
py 爬取某网站直播集锦-抓取组装得到二级详情页 url-现场敲代码
0 / 0 / 创建于 6年前 /
 wangchunbo 的个人博客
wangchunbo 的个人博客
斗争
抓取到了页面后,发现无法匹配条件。
最终 经过排查发现,网站 在第一次加载时候,你点击完赛Tab,他有ajax请求。
后面就木有请求了!
所以 ,我找到 接口了!!
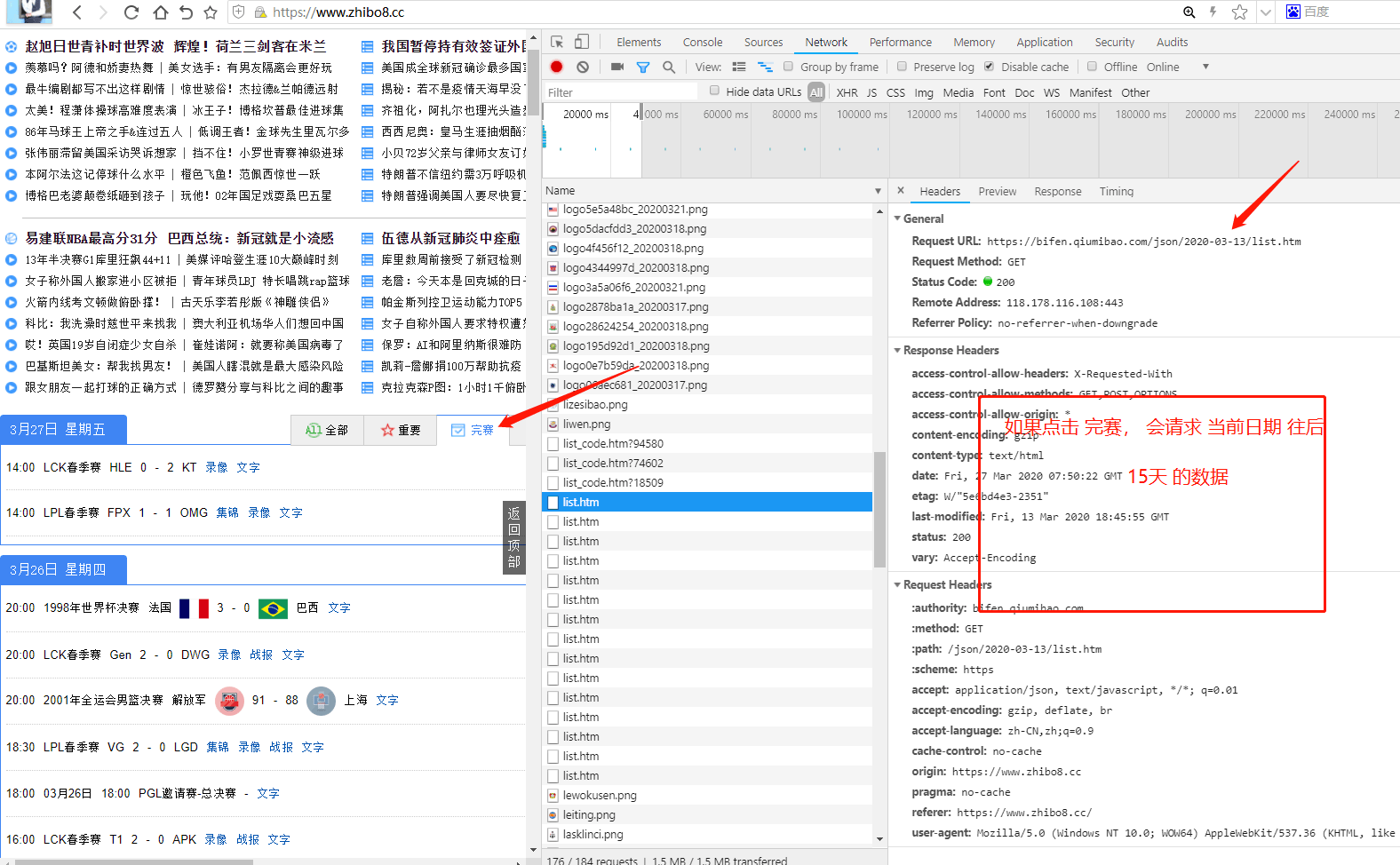
怼接口噻!
再次更好request 请求方式
ps
第二章,正在更新。日常踩坑,规则貌似看的不对。 他最终还是被我找到了 ajax 请求!
分析 接口规则
接口都是 日期 规则的。
'https://bifen.qiumibao.com/json/' + date + '/list.htm'
那我们只需要 把date 处理好,即可生产我们需要的url。
由 network 可见, 他是取了 前15天的 date。
但是,我们提前已经知道了,自己的日期条件,主队,客队。
所以 我们url 可以直接写死。
resp = get( 'https://bifen.qiumibao.com/json/' + date + '/list.htm')请求可以这么写,得到结果打印如下:
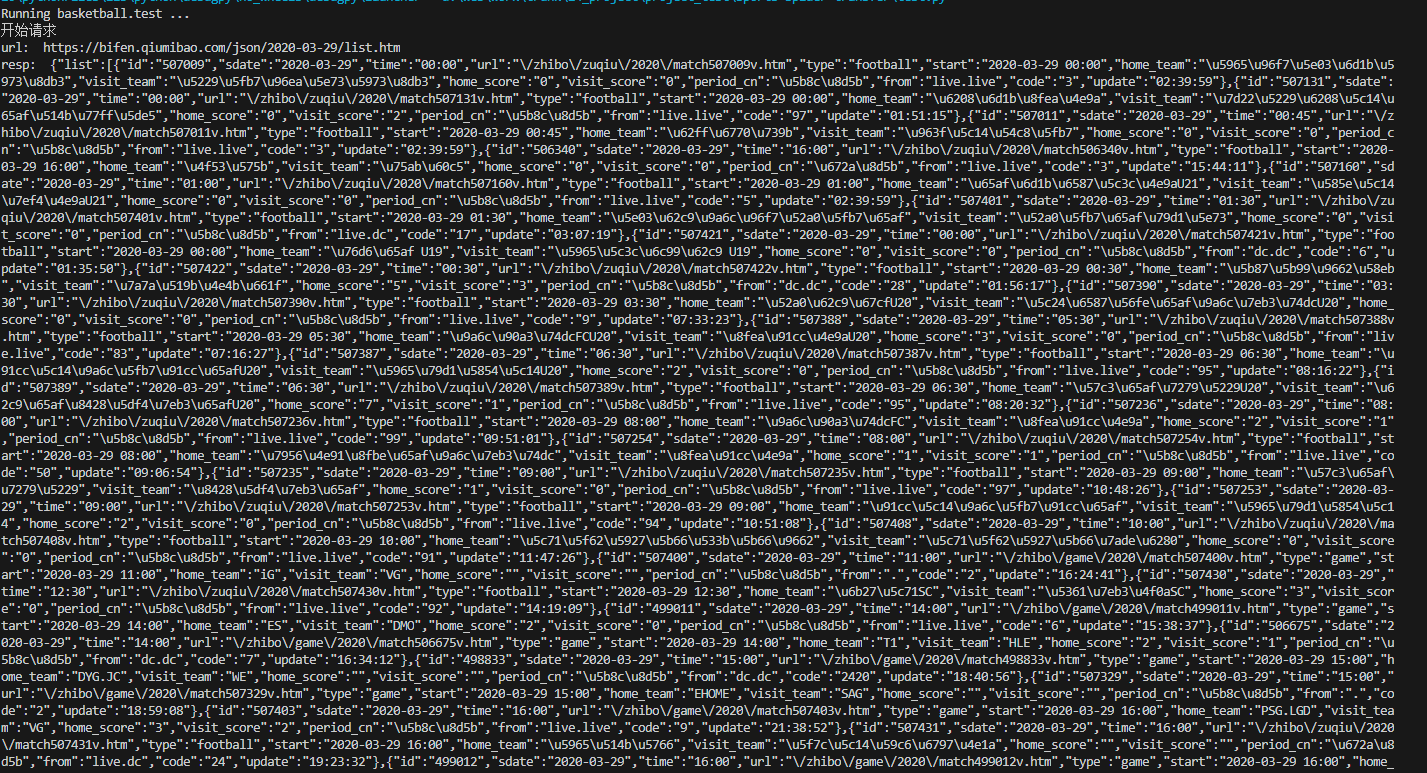
通过浏览器访问,这个组装好的url: https://bifen.qiumibao.com/json/2020-03-29...
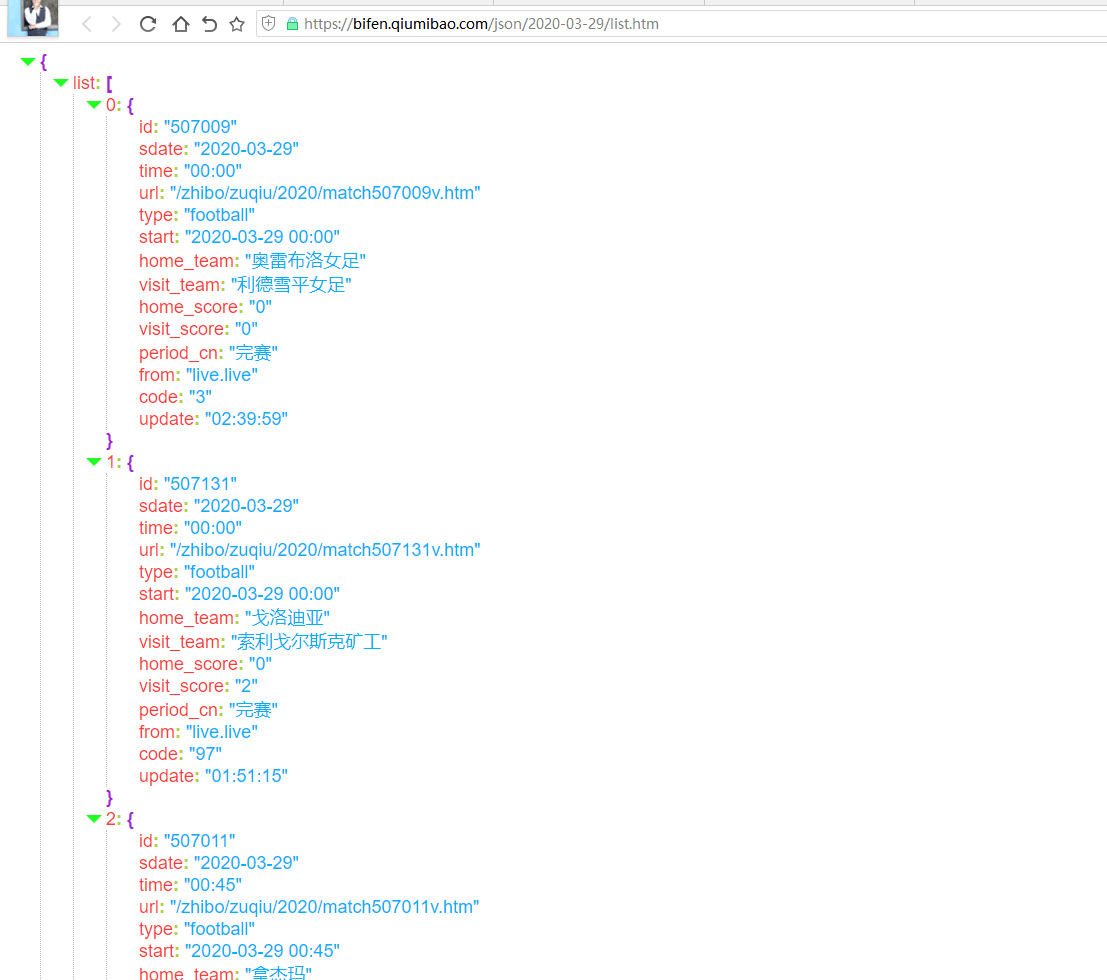
得到json 数据,我们通过匹配,找到我们的那一条。
匹配规则为: 开赛时间,主队,客队。
编写函数 matchName
# 外界传入json 此处进行匹配
# 返回查询到的json 数据 [] 格式
def matchName(resp,home_team,visit_team):
if resp is None:
return
# 得到了json
source = json.loads(resp)#字符串转json
source = source['list']
length = len(source)
matches = []
# 这里得到的是每一条的 list [{},{},{},{},{}]
for x in range(0,length):
# 在这里匹配每一条 中是否 有 我们的数据
if source[x]['home_team'] == home_team and source[x]['visit_team'] == visit_team:
# 匹配到了 就打印出来
url = source[x]['url']
start = source[x]['start']
matches.append(combineUrl(url,start,1))
matches.append(combineUrl(url,start,2))
# else:
# print('抱歉查询不到')
return matches
注意这个函数,我们取出来后,有一个combineUrl。
这是什么呢?
因为,我们直接拿到的json 中的 url 是不规范的。需要再写一个函数,来规范处理这个url
规范 组装详情页 url
我们先看看规范的url 应该是什么样子的?
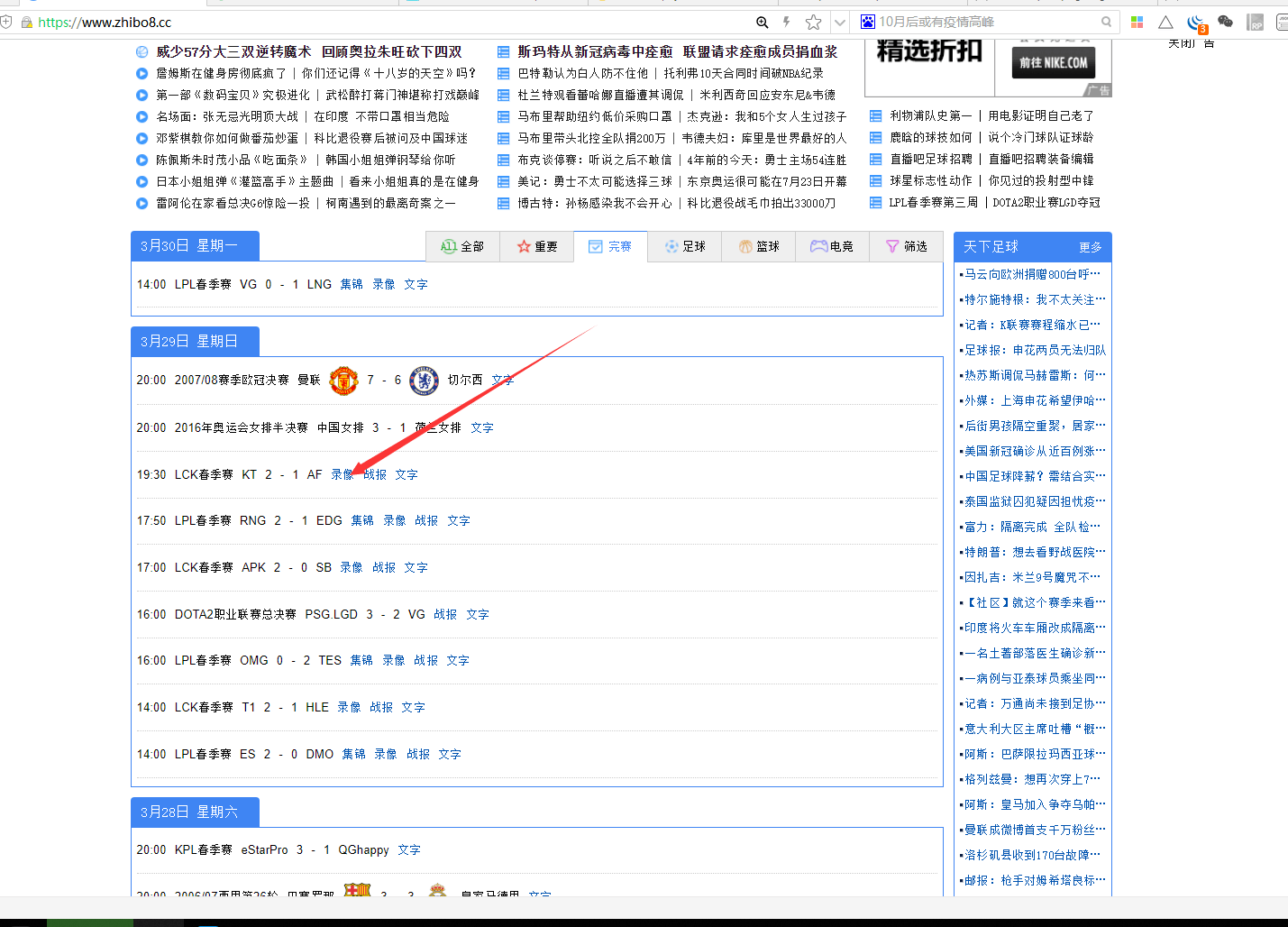
点开查看url:
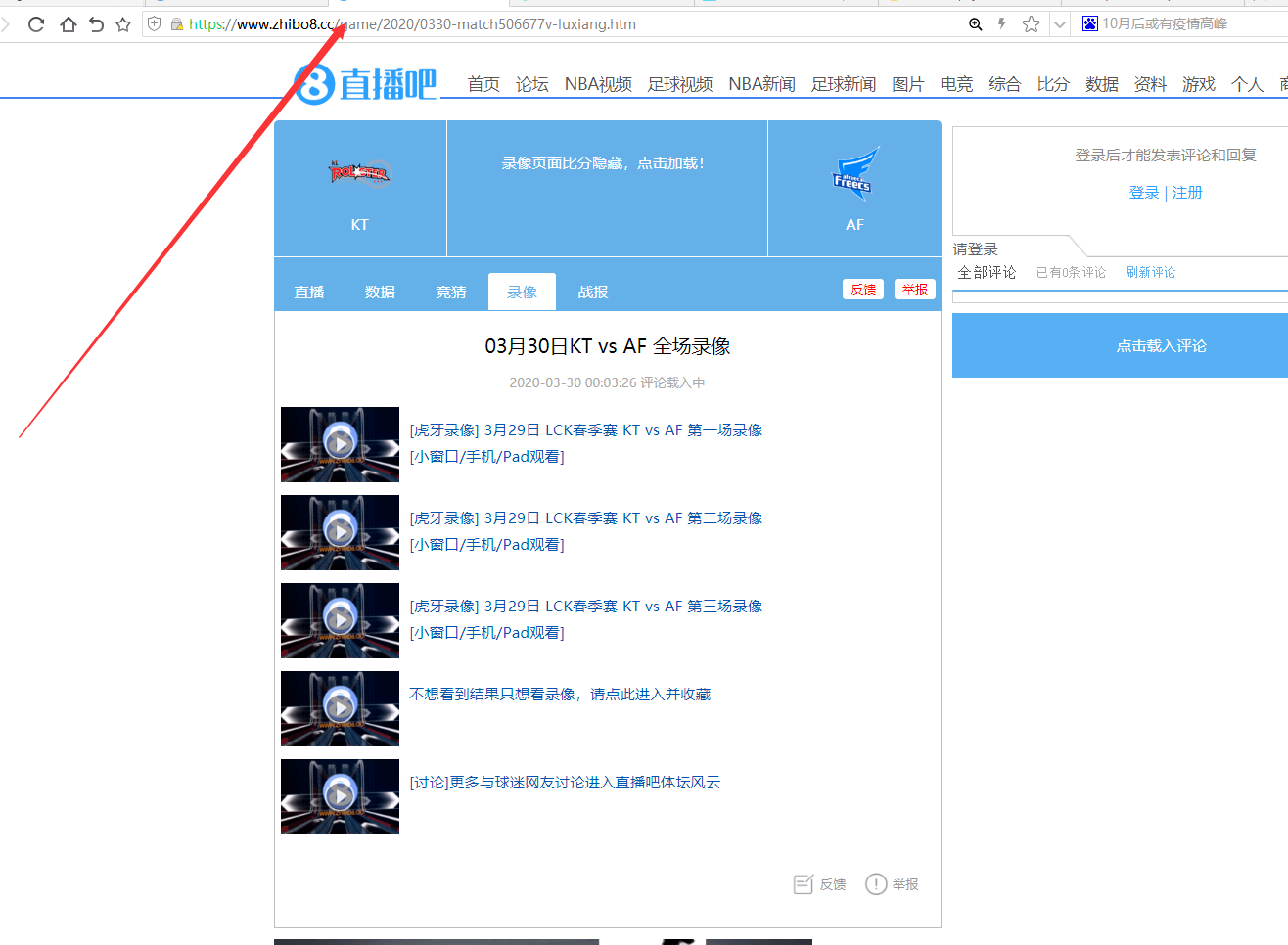
发现url,是组装为,game + 时间的形势,后缀为 jijin 或者 luxiang。
编写函数 如下:
# 处理url 函数
# 把 api 返回的url 组装为 可get 的url 录像 集锦
# type 1 集锦 2 录像
def combineUrl(url,start,type):
# 根据start 获取 当前的年份 与 月日
# 转为时间数组
# time.struct_time(tm_year=2020, tm_mon=3, tm_mday=29, tm_hour=17, tm_min=50, tm_sec=0, tm_wday=6, tm_yday=89, tm_isdst=-1)
# 切忌不能直接 读取,因为 出现01 03 之类的 月份 日期 就变成 1 或者 3了
startArray = time.strptime(start,'%Y-%m-%d %H:%M')
currYear = time.strftime("/%Y", startArray)
currDate = time.strftime("/%m%d-", startArray)
# 如果发现包含了 直播 就把zhibo 去掉
zhiboFind = '/zhibo'
url = url.replace(zhiboFind,'')
# 把 /match 换位 match
url = url.replace('/match','match')
# 找到 当前年份 把 /2020 年份替换为 /2020/0329-
url = url.replace(currYear, currYear + currDate )
prefix = 'https://www.zhibo8.cc'
combineIndex = url.find('.')
url_prefix = prefix + url[0:int(combineIndex)]
if type == 1:
url_suffix = '-jijin.htm'
else:
url_suffix = '-luxiang.htm'
return url_prefix + url_suffix最后 我们融合代码。一起来调用
# 直播吧 根据传入条件爬取 首页 完赛中 指定 比赛录像 集锦
# author bobo
# date 2020-03-27
def run():
# 第一: 从 redis 或者 数据库中 读出 条件。
date = '2020-03-29'
home_team = 'RNG'
visit_team = 'EDG'
# 第二: 请求 首页
# 设置ssl
# ssl._create_default_https_context = ssl._create_unverified_context
# 这里没有强验证,所以就先不写了
print('开始请求')
resp = get( 'https://bifen.qiumibao.com/json/' + date + '/list.htm')
# 下面 封装成函数 最后了
matches = matchName(resp,home_team,visit_team)
print('第一次得到的matches: ', matches)得到结果为:

总结
这里我们做了找到详情页的参数,以及组装url
下一节,我们讲,如何,请求爬取。详情页。
如图:
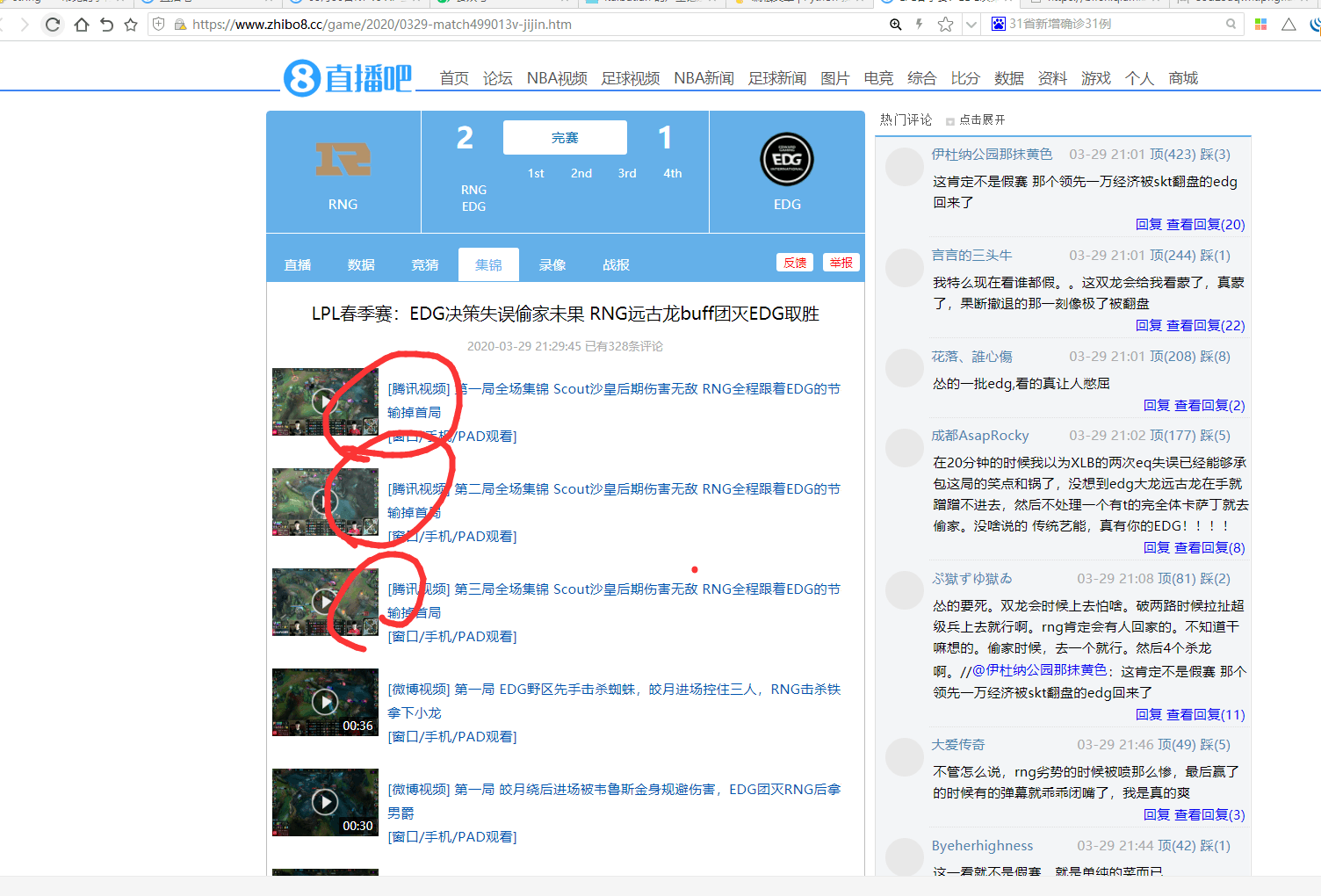
本作品采用《CC 协议》,转载必须注明作者和本文链接



 关于 LearnKu
关于 LearnKu




推荐文章: