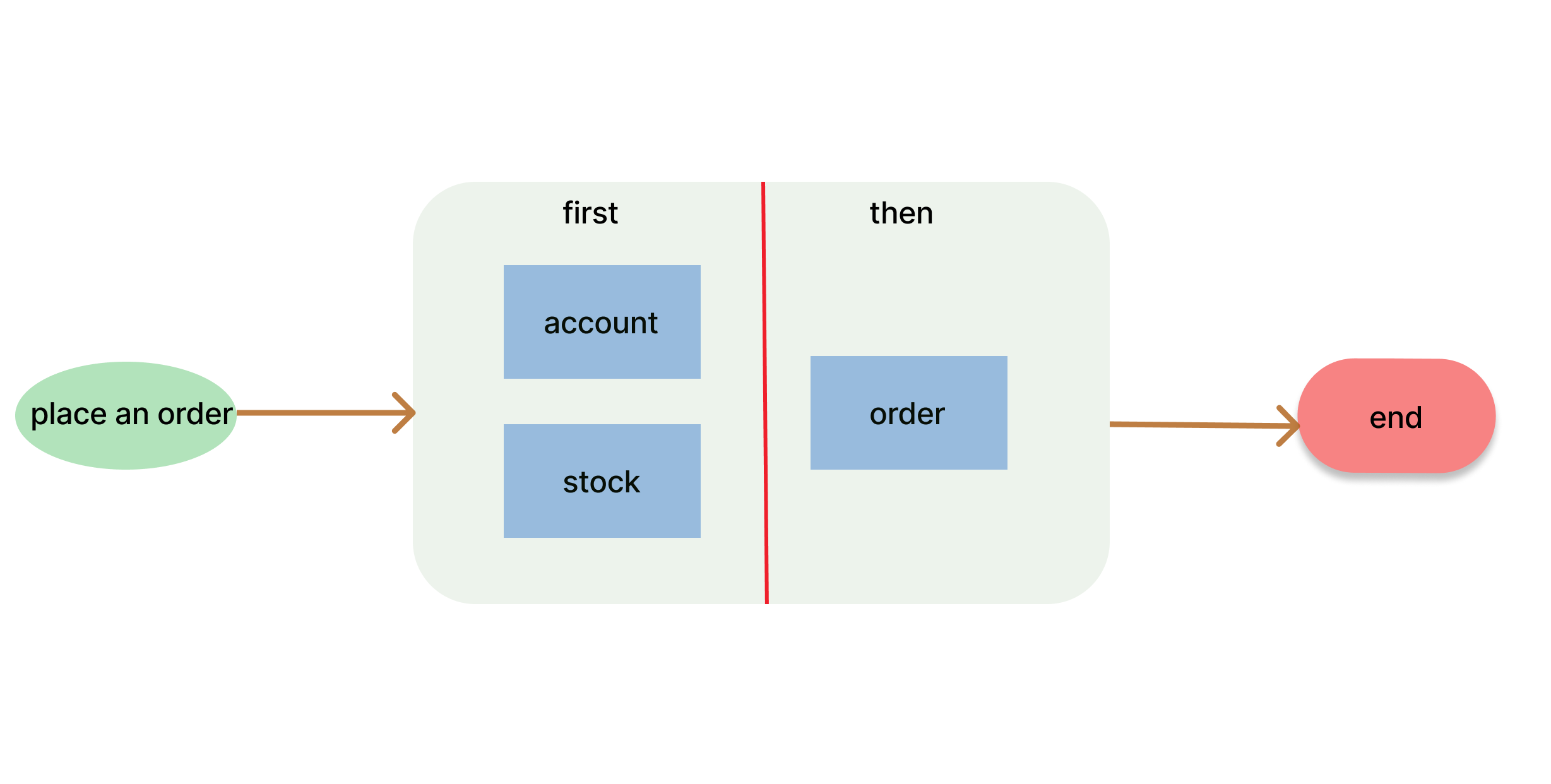
上图我们需要保证创建订单前必须先执行account扣减余额和stock扣减库存服务,才能创建订单order的服务。同时account和stock服务并不需要保证他们的执行顺序。
那么我们一阶段总执行耗时可以粗略=max(account,stock)+order。
因此,easycar是支持分层并发执行的。 对参与的RM通过设置的权重做分层,同一层的RM可以并发调用,一层处理完毕再接下一层。在这个基础上,当某个RM发生调用错误时,那么后面一层也不会执行了,整个分布式事务需要回滚。
异常处理
分布式事务中会出现一些问题,比如
空补偿: Cancel请求到来时,Try还没有执行,这时候这样的请求我们不能执行,理应直接返回。
悬挂: Try执行时,Cancel已执行完成,不能执行,直接返回。
幂等: 所有操作的接口都存在这个问题。
这些问题需要用户自己去解决,框架不会自动帮你处理。
在我看来,这些问题本身就是服务的必要工作,而不是通过外部服务来帮你保证。
换句话说,前端说它参数做了校验,难道后端就不校验接口了吗?
重试
我眼中的重试有两种模式:同步和异步。
同步的意思是说,当请求RM服务发生错误的时候(网络、服务本身挂了、或者服务里的中间件挂了),通过固定次数固定时间重试,这个时间通常很短,比如一秒。问题是服务挂的情况下,短时间大概率好不了,重试几乎可能是无用功。整个过程,客户端是阻塞等待的,白白耗费时间。
异步重试采用指数退避算法之类的逻辑,比如第一次重试1分钟后,第二次2分钟…..,限制一个上限值,比如最多延迟一个小时还是不行的话,那只能发告警,线下处理了。
这样的弊端是,
首先用户不能实时获取本次分布式事务结果了(正在重试中),只能等到真正执行完毕的时候通过回调的方式异步通知用户分布式事务最终结果。
退避时间越长,就意味着数据不一致的时间越长。但是如果人工直接干预又存在极大的风险。比如在你人工干预的同时,正好逻辑已经开始执行了,可能会造成新的数据不一致。
目前easycar 采用的是指数退避算法,当达到一定重试次数依旧失败,那么由人工去处理。
流程例子
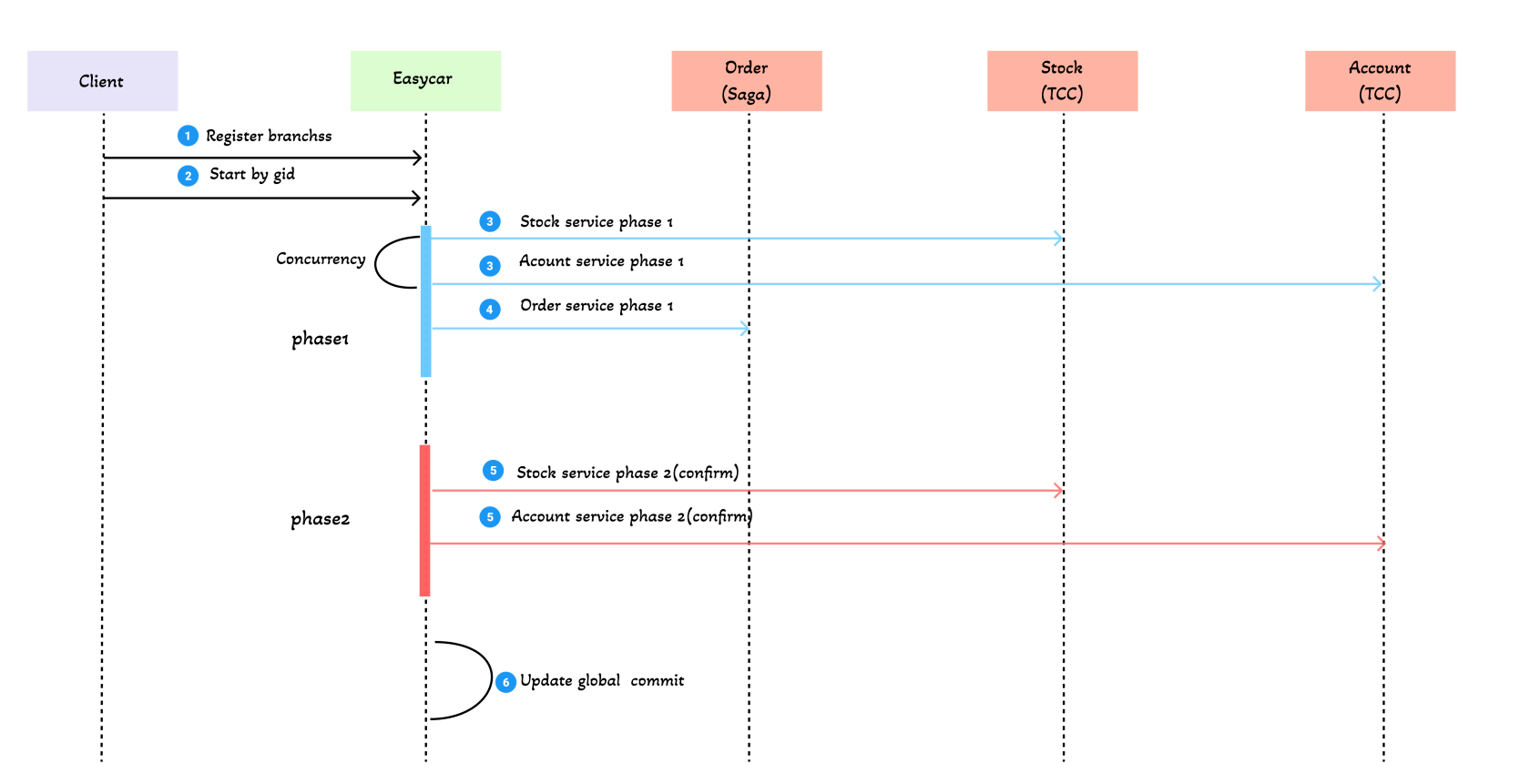
上面我们举了一个支持并发执行的例子,以这个例子,那么实际在easycar中整个流程。
成功
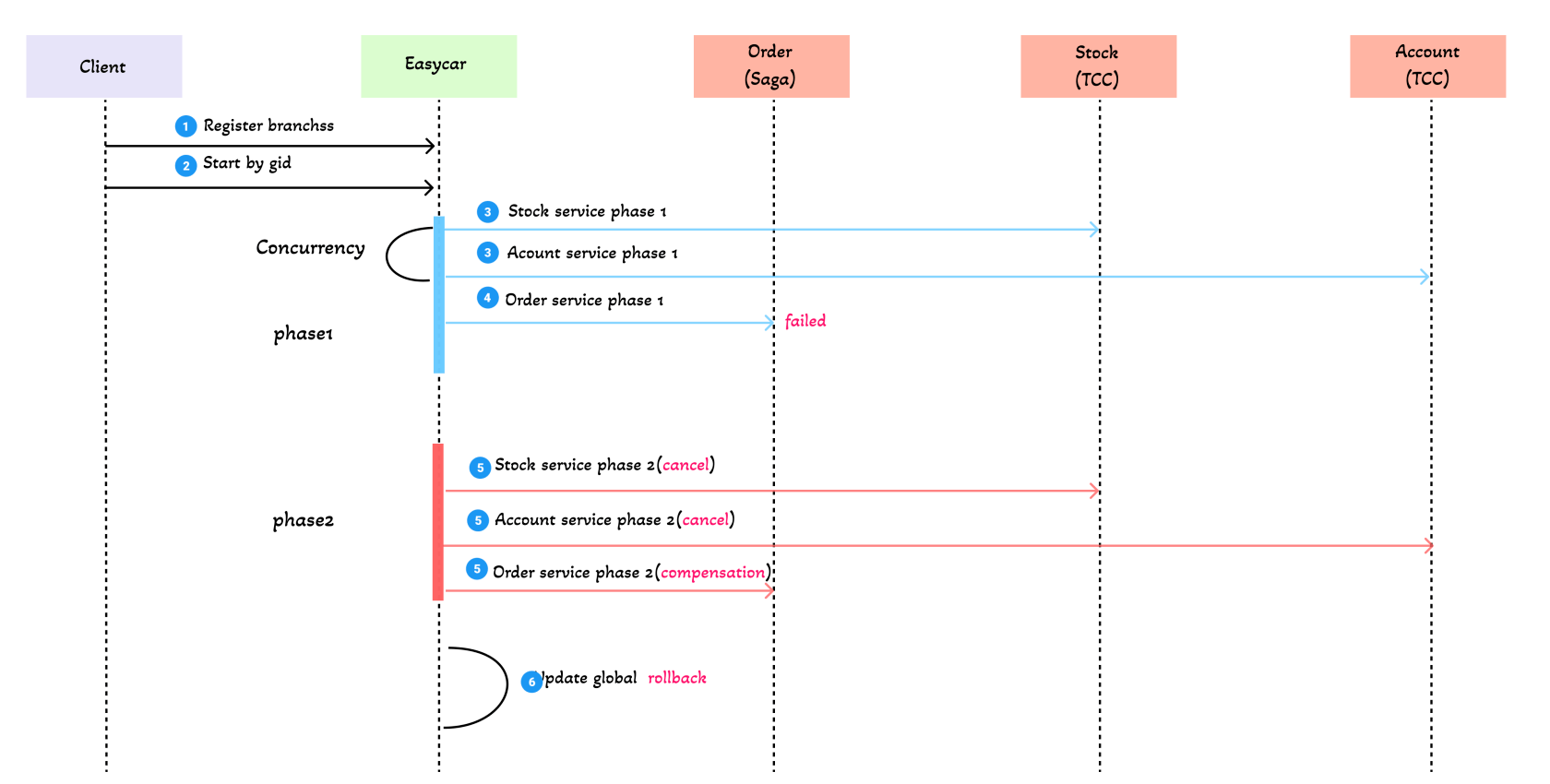
失败
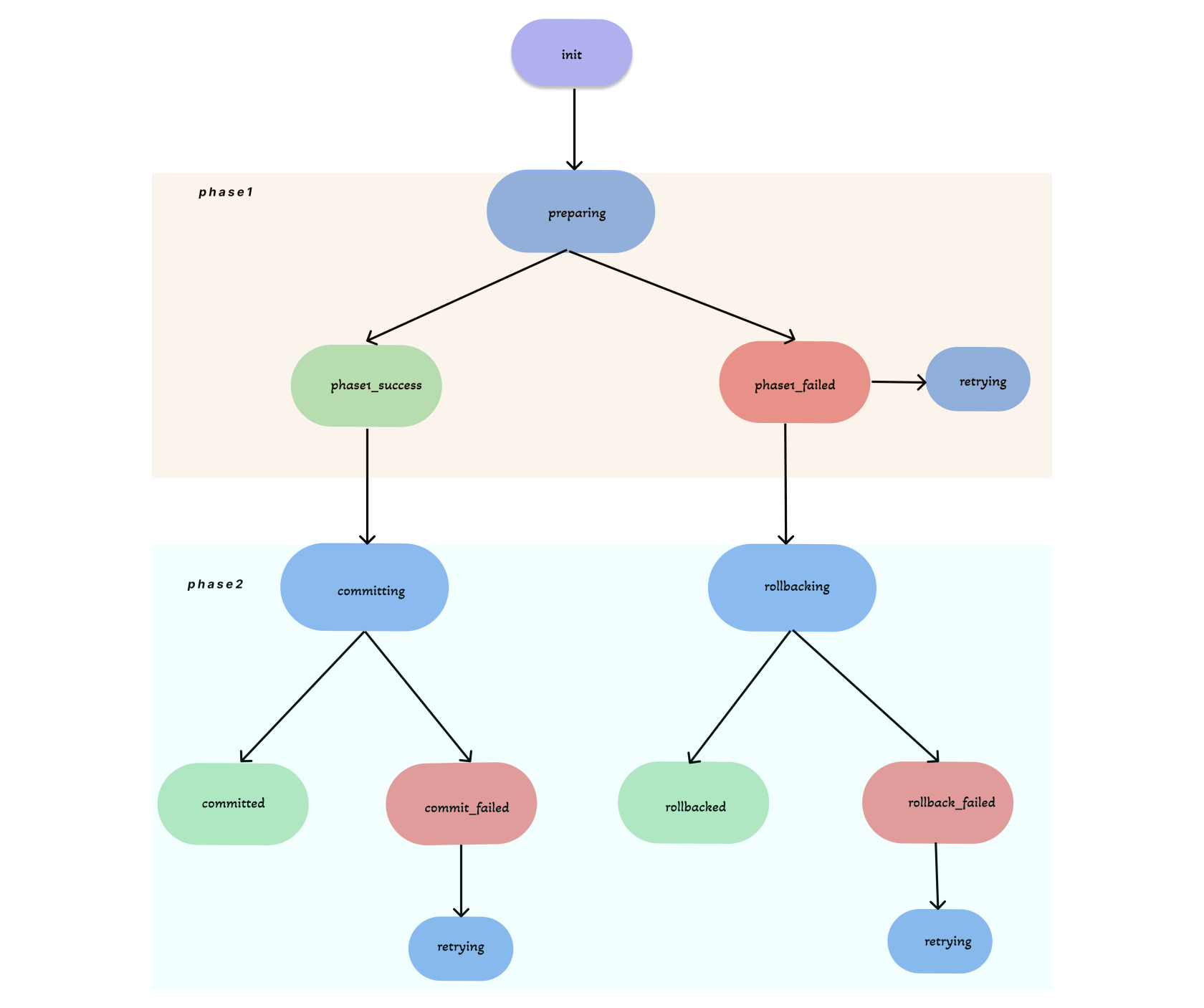
分支状态
项目地址: easycar ,觉得不可以点个star😌。
最后
easycar 开发不是很久,它还有好多工作需要去完成。感兴趣的可以一起加入。
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu




推荐文章: