
[面试题]跳槽面试必背-自己最近5年的整理,欢迎大家补充。
122 / 15 / 创建于 5年前 /
 wangchunbo 的个人博客
wangchunbo 的个人博客
波哥100问
1. 实现删除一个数组里面的重复值?
使用键值反转
array_flip();
<?php
$a1=array("a"=>"red","b"=>"green","c"=>"blue","d"=>"yellow");
$result=array_flip($a1);
print_r($result);
?>function unique3(array){
var n = [array[0]];//结果数组
//从第二项开始遍历
for(var i = 1; i<array.length; i++){
//如果当前数组的第i项在当前数组中第一次出现的位置不是i;
//那么表示第i项是重复的,忽略掉。否则存入结果数组。
if(array.indexOf(array[i]) == i){
n.push(array[i]);
}
}
return n;}2.什么是redis?
- 开源 先进的key-value存储
- 远程字典服务器 内存级数据库 数据结构服务器
- 一个基于内存的网络存储系统
3.redis数据类型有哪几种?
值(value)可以是:字符串(String),
哈希(hash),
列表(list),
集合(sets)
有序集合(sorted sets)
4.redis持久化是如何操作的?
为了保证效率数据都缓存在内存中,可以周期性写入磁盘或者把修改操作写入文件(持久化)。
RDB 持久化,将 redis 在内存中的的状态保存到硬盘中,相当于备份数据库状态。
AOF 持久化(Append-Only-File),AOF 持久化是通过保存 Redis 服务器锁执行的写状态来记录数据库的。相当于备份数据库接收到的命令,所有被写入 AOF 的命令都是以 redis 的协议格式来保存的。
5.redis适应的一些场景
1、取最新 N 个数据的操作
2、排行榜应用,取 TOP N 操作
3、需要精准设定过期时间的应用
4、计数器应用
5、Uniq 操作,获取某段时间所有数据排重值
6、实时系统,反垃圾系统
7、Pub/Sub 构建实时消息系统
8、构建队列系统
9、缓存6.redis的三个特点?
- Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
- Redis支持数据的备份,即master-slave模式的数据备份。7.ECS与虚拟主机的区别介绍
一个是服务器
一个相当于是服务器里的文件夹
云主机是在集群服务器上划分出来的独立的内存.硬盘.带宽等资源搭建而成的 一个虚拟服务器.有独立的IP和带宽,可以根据需求安装各版本操作系统以及 配置各种网站运行环境,有远程桌面连接东西.是完全独立的.
而虚拟主机是在服务器硬盘上划分出来的一部分存储空间,它共享的是服务器 的IP和带宽.没有独立的资源和独立的操作系统.没有远程桌面功能,通常虚拟主机所支持的网站程序也是默认分配好的.没有办法由用户自己配置环境.功能相对单一.8. 重启redis
service redis-server restart
9. 有序集合是怎么排序的?
它给集合中的每一个元素设置分数,按照其分数进行排序,也不允许有重复值
10.谈谈你对memcache的理解
免费并且开源,高性能的,分布式的内存对象缓存系统
数据形态以key->value结构
用于从数据库调用、API调用或页面呈现的结果中获得少量任意数据(字符串、对象)。11. 谈谈你对redis的理解
- 开源 先进的key-value存储
- 远程字典服务器 内存级数据库 数据结构服务器
- 一个基于内存的网络存储系统
五种数据类型 字符串(String), 哈希(hash), 列表(list), 集合(sets) 和 有序集合(sorted sets)
三个特点: Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存 储。
Redis支持数据的备份,即master-slave模式的数据备份。
应用场景:
1、取最新 N 个数据的操作
2、排行榜应用,取 TOP N 操作
3、需要精准设定过期时间的应用
4、计数器应用
5、Uniq 操作,获取某段时间所有数据排重值
6、实时系统,反垃圾系统
7、Pub/Sub 构建实时消息系统
8、构建队列系统
9、缓存12. memcached与redis的区别
两者对比:
redis提供数据持久化功能,memcached无持久化;
redis的数据结构比memcached要丰富,能完成场景以外的事情;
memcached的单个key限制在250B,value限制在1MB;redis的K、V都为512MB;当然这些值可以在源码中修改;
memcached数据回收基于LRU算法,Redis提供了多种回收策略(包含LRU),但是redis的回收策的过期逻辑不可依赖,没法根据是否存在一个key判断是否过期。但是可根据ttl返回值判断是否过期;
memcached使用多线程,而redis使用单线程,基于IO多路复用实现高速访问。所以可以理解为在极端情况下memcached的吞吐大于redis。
结论:
普通KV场景:memcached、redis都可以。
从功能模块单一这个角度考虑的话,推荐memcached,只做cache一件事。
在KV长度偏大、数据结构复杂(比如取某个value的一段数据)、需要持久化的情况下,用redis更适合:但是在使用redis的时候单个请求的阻塞会导致后续请求的积压,需要注意13. 缓存的原理
有缓存则读缓存,没缓存则读数据库然后做缓存
14. memcache和memcached的区别
memcached是php连接memcached服务器的php扩展它的名字就叫memcached
以前有个叫memcache也是php连接memcached服务器的扩展,它的名字叫memcache
php的memcache和memcached扩展都是作为客户端去连接memcached服务器
但memcached作为客户端比memcache性能更好功能更强大,而且memcache已经停止更新了,因此现在使用扩展的 话就用memcached15. 存放session的三种方法
1、如果你能修改到服务器配置文件,那就打开打开php.ini
修改下面两项:
session.save_handler = memcache
session.save_path = "tcp://127.0.0.1:11211"
2、修改网站根目录下的.htaccess文件
php_value session.save_handler "memcache"
php_value session.save_path "tcp://127.0.0.1:11211"
3、最常用的方法 在程序代码中修改(推荐)
ini_set("session.save_handler", "memcache");
ini_set("session.save_path", "tcp://127.0.0.1:11211");16. mysql优化的一般步骤?
1. sql及索引
索引优化
开启慢查询日志 分析sql语句 分析是否加上索引 分析是否用上索引
2. 数据库表结构
3.系统配置
3. 优化计算机硬件17. 对mysql事物的理解?
是多个步骤为一个过程的事务(整体)
1. 事务使用 INNODB 数据库引擎
如果你不是INNODB ,开启事务,删除那就真的删除了.
2. 要么成批的sql全部执行,要么不执行
3. 事务用来管理 insert update delete 的语句
事务条件:
原子性 一组事务,要么成功,要么撤回.
稳定性 有非法数据(外键约束),事务撤回
隔离性 事务独立运行. 一个事务,处理后的结果影响到了其他事务,则事务撤回!
可靠性 软件或者硬件崩溃,Innodb 表驱动,会利用日志文件,重构修改. 可靠 性 高速度 不可兼得
关键字:
Commit 提交 当一个事务完成后,发出commit 命令使所有的参与表 完成更改.
Rollback 回滚 如果发送故障,发出rollback命令 使事务返回到 所有表以前的状态.
语句:
set autocommit = 0;
sql操作
savepoint p1;
sql操作
savepoint p2;
sql操作
ROLLBACK to p2;
commit;18. mysql触发器是什么?
监视某种事件,并触发某种操作(商品的添加,订单的删除 等等 连贯操作时候使用)
###触发四要素
1. 监视地点 table
2. 触发时间 (after/ before)
3. 监视事件 (insert/update/delete)
4. 触发事件 (insert/update/delete)
1、创建一个名为tg1的触发器,当向t1表中插入数据前,就向a表中插入一条数据
delimiter // mysql中可以转换结束符
mysql>create trigger tg1 before insert on t1 for each row #固定写法
->begin
-> insert into a values (4);
->end//19. 什么是组合索引,及使用情况?
将两个字段共同添加一条索引
例子:当前组合索引是这样一个顺序 ind_status_email(status,email)
单独查询status时,可以用到这个索引,单独查询email时,却用不到
再问: id name password 建立组合索引 怎么建立?为什么?
name,password
因为先到先得, name查询是多!!! 很少会通过password来查
先到先得 如何设置我索引?
根据字段的辨识度来做20. 为什么like在%第一个字符用不到索引?
like %校 会查处当前所有的姓, 再去查名中有没有校 所以 会进行全表扫描,浪费性能
21.测试分析sql语句
普通查询分析:
desc select * from users 或 explain select * from users 效果一样
关键字段: table:输出结果集的表名
key:表示实际使用的索引
keys_possible(可能用到的索引)
rows:扫描行的数量
22. 为什么不分开加索引?而非要加组合索引?
1. 索引不是越多越好. 浪费资源 索引占用资源,影响插入性能
2. 根据要加索引的字段辨识度而来. 如果你给辨识度小的字段加索引
第一, 加了你不常用 第二,影响性能
3. 尤其是 name pasword 经典的组合索引例子23.慢查询是什么?及其操作?
MySQL记录下查询超过指定时间的语句,我们将超过指定时间的SQL语句查询称为“慢查询”。
1、查看是否开启慢查询
mysql> show variables like "%slow%";
log_slow_queries | OFF
2、查看慢查询时间线
mysql> show variables like "%long%";
| long_query_time | 10.000000 | //默认10秒
3、开启慢查询记录功能
vi /etc/my.cnf
[mysqld]
#将慢查询日志写在这个文件中
---log_slow_queries=slow.log
#超过多少秒的算是慢查询
---long_query_time=1
#自定义,和理解可,试验用1秒方便查看日志。
4、重启mysql
ps -le | grep mysqld
pkill mysqld或者/usr/local/mysql/bin/mysqladmin –uroot –p shutdown(推荐,安全关闭)
/usr/local/mysql/bin/mysqld_safe --user=mysql &
重启后慢查询功能开启
5、查看慢查询次数
mysql>show status like "Slow_queries"; //当前链接,超时的查询次数
mysql>show global status like "Slow_queries"; //全局的
如果有慢查询,需要去日志中分析,到底是什么原因
vi /usr/local/mysql/data/slow.log #慢查询日志文件在开启慢查询功能后自动生成
需要将里面的SQL语句,用desc 分析,如果发现没有索引,则添加索引,如果是用不到索引,则修改SQL语句。
6、查看MySQL的各项状态*(了解)
show session status; 当前连接(可以省略session)
show global status; 全局,服务器启动以来
筛选一部份内容查看:
show status like "com_insert%"; 执行insert操作的次数,一次查询只累计加1
show status like "com_update%";
show status like "com_delete%";
show status like "com_select%";
show global status like "com_select%";
//不管有没有查到数据,都算一次查询操作
只针对于InnoDB存储引擎的:
show global status like "innodb_rows%";
InnoDB_rows_read
InnoDB_rows_updated
InnoDB_rows_inserted
InnoDB_rows_deleted24.bin.log日志是什么?
记录数据库变化操作的二进制日志文件
记录了所有的数据库变化操作(数据增删改,创建表等)
在数据丢失的紧急情况下,我们往往会想到用binlog日志功能进行数据恢复25.聚簇索引和非聚簇索引的区别?
聚簇索引: 聚簇索引是顺序结构与数据存储物理结构一致的一种索引,并且一个表的聚簇索引只能有唯一的一条;
说明:
平时习惯逛图书馆的童鞋可能比较清楚,如果你要去图书馆借一本书,最开始是去电脑里面查书名然后根据书名来定位藏书在那个区,哪个书柜,哪一行,第多少本。。。清晰明确,一目了然,因为藏书的结构与图书室的位置,书架的顺序,书本的摆放顺序与书籍的编号都是从大到小一致的顺序摆放的,所以很容易找到。比如,你的目标藏书在C区2柜3排5仓,那么你走到B区你就很快知道前面就快到了C区了,你直接奔着2柜区就能找到了。 这就是雷同于聚簇索引的功效了,聚簇索引,实际存储的循序结构与数据存储的物理机构是一致的,所以通常来说物理顺序结构只有一种,那么一个表的聚簇索引也只能有一个,通常默认都是主键,设置了主键,系统默认就为你加上了聚簇索引,当然有人说我不想拿主键作为聚簇索引,我需要用其他字段作为索引,当然这也是可以的,这就需要你在设置主键之前自己手动的先添加上唯一的聚簇索引,然后再设置主键,这样就木有问题啦。
非聚簇索引: 非聚簇索引记录的物理顺序与逻辑顺序没有必然的联系,与数据的存储物理结构没有关系;一个表对应的 非聚簇索引可以有多条,根据不同列的约束可以建立不同要求的非聚簇索引;
说明:
同样的,如果你去的不是图书馆,而是某城市的商业性质的图书城,那么你想找的书就摆放比较随意了,由于商业图书城空间比较紧正,藏书通常按照藏书上架的先后顺序来摆放的,所以如果查询到某书籍放在C区2柜3排5仓,但你可能要绕过F区,而不是A.B.C.D...连贯一致的,也可能同在C区的2柜,书柜上第一排是计算机类的书记,也可能最后一排就是医学类书籍;26.mysql分区有哪几种?
RANGE分区:基于属于一个给定连续区间的列值,把多行分配给分区。
LIST分区:类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择。
HASH分区:基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包含MySQL 中有效的、产生非负整数值的任何表达式。
KEY分区:类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL服务器提供其自身的哈希函数。必须有一列或多列包含整数值。27.MyISAM和InnoDB的区别?从事物和表结构分析?
1、MyISAM不支持事务,InnoDB是事务类型的存储引擎,当我们的表需要用到事务支持的时候,那肯定是不能选择MyISAM了
2、MyISAM只支持表级锁,,而InnoDB支持行级锁和表级锁默认为行级锁
3、MyISAM引擎不支持外键,InnoDB支持外键
4、MyISAM支持全文类型索引,而InnoDB不支持全文索引
5、MyISAM引擎的表在大量高并发的读写下会经常出现表损坏的情况
6、MyISAM保有表的总行数,InnoDB只能遍历
28.InnoDB共享表空间和独立表空间的优缺点?
优点:
共享表空间:
可以放表空间分成多个文件存放到各个磁盘上(表空间文件大小不受表大小的限制,如一个表可以 分布在不同步的文件上)。数据和文件放在一起方便管理
独立表空间:
1.每个表都有自已独立的表空间。
2.每个表的数据和索引都会存在自已的表空间中。
3.可以实现单表在不同的数据库中移动。
4.空间可以回收(除drop table操作处,表空不能自已回收)
a) Drop table操作自动回收表空间,如果对于统计分析或是日值表,删除大量数据后可以通 过:alter table TableName engine=innodb;回缩不用的空间。
b) 对于使innodb-plugin的Innodb使用turncate table也会使空间收缩。
c) 对于使用独立表空间的表,不管怎么删除,表空间的碎片不会太严重的影响性能,而且还有机会 处理.
缺点:
共享表空间:
所有的数据和索引存放到一个文件中意味着将有一个很常大的文件,虽然可以把一个大文件分成多 个小文件,但是多个表及索引在表空间中混合存储,这样对于一个表做了大量删除操作后表空间中 将会有大量的空隙,特别是对于统计分析,日值系统这类应用最不适合用共享表空间
独立表空间:
单表增加过大,如超过100个G
相比较之下,使用独占表空间的效率以及性能会更高一点
29.Node.js 是什么?
Node.js是一个让JavaScript运行在服务器端的开发平台.30. Node.js的特点
单线程 | 非阻塞I/O | 事件驱动
1). 单线程
所有客户端请求的连接 都使用一个线程来处理.
nodejs 不是为每个用户 创建一个新的连接,而是仅仅使用一个线程.
单线程 带来的好处: 操作系统 不会为新线程 创建 || 销毁 内容空间,而占用额外资源.2). 非阻塞I/O
I/O操作不会阻塞程序的运行3). 事件驱动
客户端 请求建立连接,提交数据等行为,就会触发 相应的事件.
在Node中,在一个时刻,只能执行 一个事件回调函数,但是在执行 一个事件回调函数的中途,可以转而处理其他事件(比如,又有新用户连接了),然后返回继续执行原事件的回调函数,这种处理机制,称为“事件环”机制.4). 三特点说明
单线程
是为了 减少内存的消耗,OS的内存(创建和销毁)
但是,如果每个请求都有I/O,单线程就会 被 阻塞.非阻塞I/O:
不会傻等着 I/O操作完成后,才去 执行后面的操作,而会 直接执行后的语句.
非阻塞I/O,的操作,一个操作还未完成,下一个操作又来了.那么使用,事件环事件驱动(事件环):
不管新用户的请求,还是老用户的请求(I/O操作),都将以事件的方式加入,事件环,等待调度.
nodejs 所有的 I/O 都是异步的,回调函数套用回调函数.31. Node.js 的优缺点?
1). 优点
善于 I/O,不善于计算.
处理高并发
服务器推送2). 缺点
单一线程,一旦崩溃,整个服务就挂了.
超人死了,世界都末日了.32. Node.js适用场景
不能完全替代 传统的后端语言,但在某些方面优于传统. (nodejs 请求后端api)
当应用程序需要处理大量并发的I/O操作,而在发出响应之前,应用程序内部 并不需要进行非常复杂的计算处理的时候,Node.js非常适合。
Node.js也非常适合与web socket配合,开发长连接的实时交互应用程序。
考试系统
聊天室
图文直播
用户表单收集(大数据处理)
复杂的计算
提供 api(数据格式:json)33 Node.js创建的http步骤
第一:引入http模块
var http = require('http'); // http 是内置模块 所以 不需要指定路径
第二: 指定服务器 ip 和 端口号
var hostname = '127.0.0.1';
var port = '3000';
第三 创建服务器
nodejs 所有的函数 都是 异步 回调函数 所以都需要用function 来接收 和处理
createServer 回调中有2个参数 req res 代表请求和响应
var server = http.createServer(function(req,res){
业务逻辑
res.end();
});
// 第四步 运行服务器
server.listen(port,hostname,function(){
});
34. Node.js中parse的用法
url.parse 会解析一个 URL 字符串并返回一个 URL 对象。
url.parse(req.url,true) 加true会解析为JSON格式,不加解析为字串格式35. Node.js文件怎么打开?
第一:引入模块
var fs =require('fs');
第二: 语法
回调有两个参数 (err, data),其中 data 是文件的内容。
fs.readFile('./fei.jpg',function(err,data){
if (err) throw err;
// 没有err 就 返回data
// 设置mime 类型
res.writeHead(200,{"Content-type":"image/jpeg;charset=utf-8"}); 解析图片格式
res.writeHead(200,{"Content-type":"text/html;charset=utf-8"}); 解析文本
res.end(data);
});36.http 请求的流程?
1. 域名解析
2. 发起TCP的3次握手
3. 建立TCP连接后发起http请求
4. 服务器端响应http请求,浏览器得到html代码
5. 浏览器解析html代码,并请求html代码中的资源
6. 浏览器对页面进行渲染呈现给用户
1、浏览器向 DNS 服务器请求解析该 URL 中的域名所对应的 IP 地址;
2、解析出 IP 地址后,根据该 IP 地址和默认端口 80,和服务器建立TCP连接;
3、浏览器发出读取文件(URL 中域名后面部分对应的文件)的HTTP 请求,该请求报文作为 TCP 三次握手的第三个报文的数据发送给服务器;
4、服务器对浏览器请求作出响应,并把对应的 html 文本发送给浏览器;
5、释放 TCP连接;
6、浏览器将该 html 文本并显示内容; 37.node.js 中模块是什么?
在Node.js中,不可能用一个js文件去写全部的业务,肯定要有MVC.
它以模块为单位 划分所有功能,并且提供了一个 完整的模块加载机制,我们可以将应用程序 划分为各个不同的部 分.
每一个JavaScript文件都是一个模块;而多个JavaScript文件可以使用require引入,使他们共同实现了一个功能 模块.38.node.js输出的方法?
输出变量/函数
Node.js中,JS文件中定义的变量、函数,都只在这个文件内部有效.
其他文件中需要引用变量、函数时,必须使用`exports对象`进行暴露(输出).使用者要用`require()`命令,引用执行这个JS文件.
输出一个类(构造函数)
可以用`module.exports = 构造函数名;`的方式 向外输出一个类39. 谈谈对npm的理解?
这是一个工具名字.npm的主要职责是 安装开发包和管理依赖项.
安装开发包:安装 npm install命令;更新 npm update命令.
管理依赖项:借助package.json文件;最简单生成package.json的方法就是npm init
开发时,会使用到各种功能的组件,所有组件都由我们自己来写代码的话,开发效率就会很低.我们不要重复的去造轮子,要学会使用已有的工具,来完善我们的项目,站在巨人的肩膀上去工作.
npm是js世界里的一个伟大的社区,能够让开发者更加轻松的共享代码和共用代码片段或模块组件.40. node.js中如何处理post请求?
相比较GET请求,POST请求比较复杂。因为Node.js认为,使用POST请求时,数据量会比较多。为了追求极致的效率,它将数据拆分成为了众多小的数据块(chunk),然后通过特定的事件,将这些小数据块有序传递给回调函数。
41. node.js中如何接收post数据?
特定的事件 去接收 addListener
querystring.parse 解析url 返回键值对的对象
特定的事件 去接收 addListener
// 第一步: 设置空的标量
var postData = '';
// 第二步 开始监听 data
req.addListener('data',function(chunk){
console.log(chunk); // 这里得到二进制数据 没有被解析
});
// 第三步: 监听结束 end
req.addListener('end',function(){
// 处理得到的postData 是一个 拼接好的 url字符串
// 第四步: 处理接收完毕的数据 转化为对象
// 解析 url字符串
// querystring.parse 解析url 返回键值对的对象
var dataObj = querystring.parse(postData);
});42.学习框架的基础块?
1. 路由
2. 中间件
3. 数据操作
4. 模板引擎43. node.js如何处理图片上传?
一 引入模板
var formidable = require('formidable');
二 // 接收参数 以及文件
var form = new formidable.IncomingForm();
// 设置上传,目录
form.uploadDir = "./uploads";
form.parse(req, function(err, fields, files) {
// 处理 接受到的参数 再处理图片的上传
// 处理上传文件的名字
// 改名字的步骤
// 起名字
// 时间 + 随机数 + 后缀
var t = datetime.format(new Date(),'YYYYMMDDHHmmss');
var ran = parseInt(Math.random()*100000);
var extname = path.extname(files.sexy_photo.name);
// 执行改名字 旧名字 新名字
// 旧名字
// 当前目录 __dirname
// path: 'uploads\\upload_621966da1b7a1d762c8a79c838f99b03',
var oldpath = __dirname + '/' + files.sexy_photo.path;
// 新名字
var newpath = __dirname + '/uploads/' + t + ran + extname;
// 改名字
// rename
fs.rename(oldpath,newpath,function(err){
res.end('图片上传成功');
});44. ejs如何渲染模板?
Render(str,data,[option]):直接渲染字符串并生成html
str:需要解析的字符串模板
data:数据
option:配置选项45.ejs常用标签?
<% %>流程控制标签
<%= %>输出标签(原文输出HTML标签)
<%- %>输出标签(HTML会被浏览器解析)
<%# %>注释标签
% 对标记进行转义
-%>去掉没用的空格
说明:ejs中的逻辑代码全部用JavaScript46. 如何使用express创建一个服务器?
// 引入express 框架
var express = require('express');
// 创建一个http服务
var app = express();
// 定义一个路由
app.get('/',function(req,res){
res.send('xxxx');
// 不建议使用end 因为end 会结束响应
});
// 运行服务
// 可以不写第二个参数 代表本地 和外网 均可以访问
app.listen(3000);
47.express如何定义路由?
app.get('/',function(req,res){
res.send('xxxx');
// 不建议使用end 因为end 会结束响应
});
app.post('/chenpin',function(req,res){
res.send('');
});
48.res中 end和send的区别?
如果服务器端没有数据返回到客户端 那么就可以用 res.end
但是 如果 服务器端有数据返回到客户端 这个时候必须用res.send ,不能用 res.end(会报错)
49. php命名空间是如何定义的?
命名空间通过关键字namespace 来声明。如果一个文件中包含命名空间,它必须在其它所有代码之前声明命名空间,除了一个以外:declare关键字。
命名空间一个最明确的目的就是解决重名问题,PHP中不允许两个函数或者类出现相同的名字,否则会产生一个致命的错误。这种情况下只要避免命名重复就可以解决,最常见的一种做法是约定一个前缀。
基础
命名空间将代码划分出不同的空间(区域),每个空间的常量、函数、类(为了偷懒,我下边都将它们称为元素)的名字互不影响, 这个有点类似我们常常提到的‘封装'的概念
50.php接口是如何实现的?
如果一个抽象类里面的所有方法都是抽象方法,且没有声明变量,而且接口里面所有的成员都是public权限的,那么这种特殊的抽象类就叫接口
接口是什么?
使用接口(interface),可以指定某个类必须实现哪些方法,但不需要定义这些方法的具体内容。
接口是通过 interface 关键字来定义的,就像定义一个标准的类一样,但其中定义所有的方法都是空的。
接口中定义的所有方法都必须是公有,这是接口的特性。
接口使用规范
接口不能实例化
接口的属性必须是常量
接口的方法必须是public【默认public】,且不能有函数体
类必须实现接口的所有方法
一个类可以同时实现多个接口,用逗号隔开
接口可以继承接口【用的少】
51.express如何获取get post参数的?
get
req.query
post
// 引入表单处理模块
var bodyParser = require('body-parser');
/ 设置 url 解析 规则
// app.use(bodyParser.json()); // for parsing application/json 可以加 可以 不加
// 必须加
app.use(bodyParser.urlencoded({ extended: true })); // for parsing application/x-www-form- urlencoded
// 处理 post 参数
req.body
52.socket 如何发送和接收消息?
// 发送消息
socket.emit('jyzj', '您多大了?');
// 点击按钮 发送消息
document.getElementById('btn').onclick = function () {
socket.emit('s80', '渣男');
// socket.emit('jyzj', '打狗棍法!天下无狗!');
};
// 监听回答
socket.on('action', function (msg) {
alert('xxx: ' + msg);
});
// 接收消息的方法
socket.on('event',function(msg){ 接收到消息的业务逻辑操作 });
socket.on('s80', function (msg) {
console.log('接收的消息'+msg);
socket.emit('action', '我就是渣男,不服来砍我!');
// 关于emi方法的备注
// console.log(io);console.log(socket); // 结果一样
// 使用socket.emit 和io.emit是一个方法.
// 但是常用是socket.emit
})
53. b2b2c o2o p2p CRM ERP OA 分别是什么?
B2B2C:
是一种电子商务类型的网络购物商业模式,B是BUSINESS的简称,C是CUSTOMER的简称,第一个B指的是商品或服务的供应商,第二个B指的是从事电子商务的企业,C则是表示消费者。
中文名 电子购物平台模式
外文名 B2B2C
模 式 供应商对企业,企业对消费者
平 台 淘宝,京东等
O2O:
即Online To Offline(在线离线/线上到线下),是指将线下的商务机会与互联网结合,让互联网成为线下交易的平台,这个概念最早来源于美国。O2O的概念非常广泛,既可涉及到线上,又可涉及到线下,可以通称为O2O。主流商业管理课程均对O2O这种新型的商业模式有所介绍及关注。例如:云家园、云家政、e家洁、小区管家
P2P peer-to-peer lending
p2p金融又叫P2P信贷。
其中,P2P是 peer-to-peer 或 person-to-person 的简写,意思是:个人对个人。P2P金融指个人与个人间的小额借贷交易,一般需要借助电子商务专业网络平台帮助借贷双方确立借贷关系并完成相关交易手续。借款者可自行发布借款信息,包括金额、利息、还款方式和时间,实现自助式借款;借出者根据借款人发布的信息,自行决定借出金额,实现自助式借贷。
举例说明:MB月光宝盒平台
目前做P2P最多的属于P2P互联网金融平台,简单的意思就是个人对个人通过平台来连接达到解决双方的需求。
ERP
所谓ERP是英文Enterprise Resource Planning(企业资源计划)的简写。
是指建立在信息技术基础上,以系统化的管理思想,为企业决策层及员工提供决策运行手段的管理平台。ERP系统集中信息技术与先进的管理思想於一身,成为现代企业的运行模式,反映时代对企业合理调配资源,最大化地创造社会财富的要求,成为企业在信息时代生存、发展的基石。
CRM Customer Relationship Management
即客户关系管理,是指企业用CRM技术来管理与客户之间的关系。在不同场合下,CRM可能是一个管理学术语,可能是一个软件系统。通常所指的CRM,指用计算机自动化分析销售、市场营销、客户服务以及应用等流程的软件系统。它的目标是通过提高客户的价值、满意度、赢利性和忠实度来缩减销售周期和销售成本、增加收入、寻找扩展业务所需的新的市场和渠道。CRM是选择和管理有价值客户及其关系的一种商业策略,CRM要求以客户为中心的企业文化来支持有效的市场营销、销售与服务流程
OA:
说起OA(Office Automation,办公自动化),总体上讲,它是指一切可满足于企事业单位的、综合型的、能够提高单位内部信息交流、共享、流转处理的和实现办公自动化和提高工作效率的各种信息化设备和应用软件。
它不是孤立存在的,而是与企事业单位其它各类管理系统(如行政管理系统、人力资源管理系统、CRM系统、销售管系统、ERP系统、财务系统、销售会员管理系统)密切相关、有机整合。一个独立存在的OA办公自动化系统生命力及作用是薄弱的。——这也是目前最全面、最被认可的OA的概念。
54.微信订阅号和服务号的区别?
55. 如何完成微信的接口配置? 以及配置失败的原因?
填写的URL需要正确响应微信发送的Token验证
失败原因未删除里面的html文件
56. 如何获取微信发送的内容?
$postStr = file_get_contents("php://input");
57.php是单线程还是多线程
单线程58.什么是依赖注入,解决了那些问题
1.什么是依赖注入
依赖注入是控制反转的一种实现,实现代码解耦,便于单元测试。因为它并不需要了解自身所依赖的类,而只需要知道所依赖的类实现了自身所需要的方法就可以了。
2.解决那些问题
依赖之间的解耦
单元测试,方便Mock59.什么是控制反转
控制反转 是面向对象编程中的一种设计原则,可以用来减低计算机代码之间的耦合度。其中最常见的方式叫做依赖注入(Dependency Injection, DI), 还有一种叫"依赖查找"(Dependency Lookup)。通过控制反转,对象在被创建的时候,由一个调控系统内所有对象的外界实体,将其所依赖的对象的引用传递给它。也可以说,依赖被注入到对象中。60.服务器之间如何共享session
1.通过数据库mysql共享session
a.采用一台专门的mysql服务器来存储所有的session信息。
用户访问随机的web服务器时,会去这个专门的数据库服务器check一下session的情况,以达到session同步的目的。
缺点就是:依懒性太强,mysql服务器无法工作,影响整个系统;
b.将存放session的数据表与业务的数据表放在同一个库。如果mysql做了主从,需要每一个库都需要存在这个表,并且需要数据实时同步。
缺点:用数据库来同步session,会加大数据库的负担,数据库本来就是容易产生瓶颈的地方,如果把session还放到数据库里面,无疑是雪上加霜。上面的二种方法,第一点方法较好,把放session的表独立开来,减轻了真正数据库的负担 。但是session一般的查询频率较高,放在数据库中查询性能也不是很好,不推荐使用这种方式。
2.通过cookie共享session
把用户访问页面产生的session放到cookie里面,就是以cookie为中转站。
当访问服务器A时,登录成功之后将产生的session信息存放在cookie中;当访问请求分配到服务器B时,服务器B先判断服务器有没有这个session,如果没有,在去看看客户端的cookie里面有没有这个session,如果cookie里面有,就把cookie里面的sessoin同步到web服务器B,这样就可以实现session的同步了。
缺点:cookie的安全性不高,容易伪造、客户端禁止使用cookie等都可能造成无法共享session。
3.通过服务器之间的数据同步session
使用一台作为用户的登录服务器,当用户登录成功之后,会将session写到当前服务器上,我们通过脚本或者守护进程将session同步到其他服务器上,这时当用户跳转到其他服务器,session一致,也就不用再次登录。
缺陷:速度慢,同步session有延迟性,可能导致跳转服务器之后,session未同步。而且单向同步时,登录服务器宕机,整个系统都不能正常运行。
4.通过NFS共享Session
选择一台公共的NFS服务器(Network File Server)做共享服务器,所有的Web服务器登陆的时候把session数据写到这台服务器上,那么所有的session数据其实都是保存在这台NFS服务器上的,不论用户访问那太Web服务器,都要来这台服务器获取session数据,那么就能够实现共享session数据了。
缺点:依赖性太强,如果NFS服务器down掉了,那么大家都无法工作了,当然,可以考虑多台NFS服务器同步的形式。
5.通过memcache同步session
memcache可以做分布式,如果没有这功能,他也不能用来做session同步。他可以把web服务器中的内存组合起来,成为一个"内存池",不管是哪个服务器产生的sessoin都可以放到这个"内存池"中,其他的都可以使用。
优点:以这种方式来同步session,不会加大数据库的负担,并且安全性比用cookie大大的提高,把session放到内存里面,比从文件中读取要快很多。
缺点:memcache把内存分成很多种规格的存储块,有块就有大小,这种方式也就决定了,memcache不能完全利用内存,会产生内存碎片,如果存储块不足,还会产生内存溢出。
6.通过redis共享session
redis与memcache一样,都是将数据放在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
61.session和cookie的区别
cookie session
位置 浏览器 服务器
特点 方便和js交换 高效安全
获取用户信息 不依赖浏览器环境
风险 用户禁用cookie
替代 url参数62.cookie禁用后如何使用session
1、设置php.ini的session.use_trans_sid = 1或者打开enable-trans-sid选项,让PHP自动跨页传递session id。
2、手动通过URL传值、隐藏表单传递session id。
3、用文件、数据库等形式保存session_id,在跨页过程中手动调用。63.PSR规范
psr-1是基本代码规范
psr-2是代码风格规范
psr-3是日志接口规范
psr-4是为了解决自动加载
psr-6是缓存接口规范
psr-7是HTTP消息接口规范
64.git高级命令
git rebase 在新位置重新提交
git revert 撤销commit
git reset 丢弃提交
git stash 临时存放工作目录的改动
git reflog 找回分支65.PHP如何实现多继承
1.接口单继承
2.接口多继承
3.trait
4.PHP 默认并不支持多线程,要使用多线程需要安装 pthread 扩展,而要安装 pthread 扩展trait示例
<?php
trait ezcReflectionReturnInfo {
function getReturnType() { /*1*/ }
function getReturnDescription() { /*2*/ }
}
class ezcReflectionMethod extends ReflectionMethod {
use ezcReflectionReturnInfo;
/* ... */
}
class ezcReflectionFunction extends ReflectionFunction {
use ezcReflectionReturnInfo;
/* ... */
}
?>66.进程,协程,线程
进程是程序执行是的一个实例,进程能够分配给cpu和内存等资源。进程一般包括指令集和系统资源,其中指令集就是你的代码,系统资源就是指cpu、内存以及I/O等。
进程是一个程序在一个数据集中的一次动态执行过程,可以简单理解为“正在执行的程序”,它是CPU资源分配和调度的独立单位。
进程一般由程序、数据集、进程控制块三部分组成。我们编写的程序用来描述进程要完成哪些功能以及如何完成;数据集则是程序在执行过程中所需要使用的资源;进程控制块用来记录进程的外部特征,描述进程的执行变化过程,系统可以利用它来控制和管理进程,它是系统感知进程存在的唯一标志。
进程的局限是创建、撤销和切换的开销比较大。
线程是进程的一个执行流,线程不能分配系统资源,它是进程的一部分,比进程更小的独立运行的单位。
解释一下:进程有两个特性:一是资源的所有权,一个是调度执行(指令集),线程是调度执行中的一部分,是指进程执行过程的路径,也叫程序执行流。线程有时候也叫轻量级进程。
线程是在进程之后发展出来的概念。 线程也叫轻量级进程,它是一个基本的CPU执行单元,也是程序执行过程中的最小单元,由线程ID、程序计数器、寄存器集合和堆栈共同组成。一个进程可以包含多个线程。
线程的优点是减小了程序并发执行时的开销,提高了操作系统的并发性能,缺点是线程没有自己的系统资源,只拥有在运行时必不可少的资源,但同一进程的各线程可以共享进程所拥有的系统资源,如果把进程比作一个车间,那么线程就好比是车间里面的工人。不过对于某些独占性资源存在锁机制,处理不当可能会产生“死锁”。
协程是一种用户态的轻量级线程,又称微线程,英文名Coroutine,协程的调度完全由用户控制。人们通常将协程和子程序(函数)比较着理解。
子程序调用总是一个入口,一次返回,一旦退出即完成了子程序的执行。
协程的起始处是第一个入口点,在协程里,返回点之后是接下来的入口点。在python中,协程可以通过yield来调用其它协程。通过yield方式转移执行权的协程之间不是调用者与被调用者的关系,而是彼此对称、平等的,通过相互协作共同完成任务。其运行的大致流程如下:
第一步,协程A开始执行。
第二步,协程A执行到一半,进入暂停,通过yield命令将执行权转移到协程B。
第三步,(一段时间后)协程B交还执行权。
第四步,协程A恢复执行。
协程的特点在于是一个线程执行,与多线程相比,其优势体现在:
* 协程的执行效率非常高。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。
* 协程不需要多线程的锁机制。在协程中控制共享资源不加锁,只需要判断状态就好了。
Tips:利用多核CPU最简单的方法是多进程+协程,既充分利用多核,又充分发挥协程的高效率,可获得极高的性能。67.php反射
http://php.net/manual/zh/book.reflection.php68.公众号全局唯一票据
( access_token )是公众号的全局唯一票据,有效期为( 2小时 )69.自定义菜单
1、自定义菜单最多包括3个一级菜单,每个一级菜单最多包含5个二级菜单。
2、一级菜单最多4个汉字,二级菜单最多7个汉字,多出来的部分将会以“...”代替。
3、创建自定义菜单后,菜单的刷新策略是,在用户进入公众号会话页或公众号profile页时,如果发现上一次拉取菜单的请求在5分钟以前,就会拉取一下菜单,如果菜单有更新,就会刷新客户端的菜单。测试时可以尝试取消关注公众账号后再次关注,则可以看到创建后的效果。70.写出四个自定义菜单按钮类型
1、click:点击推事件用户点击click类型按钮后,微信服务器会通过消息接口推送消息类型为event的结构给开发者(参考消息接口指南),并且带上按钮中开发者填写的key值,开发者可以通过自定义的key值与用户进行交互;
2、view:跳转URL用户点击view类型按钮后,微信客户端将会打开开发者在按钮中填写的网页URL,可与网页授权获取用户基本信息接口结合,获得用户基本信息。
3、scancode_push:扫码推事件用户点击按钮后,微信客户端将调起扫一扫工具,完成扫码操作后显示扫描结果(如果是URL,将进入URL),且会将扫码的结果传给开发者,开发者可以下发消息。
4、scancode_waitmsg:扫码推事件且弹出“消息接收中”提示框用户点击按钮后,微信客户端将调起扫一扫工具,完成扫码操作后,将扫码的结果传给开发者,同时收起扫一扫工具,然后弹出“消息接收中”提示框,随后可能会收到开发者下发的消息。
5、pic_sysphoto:弹出系统拍照发图用户点击按钮后,微信客户端将调起系统相机,完成拍照操作后,会将拍摄的相片发送给开发者,并推送事件给开发者,同时收起系统相机,随后可能会收到开发者下发的消息。
6、pic_photo_or_album:弹出拍照或者相册发图用户点击按钮后,微信客户端将弹出选择器供用户选择“拍照”或者“从手机相册选择”。用户选择后即走其他两种流程。
7、pic_weixin:弹出微信相册发图器用户点击按钮后,微信客户端将调起微信相册,完成选择操作后,将选择的相片发送给开发者的服务器,并推送事件给开发者,同时收起相册,随后可能会收到开发者下发的消息。
8、location_select:弹出地理位置选择器用户点击按钮后,微信客户端将调起地理位置选择工具,完成选择操作后,将选择的地理位置发送给开发者的服务器,同时收起位置选择工具,随后可能会收到开发者下发的消息。
9、media_id:下发消息(除文本消息)用户点击media_id类型按钮后,微信服务器会将开发者填写的永久素材id对应的素材下发给用户,永久素材类型可以是图片、音频、视频、图文消息。请注意:永久素材id必须是在“素材管理/新增永久素材”接口上传后获得的合法id。
10、view_limited:跳转图文消息URL用户点击view_limited类型按钮后,微信客户端将打开开发者在按钮中填写的永久素材id对应的图文消息URL,永久素材类型只支持图文消息。请注意:永久素材id必须是在“素材管理/新增永久素材”接口上传后获得的合法id。
请注意!!! 3到8的所有事件,仅支持微信iPhone5.4.1以上版本,和Android5.4以上版本的微信用户,旧版本微信用户点击后将没有回应,开发者也不能正常接收到事件推送。9和10,是专门给第三方平台旗下未微信认证(具体而言,是资质认证未通过)的订阅号准备的事件类型,它们是没有事件推送的,能力相对受限,其他类型的公众号不必使用。71.写出四个接受消息类型
写出四个接收消息类型( 文本消息 图片消息 语音消息 视频消息 小视频消息 地理位置消息 链接消息 )。72.模板内容中部必须为多少个个“关键词名称:关键词内容参数”的组合排列
模板消息填写时,必须严格遵守以下规则,否则也不能审核通过:
1、模板内容长度不能超过200个字符,且必须有至少10个固定文字或标点
2、模版内容中,参数是可以在发送时赋值的,参数必须以“{ {”开头,以“.DATA} }”结尾)
3、内容示例是将模板内容中的参数分别举例后的模板内容的副本,必须严格填写,用以帮助审核人员详细理解模板的用途
4、参数中可以通过增加“\n”,来实现换行,所以,一般建议将参数紧贴上一行,在需要时用“\n”自行换行。通过该技巧,可以让模板消息的拓展能力变得非常强。
5、模版内容中,第一句话需要为礼貌性、称谓性的用语,这句话统一用{ {first.DATA} }参数来概括,以免此后称谓习惯等修改后,需修改模版。
6、模版内容的中部必须为2到5个“关键词名称:关键词内容参数”(中文冒号)的组合排列,这样显示在微信客户端中体验最佳。
7、模版内容中,末尾必须有{ {remark.DATA} }参数,该参数的作用是,用户可以自行添加多行需要的内容。例如,模版中有姓名、时间这2个关键词,但你需要姓名、时间、地点3个,则可以将地点这个关键词的内容放入remark参数中(需要时可通过\n来换行)。这样就达到了用remark参数来扩充关键词的作用,极大增强了模版的通用性。
8、直接相连在一起的参数,应简化为一个,避免模板内容过于复杂,因为赋值到两个参数中的内容可以简化地赋值到一个参数中。
9、为了保持行业通用性,模板标题和模板内容中,不允许带有品牌等关键词,以免影响通用性。73.在使用接口特别是发送消息时,对多媒体文件、多媒体消息的获取和调用等操作,是通过( media_id )来进行的。
素材管理
新增临时素材
公众号经常有需要用到一些临时性的多媒体素材的场景,例如在使用接口特别是发送消息时,对多媒体文件、多媒体消息的获取和调用等操作,是通过media_id来进行的。素材管理接口对所有认证的订阅号和服务号开放。通过本接口,公众号可以新增临时素材(即上传临时多媒体文件)。
注意点:
1、临时素材media_id是可复用的。
2、媒体文件在微信后台保存时间为3天,即3天后media_id失效。
3、上传临时素材的格式、大小限制与公众平台官网一致。
图片(image): 2M,支持PNG\JPEG\JPG\GIF格式
语音(voice):2M,播放长度不超过60s,支持AMR\MP3格式
视频(video):10MB,支持MP4格式
缩略图(thumb):64KB,支持JPG格式
4、需使用https调用本接口。74.模板消息不允许在用户没做任何操作或未经用户同意接收的前提下,主动下发消息给用户
模板消息运营规范
模板消息用来帮助公众号进行业务通知,是开发者在模板内容中设定参数(参数必须以“{ {”开头,且以“.DATA} }”结尾),并在调用时为这些参数赋值并发送的消息。
模板消息的定位是用户触发后的通知消息,不允许在用户没做任何操作或未经用户同意接收的前提下,主动下发消息给用户。
目前在特殊情况下允许主动下发的消息只有故障类和灾害警示警告类通知,除此之外都要经过用户同意或用户有触发行为才能下发模板消息。
公众号只能在模板库中按照自己的行业来选择模板。如果模板库中暂时没有你想要的模板,则请你仔细阅读以下内容后,在满足要求的情况下,可以为你所在的行业贡献新模板,帮助充实模板库。75.模板消息内容不能做营销、推广
模板消息运营规范
处罚规则
违规的判定原则
1.发模板的行为:
①模板消息不能主动下发给没有接受过服务的接收者(故障报警、灾害报警和不涉及营销推广的通知除外)
例:某用户仅仅是关注公众号,没有和公众号及其所属主体有任何交互行为,却无故收到该公众号下发的模板消息,属于违规行为
②模板消息的发送频率不能太高骚扰接收者
例:某用户点击公众号的自定义菜单一次或其它触发操作,连续收到3条或更多重复模板消息,属于违规行为
2.模板的内容:
①模板消息内容不能做营销、推广、诱导分享及诱导下载APP
例:某用户购买某商品后,公众号下发模板推销其它商品,与用户此次接受的服务无关,属于违规
②模板内容与模板标题或关键词无关联
例:标题是刷卡成功通知,模板内容却是推销商品或活动通知,属于违规
③模板内容是营销性质的群发活动公告通知
例:标题小区物业通知,模板内容却是群发活动的营销信息
综合上述两项原则后判断,主动下发、内容涉及恶意营销、频率过高恶意骚扰、以及模板参数内容乱填写将被封接口处罚。对于多次使用同一模板违规的,将回收违规模板,不允许再使用,违规处罚将通过微信公众平台站内信告知运营者。76.对于临时素材,每个素材会在开发者上传或粉丝发送到微信服务器3天后自动删除
媒体文件在微信后台保存时间为3天,即3天后media_id失效。77.含有明示或暗示用户分享的文案、图片、按钮、弹层、弹窗,不属于诱导分享
诱导分享类内容
1.1 要求用户分享,分享后方可进行下一步操作,分享后方可知道答案等;
1.2 含有明示或暗示用户分享的文案、图片、按钮、弹层、弹窗等的,如:分享给好友、邀请好友一起完成任务等;
1.3 通过利益诱惑,诱导用户分享、传播外链内容或者微信公众帐号文章的,包括但不限于:现金奖励、实物奖品、虚拟奖品(红包、优惠券、代金券、积分、话费、流量、信息等)、集赞、拼团、分享可增加抽奖机会、中奖概率,以积分或金钱利益诱导用户分享、点击、点赞微信公众帐号文章等;
1.4 用夸张言语来胁迫、引诱用户分享的。包括但不限于:“不转不是中国人”、“请好心人转发一下”、“转发后一生平安”、“转疯了”、“必转”、“转到你的朋友圈朋友都会感激你”等78.企业号、服务号、订阅号区别
| 企业号 | 服务号 | 订阅号 | |
|---|---|---|---|
| 消息次数限制 | 最高每分钟可群发200次 | 每月主动发送消息不超过4条 | 每天群发一条 |
| 验证关注者身份 | 通讯录成员可关注 | 不论什么微信用户扫码就可以关注 | 不论什么微信用户扫码就可以关注 |
| 消息保密 | 消息可转发、分享。支持保密消息,防成员转发 | 消息可转发、分享 | 消息可转发、分享 |
| 高级接口权限 | 支持 | 支持 | 不支持 |
| 定制应用 | 可依据须要定制应用,多个应用聚合成一个企业号 | 不支持。新增服务号须要又一次关注。 | 不支持,新增服务号须要又一次关注。 |
79.简单描述微信公众平台接入
80.网页授权用户消息流程步骤
1、引导用户进入授权页面同意授权,获取code
2、通过code换取网页授权access_token(与基础支持中的access_token不同)
3、如果需要,开发者可以刷新网页授权access_token,避免过期
4、通过网页授权access_token和openid获取用户基本信息(支持UnionID机制)81.描述小程序的框架
框架名称:MINA(MINA IS NOT APP)是在微信中开发小程序的框架。
框架结构 :MINA框架由两部分组成.视图层(View)和逻辑层(App Service)。
框架特征 :响应式的数据绑定(MINA用响应式数据绑定的方式,在视图层和逻辑层之间进行通信。从某种程度上,可以看成是MVVM模式。)
结构:MINA程序包含一个描述整体程序的app和多个描述各自页面的page。
一个MINA程序主体部分由三个文件组成,必须放在根目录下。
Paste_Image.png
一个MINA页面由四个文件组成。如下图
82.检测是否是微信浏览器
判断浏览器是否是微信内置浏览器主要通过UserAgent或者WeiXinJSBridge两种方式进行83.浏览器内核有哪些?
1、Trident内核:代表作品是IE,因IE捆绑在Windows中,所以占有极高的份额,又称为IE内核或MSHTML,此内核只能用于Windows平台,且不是开源的。
? ? 代表作品还有腾讯、Maxthon(遨游)、360浏览器等。但由于市场份额比较大,曾经出现脱离了W3C标准的时候,同时IE版本比较多,
? ??存在很多的兼容性问题。
2、Gecko内核:代表作品是Firefox,即火狐浏览器。因火狐是最多的用户,故常被称为firefox内核它是开源的,最大优势是跨平台,在Microsoft Windows、Linux、MacOs X等主 ??要操作系统中使用。
? ?Mozilla是网景公司在第一次浏览器大战败给微软之后创建的。有兴趣的同学可以了解一下浏览器大战
3、Webkit内核:代表作品是Safari、曾经的Chrome,是开源的项目。
4、Presto内核:代表作品是Opera,Presto是由Opera Software开发的浏览器排版引擎,它是世界公认最快的渲染速度的引擎。在13年之后,Opera宣布加入谷歌阵营,弃用了 ? ?Presto
5、Blink内核:由Google和Opera Software开发的浏览器排版引擎,2013年4月发布。现在Chrome内核是Blink。谷歌还开发了自己的JS引擎,V8,使JS运行速度极大地提高了84.php-fpm是什么
PHP-FPM(FastCGI Process Manager:FastCGI进程管理器)是一个PHPFastCGI管理器,对于PHP 5.3.3之前的php来说,是一个补丁包 [1] ,旨在将FastCGI进程管理整合进PHP包中。如果你使用的是PHP5.3.3之前的PHP的话,就必须将它patch到你的PHP源代码中,在编译安装PHP后才可以使用。
相对Spawn-FCGI,PHP-FPM在CPU和内存方面的控制都更胜一筹,而且前者很容易崩溃,必须用crontab进行监控,而PHP-FPM则没有这种烦恼。
php-fpm是 FastCGI 的实现,并提供了进程管理的功能。
进程包含 master 进程和 worker 进程两种进程。
master 进程只有一个,负责监听端口,接收来自 Web Server 的请求,而 worker 进程则一般有多个(具体数量根据实际需要配置),每个进程内部都嵌入了一个 PHP 解释器,是 PHP 代码真正执行的地方。
使用PHP-FPM来控制PHP-CGI的FastCGI进程
/usr/local/php/sbin/php-fpm{start|stop|quit|restart|reload|logrotate}
--start 启动php的fastcgi进程
--stop 强制终止php的fastcgi进程
--quit 平滑终止php的fastcgi进程
--restart 重启php的fastcgi进程
--reload 重新平滑加载php的php.ini
--logrotate 重新启用log文件85.ngnix反向代理
反向代理(Reverse Proxy)方式是指以代理服务器来接受Internet上的连接请求,然后将请求转发给内部网络上的服务器;并将从服务器上得到的结果返回给Internet上请求连接的客户端,此时代理服务器对外就表现为一个服务器
客户端而言它就像是原始服务器,并且客户端不需要进行任何特别的设置。客户端向反向代理 的命名空间(name-space)中的内容发送普通请求,接着反向代理将判断向何处(原始服务器)转交请求,并将获得的内容返回给客户端,就像这些内容 原本就是它自己的一样。
作用:
1.保护和隐藏原始资源服务器
2.负载均衡(需要多个)
3.过配置缓存功能加速Web请求:可以缓存真实Web服务器上的某些静态资源,减轻真实Web服务器的负载压力通常的代理服务器,只用于代理内部网络对Internet的连接请求,客户机必须指定代理服务器,并将本来要直接发送到Web服务器上的http请求发送到代理服务器中。当一个代理服务器能够代理外部网络上的主机,访问内部网络时,这种代理服务的方式称为反向代理服务。
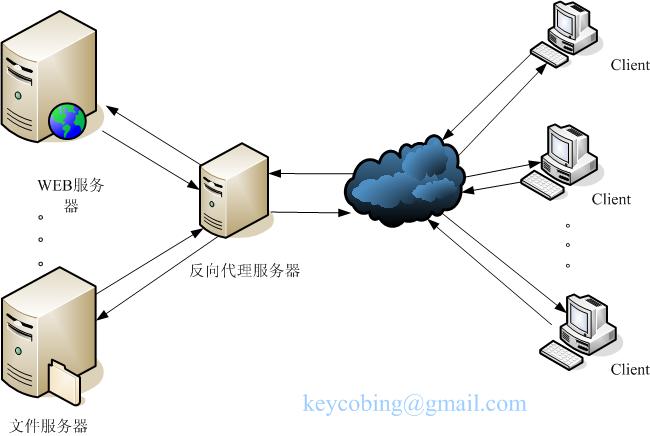
blog.csdn.net/tsummerb/article/det...
86.Nginx正向代理
正向代理,也就是传说中的代理,他的工作原理就像一个跳板, 简单的说, 我是一个用户,我访问不了某网站,但是我能访问一个代理服务器 这个代理服务器呢,他能访问那个我不能访问的网站 于是我先连上代理服务器,告诉他我需要那个无法访问网站的内容 代理服务器去取回来,然后返回给我
正向代理 是一个位于客户端和原始服务器(origin server)之间的服务器,为了从原始服务器取得内容,客户端向代理发送一个请求并指定目标(原始服务器),然后代理向原始服务器转交请求并将获得的内容返回给客户端。客户端必须要进行一些特别的设置才能使用正向代理。
1.访问本无法访问的服务器
2.正向代理提速(现在不流行)
3.缓存作用
4.客户端访问授权
5.隐藏访问者的行踪

访问google.com这个例子
www.php.cn/php-weizijiaocheng-39315...
87.什么是中间件
过滤Http请求
过滤进入应用的HTTP请求对象(Request)和完善离开应用的HTTP响应对象(Reponse)的作用, 而且可以通过应用多个中间件来层层过滤请求、逐步完善相应。这样就做到了程序的解耦,如果没有中间件那么我们必须在控制器中来完成这些步骤,这无疑会造成控制器的臃肿。
请求->中间件->中间件->应用->中间件->中间件->响应
中间件的设计使用了装饰器模式88.trait优先级
在trait继承中,优先顺序依次是:来自当前类的成员覆盖了 trait 的方法,而 trait 则覆盖了被继承的方法。
For example:
class A{
public function sayHello(){
echo "A";
}
}
trait B{
public function sayHello(){
parent::sayHello();
echo "B";
}
}
class C extends A{
use B;
}
$c=new C();
$c->sayHello();
上述打印结果是:AB
89.索引使用经典场景
1.匹配全值
2.匹配范围
3.最左前缀
4.搜索索引
5.匹配列前缀
90.存在却不能使用的场景
1.以%开头的LIKE文件
2.数据类型出现隐式转换
3.多列索引查询条件不包括最左部分,即不满足左原则
4.使用索引比全表扫描慢
5.用or分开的条件
6.条件索引使用函数
91.软件开发流程
需求分析
1.相关系统分析员向用户初步了解需求,然后用相关的工具软件列出要开发的系统的大功能模块,每个大功能模块有哪些小功能模块,对于有些需求比较明确相关的界面时,在这一步里面可以初步定义好少量的界面。
2.系统分析员深入了解和分析需求,根据自己的经验和需求用WORD或相关的工具再做出一份文档系统的功能需求文档。这次的文档会清楚列出系统大致的大功能模块,大功能模块有哪些小功能模块,并且还列出相关的界面和界面功能。
3.系统分析员向用户再次确认需求。
概要设计
首先,开发者需要对软件系统进行概要设计,即系统设计。概要设计需要对软件系统的设计进行考虑,包括系统的基本处理流程、系统的组织结构、模块划分、功能分配、接口设计、运行设计、数据结构设计和出错处理设计等,为软件的详细设计提供基础。
详细设计
在概要设计的基础上,开发者需要进行软件系统的详细设计。在详细设计中,描述实现具体模块所涉及到的主要算法、数据结构、类的层次结构及调用关系,需要说明软件系统各个层次中的每一个程序(每个模块或子程序)的设计考虑,以便进行编码和测试。应当保证软件的需求完全分配给整个软件。详细设计应当足够详细,能够根据详细设计报告进行编码。
编码
在软件编码阶段,开发者根据《软件系统详细设计报告》中对数据结构、算法分析和模块实现等方面的设计要求,开始具体的编写程序工作,分别实现各模块的功能,从而实现对目标系统的功能、性能、接口、界面等方面的要求。在规范化的研发流程中,编码工作在整个项目流程里最多不会超过1/2,通常在1/3的时间,所谓磨刀不误砍柴功,设计过程完成的好,编码效率就会极大提高,编码时不同模块之间的进度协调和协作是最需要小心的,也许一个小模块的问题就可能影响了整体进度,让很多程序员因此被迫停下工作等待,这种问题在很多研发过程中都出现过。编码时的相互沟通和应急的解决手段都是相当重要的,对于程序员而言,bug永远存在,你必须永远面对这个问题,大名鼎鼎的微软,可曾有连续三个月不发补丁的时候吗?从来没有!
测试
测试编写好的系统。交给用户使用,用户使用后一个一个的确认每个功能。软件测试有很多种:按照测试执行方,可以分为内部测试和外部测试;按照测试范围,可以分为模块测试和整体联调;按照测试条件,可以分为正常操作情况测试和异常情况测试;按照测试的输入范围,可以分为全覆盖测试和抽样测试。以上都很好理解,不再解释。总之,测试同样是项目研发中一个相当重要的步骤,对于一个大型软件,3个月到1年的外部测试都是正常的,因为永远都会有不可预料的问题存在。完成测试后,完成验收并完成最后的一些帮助文档,整体项目才算告一段落,当然日后少不了升级,修补等等工作,只要不是想通过一锤子买卖骗钱,就要不停的跟踪软件的运营状况并持续修补升级,直到这个软件被彻底淘汰为止。
软件交付
在软件测试证明软件达到要求后,软件开发者应向用户提交开发的目标安装程序、数据库的数据字典、《用户安装手册》、《用户使用指南》、需求报告、设计报告、测试报告等双方合同约定的产物。
《用户安装手册》应详细介绍安装软件对运行环境的要求、安装软件的定义和内容、在客户端、服务器端及中间件的具体安装步骤、安装后的系统配置。
《用户使用指南》应包括软件各项功能的使用流程、操作步骤、相应业务介绍、特殊提示和注意事项等方面的内容,在需要时还应举例说明。
验收
用户验收。
维护
根据用户需求的变化或环境的变化,对应用程序进行全部或部分的修改。92.消息队列MQ
“消息队列”是在消息的传输过程中保存消息的容器。
在项目中,将一些无需即时返回且耗时的操作提取出来,进行了异步处理,而这种异步处理的方式大大的节省了服务器的请求响应时间,从而提高了系统的吞吐量。
RabbitMQ支持消息的持久化,也就是数据写在磁盘上,为了数据安全考虑,我想大多数用户都会选择持久化。消息队列持久化包括3个部分:
(1)exchange持久化,在声明时指定durable => 1
(2)queue持久化,在声明时指定durable => 1
(3)消息持久化,在投递时指定delivery_mode => 2(1是非持久化)
如果exchange和queue都是持久化的,那么它们之间的binding也是持久化的。如果exchange和queue两者之间有一个持久化,一个非持久化,就不允许建立绑定。93.千万级别的数据库经纬度,批量替换成地址
1.拆表百万为一单位
2.批量提交和读取使用yield协程异步操作
94.Redis有哪些数据结构?
字符串String、字典Hash、列表List、集合Set、有序集合SortedSet。
如果你是Redis中高级用户,还需要加上下面几种数据结构HyperLogLog、Geo、Pub/Sub。
如果你说还玩过Redis Module,像BloomFilter,RedisSearch,Redis-ML,面试官得眼睛就开始发亮了。
95.使用过Redis分布式锁么,它是什么回事?
先拿setnx来争抢锁,抢到之后,再用expire给锁加一个过期时间防止锁忘记了释放。
这时候对方会告诉你说你回答得不错,然后接着问如果在setnx之后执行expire之前进程意外crash或者要重启维护了,那会怎么样?
这时候你要给予惊讶的反馈:唉,是喔,这个锁就永远得不到释放了。紧接着你需要抓一抓自己得脑袋,故作思考片刻,好像接下来的结果是你主动思考出来的,然后回答:我记得set指令有非常复杂的参数,这个应该是可以同时把setnx和expire合成一条指令来用的!对方这时会显露笑容,心里开始默念:摁,这小子还不错。
96.假如Redis里面有1亿个key,其中有10w个key是以某个固定的已知的前缀开头的,如果将它们全部找出来?
使用keys指令可以扫出指定模式的key列表。
对方接着追问:如果这个redis正在给线上的业务提供服务,那使用keys指令会有什么问题?
这个时候你要回答redis关键的一个特性:redis的单线程的。keys指令会导致线程阻塞一段时间,线上服务会停顿,直到指令执行完毕,服务才能恢复。这个时候可以使用scan指令,scan指令可以无阻塞的提取出指定模式的key列表,但是会有一定的重复概率,在客户端做一次去重就可以了,但是整体所花费的时间会比直接用keys指令长。
97.使用过Redis做异步队列么,你是怎么用的?
一般使用list结构作为队列,rpush生产消息,lpop消费消息。当lpop没有消息的时候,要适当sleep一会再重试。
如果对方追问可不可以不用sleep呢?list还有个指令叫blpop,在没有消息的时候,它会阻塞住直到消息到来。
如果对方追问能不能生产一次消费多次呢?使用pub/sub主题订阅者模式,可以实现1:N的消息队列。
如果对方追问pub/sub有什么缺点?在消费者下线的情况下,生产的消息会丢失,得使用专业的消息队列如rabbitmq等。
如果对方追问redis如何实现延时队列?我估计现在你很想把面试官一棒打死如果你手上有一根棒球棍的话,怎么问的这么详细。但是你很克制,然后神态自若的回答道:使用sortedset,拿时间戳作为score,消息内容作为key调用zadd来生产消息,消费者用zrangebyscore指令获取N秒之前的数据轮询进行处理。
到这里,面试官暗地里已经对你竖起了大拇指。但是他不知道的是此刻你却竖起了中指,在椅子背后。
98.如果有大量的key需要设置同一时间过期,一般需要注意什么?
如果大量的key过期时间设置的过于集中,到过期的那个时间点,redis可能会出现短暂的卡顿现象。一般需要在时间上加一个随机值,使得过期时间分散一些。
99.Redis如何做持久化的?
bgsave做镜像全量持久化,aof做增量持久化。因为bgsave会耗费较长时间,不够实时,在停机的时候会导致大量丢失数据,所以需要aof来配合使用。在redis实例重启时,优先使用aof来恢复内存的状态,如果没有aof日志,就会使用rdb文件来恢复。
如果再问aof文件过大恢复时间过长怎么办?你告诉面试官,Redis会定期做aof重写,压缩aof文件日志大小。如果面试官不够满意,再拿出杀手锏答案,Redis4.0之后有了混合持久化的功能,将bgsave的全量和aof的增量做了融合处理,这样既保证了恢复的效率又兼顾了数据的安全性。这个功能甚至很多面试官都不知道,他们肯定会对你刮目相看。
如果对方追问那如果突然机器掉电会怎样?取决于aof日志sync属性的配置,如果不要求性能,在每条写指令时都sync一下磁盘,就不会丢失数据。但是在高性能的要求下每次都sync是不现实的,一般都使用定时sync,比如1s1次,这个时候最多就会丢失1s的数据。
如果对方追问bgsave的原理是什么?你给出两个词汇就可以了,fork和cow。fork是指redis通过创建子进程来进行bgsave操作,cow指的是copy on write,子进程创建后,父子进程共享数据段,父进程继续提供读写服务,写脏的页面数据会逐渐和子进程分离开来。
100.Pipeline有什么好处,为什么要用pipeline?
可以将多次IO往返的时间缩减为一次,前提是pipeline执行的指令之间没有因果相关性。使用redis-benchmark进行压测的时候可以发现影响redis的QPS峰值的一个重要因素是pipeline批次指令的数目。
101.Redis的同步机制了解么?
Redis可以使用主从同步,从从同步。第一次同步时,主节点做一次bgsave,并同时将后续修改操作记录到内存buffer,待完成后将rdb文件全量同步到复制节点,复制节点接受完成后将rdb镜像加载到内存。加载完成后,再通知主节点将期间修改的操作记录同步到复制节点进行重放就完成了同步过程。
102.是否使用过Redis集群,集群的原理是什么?
Redis Sentinal着眼于高可用,在master宕机时会自动将slave提升为master,继续提供服务。
Redis Cluster着眼于扩展性,在单个redis内存不足时,使用Cluster进行分片存储。
103.phpautoload实现机制
第一步是将PHP文件编译成普通称之为OPCODE的字节码序列(实际上是编译成一个叫做zend_op_array的字节数组),第二步是由一个虚拟机来执行这些OPCODE。PHP的所有行为都是由这些OPCODE来实现的。
PHP在实例化一个对象时(实际上在实现接口,使用类常数或类中的静态变量,调用类中的静态方法时都会如此),首先会在系统中查找该类(或接口)是否存在,如果不存在的话就尝试使用autoload机制来加载该类。而autoload机制的主要执行过程为:
(1) 检查执行器全局变量函数指针autoload_func是否为NULL。
(2) 如果autoload_func==NULL, 则查找系统中是否定义有__autoload()函数,如果没有,则报告错误并退出。
(3) 如果定义了__autoload()函数,则执行__autoload()尝试加载类,并返回加载结果。
(4) 如果autoload_func不为NULL,则直接执行autoload_func指针指向的函数用来加载类。注意此时并不检查__autoload()函数是否定义。
真相终于大白,PHP提供了两种方法来实现自动装载机制,一种我们前面已经提到过,是使用用户定义的__autoload()函数,这通常在PHP源程序中来实现;另外一种就是设计一个函数,将autoload_func指针指向它,这通常使用C语言在PHP扩展中实现。如果既实现了__autoload()函数,又实现了autoload_func(将autoload_func指向某一PHP函数),那么只执行autoload_func函数。 104.REST接口规范
GET (SELECT):从服务器检索特定资源,或资源列表。
POST (CREATE):在服务器上创建一个新的资源。
PUT (UPDATE):更新服务器上的资源,提供整个资源。
PATCH (UPDATE):更新服务器上的资源,仅提供更改的属性。
DELETE (DELETE):从服务器删除资源。
www.ruanyifeng.com/blog/2014/05/res...
105.Swoole
Swoole是一个PHP扩展,扩展不是为了提升网站的性能,是为了提升网站的开发效率。最少的性能损耗,换取最大的开发效率。利用Swoole扩展,开发一个复杂的Web功能,可以在很短的时间内完成了。
php的高级web开发框架
https://github.com/swoole/swoole-src106.php5中魔术方法有哪几个?请举例说明各自的用法。
1、__construct() :实例化对象时自动调用。
2、__destruct() :销毁对象或脚本执行结束时自动调用。
3、__call() :调用对象不存在得方法时执行此函数。
4、__get() :获取对象不存在的属性时执行此函数。
5、__set() :设置对象不存在的属性时执行此函数。
6、__isset() : 检测对象的某个属性是否存在时执行此函数。
7、__unset() :销毁对象的某个属性时执行此函数。
8、__toString() :将对象当作字符串输出时执行此函数。
9、__clone() :克隆对象时执行此函数。
10、__autoload() :实例化对象时,当类不存在时,执行此函数自动加载类。
11、__sleep() :serialize之前被调用,可以指定要序列化的对象属性。
12、__wakeup :unserialize之前被调用,可以执行对象的初始化工作。
13、set_state() :调用var_export时,被调用。用set_state的返回值做为var_export的返回值。
14、__invoke() :将对象当作函数来使用时执行此方法,通常不推荐这样做。
107.简述php的垃圾收集机制。
php中的变量存储在变量容器zval中,zval中除了存储变量类型和值外,还有is_ref和refcount字段。refcount表示指向变量的元素个数,is_ref表示变量是否有别名。如果refcount为0时,就回收该变量容器。如果一个zval的refcount减1之后大于0,它就会进入垃圾缓冲区。当缓冲区达到最大值后,回收算法会循环遍历zval,判断其是否为垃圾,并进行释放处理。108.一个文件的路径为/wwwroot/include/page.class.php,写出获得该文件扩展名的方法
$arr = pathinfo(“/wwwroot/include/page.class.php”);
$str = substr($arr[‘basename’],strrpos($arr[‘basename’],’.’));109.Yii2 的自动加载原理
1、检查类名是否已缓存在$classMap或$_coreClasses数组中,如果是则直接require相应的文件路径,$_coreClasses是框架自有类的映射表;否则去第2步;
2、检测YiiBase::$enableIncludePath是否为false,如果是则去第3步,否则直接include($className . '.php')
3、遍历$includePaths数组,将目录名拼接上类名,检查是否为合法的php文件,如果是则include,然后跳出循环
4、结束。 www.php.cn/php-weizijiaocheng-39315...
110.进程和线程的关系
进程就像地主,有土地(系统资源),线程就像佃户(线程,执行种地流程)。每个地主(进程)只要有一个干活的佃户(线程)。
进程-资源分配的最小单位,相对健壮,崩溃一般不影响其他进程,但是切换进程时耗费资源,效率差些。
线程-程序执行的最小单位,没有独立的地址空间,一个线程死掉可能整个进程就死掉,但是节省资源,切换效率高。111.php编程常见的进程和线程
1、在web应用中,我们每次访问php,就建立一个PHP进程,当然也会建立至少一个PHP线程。
2、PHP使用pcntl来进行多进程编程
3、PHP中使用pthreads来进行多线程编程
4、nginx的每个进程只有一个线程,每个线程可以处理多个客户端的访问
5、php-fpm使用多进程模型,每个进程只有一个线程,每个线程只能处理一个客户端访问。
6、apache可能使用多进程模型,也可能使用多线程模型,取决于使用哪种SAPI.
7、进程是cpu资源分配的最小单位,线程是cpu调度的最小单位112.打印前一天的时间
方式一:echo date('Y-m-d H:i:s','-1 day');
方式二:echo date("Y-m-d H:i:s",time()-24*3600);113.能够使HTML和PHP分离开使用的模板是什么
Smarty
我们用过的~114.什么是smarty,smarty有什么优点
Smarty是一个使用PHP写出来的PHP模板引擎,目的是要使用PHP程序同美工分离,使的程序员改变程序的逻辑内容时不会影响到美工的页面设计,美工重新修改页面时不会影响到程序的程序逻辑,这在多人合作的项目中显的尤为重要。
Smarty优点
1. 速度快:相对其他模板引擎。
2. 编译型:采用smarty编写的程序在运行时要编译成一个非模板技术的PHP文件
3. 缓存技术:它可以将用户最终看到的HTML文件缓存成一个静态的HTML页
4. 插件技术:smarty可以自定义插件。
不适合使用smarty的地方
1. 需要实时更新的内容。例如像股票显示,它需要经常对数据进行更新
2. 小项目。小项目因为项目简单而美工与程序员兼于一人的项目115.lnmp怎么开启https
第一步、部署SSL加密服务准备工作
1.申请SSL证书(百度免费SSL证书),我以阿里云提过的赛门铁克证书为例。
第二步、上传证书
将申请证书里的key文件和pem文件上传到/usr/local/nginx/conf/ssl/ 文件夹下,如果没有ssl文件夹,可以自己新建。
第三步、nginx里部署SSL,并301重定向http跳转至https
我们需要在站点对应的CONF文件设置。
修改设置如下
server
{
listen 80;
listen 443 ssl;
#listen [::]:80;
ssl on;
ssl_certificate /usr/local/nginx/conf/ssl/214346445970119.pem;
ssl_certificate_key /usr/local/nginx/conf/ssl/214346445970119.key;
server_name tuku.defcon.cn ;
if ($server_port !~ 443){
rewrite ^(.*)$ https://$host$1 permanent;
}
第四步、登录后台的强制开启SSL
修改的文件是 config.php,直接在这个文件的末尾添加两行代码:
/* 强制后台和登录使用 SSL */
define('FORCE_SSL_LOGIN', true);
define('FORCE_SSL_ADMIN', true);
第五步、注意以下需要修改的
修改“菜单”当中的所有“自定义链接”为相对路径;
修改“设置”→“常规”里的“站点地址”和“WordPress 地址”为 HTTPS;
修改其他自己手贱写入的绝对链接地址……
第六步、记得在服务器上开启443端口。
116.什么是csrf和xss
CSRF(Cross-site request forgery)跨站请求伪造,也被称为“One Click Attack”或者Session Riding,通常缩写为CSRF或者XSRF,是一种对网站的恶意利用。尽管听起来像跨站脚本(XSS),但它与XSS非常不同,XSS利用站点内的信任用户,而CSRF则通过伪装来自受信任用户的请求来利用受信任的网站。与XSS攻击相比,CSRF攻击往往不大流行(因此对其进行防范的资源也相当稀少)和难以防范,所以被认为比XSS更具危险性。
攻击通过在授权用户访问的页面中包含链接或者脚本的方式工作。例如:一个网站用户Bob可能正在浏览聊天论坛,而同时另一个用户Alice也在此论坛中,并且后者刚刚发布了一个具有Bob银行链接的图片消息。设想一下,Alice编写了一个在Bob的银行站点上进行取款的form提交的链接,并将此链接作为图片src。如果Bob的银行在cookie中保存他的授权信息,并且此cookie没有过期,那么当Bob的浏览器尝试装载图片时将提交这个取款form和他的cookie,这样在没经Bob同意的情况下便授权了这次事务。
跨站脚本攻击(Cross Site Scripting),为不和层叠样式表(Cascading Style Sheets, CSS)的缩写混淆,故将跨站脚本攻击缩写为XSS。恶意攻击者往Web页面里插入恶意Script代码,当用户浏览该页之时,嵌入其中Web里面的Script代码会被执行,从而达到恶意攻击用户的目的。XSS攻击分成两类,一类是来自内部的攻击,主要指的是利用程序自身的漏洞,构造跨站语句,如:dvbbs的showerror.asp存在的跨站漏洞。另一类则是来自外部的攻击,主要指的自己构造XSS跨站漏洞网页或者寻找非目标机以外的有跨站漏洞的网页。如当我们要渗透一个站点,我们自己构造一个有跨站漏洞的网页,然后构造跨站语句,通过结合其它技术,如社会工程学等,欺骗目标服务器的管理员打开。117.如何解决xss和csrf攻击
xss
把传入字符串的特殊字符进行html转码,例如> < ) ( " ' % ; & +,这些特殊字符很有可能就是被注入的代码。
csrf
2.1 首先项目里面引入事先写好的代码文件,这个里面主要是产生一个csrftoken session的代码。
2.2 在用户进入项目,还没有跳转到登录页面之前,我们通过代码文件产生一个token,然后把它传入登录页面,给它定义成csrf。
2.3 在登录页面里面,通过隐藏域来获取刚刚传入的csrf,这样当用户提交form表单的时候,这里的csrf就会一起被提交到后台的代码。
2.4 在后台代码里面,我们通过页面传入的token和已经产生的token session进行对比,如果两个相同,那么这些操作就认为是用户自己在操作,如果页面传入的和产生的token不相同那么这就是其他人员通过模拟用户进行了这样的操作,那么我们就要对它进行处理,让它跳转到登录页面。118.sql注入的思路及攻击实例
SQL注入攻击的总体思路
1.寻找到SQL注入的位置
2.判断服务器类型和后台数据库类型
3.针对不通的服务器和数据库特点进行SQL注入攻击
SQL注入攻击实例
比如在一个登录界面,要求输入用户名和密码:
可以这样输入实现免帐号登录:
用户名: ‘or 1 = 1 –
密 码:
点登陆,如若没有做特殊处理,那么这个非法用户就很得意的登陆进去了.(当然现在的有些语言的数据库API已经处理了这些问题)
这是为什么呢? 下面我们分析一下:
从理论上说,后台认证程序中会有如下的SQL语句:
String sql = "select * from user_table where username=
' "+userName+" ' and password=' "+password+" '";
当输入了上面的用户名和密码,上面的SQL语句变成:
SELECT * FROM user_table WHERE username=
'’or 1 = 1 -- and password='’
分析SQL语句:
条件后面username=”or 1=1 用户名等于 ” 或1=1 那么这个条件一定会成功;
然后后面加两个-,这意味着注释,它将后面的语句注释,让他们不起作用,这样语句永远都能正确执行,用户轻易骗过系统,获取合法身份。
这还是比较温柔的,如果是执行
SELECT * FROM user_table WHERE
username='' ;DROP DATABASE (DB Name) --' and password=''119.防止sql注入
1.(简单又有效的方法)PreparedStatement
采用预编译语句集,它内置了处理SQL注入的能力,只要使用它的setXXX方法传值即可。
使用好处:
(1).代码的可读性和可维护性.
(2).PreparedStatement尽最大可能提高性能.
(3).最重要的一点是极大地提高了安全性.
原理:
sql注入只对sql语句的准备(编译)过程有破坏作用
而PreparedStatement已经准备好了,执行阶段只是把输入串作为数据处理,
而不再对sql语句进行解析,准备,因此也就避免了sql注入问题.
2.使用正则表达式过滤传入的参数
要引入的包:
import java.util.regex.*;
正则表达式:
private String CHECKSQL = “^(.+)\\sand\\s(.+)|(.+)\\sor(.+)\\s$”;
判断是否匹配:
Pattern.matches(CHECKSQL,targerStr);
下面是具体的正则表达式:
检测SQL meta-characters的正则表达式 :
/(\%27)|(\’)|(\-\-)|(\%23)|(#)/ix
修正检测SQL meta-characters的正则表达式 :/((\%3D)|(=))[^\n]*((\%27)|(\’)|(\-\-)|(\%3B)|(:))/i
典型的SQL 注入攻击的正则表达式 :/\w*((\%27)|(\’))((\%6F)|o|(\%4F))((\%72)|r|(\%52))/ix
检测SQL注入,UNION查询关键字的正则表达式 :/((\%27)|(\’))union/ix(\%27)|(\’)
检测MS SQL Server SQL注入攻击的正则表达式:
/exec(\s|\+)+(s|x)p\w+/ix
3.字符串过滤
120.第三方支付常见几种支付方式的流程设计






121.如何设计支付接口
1.接口规则
传输方式 为保证交易安全性,采用HTTPS传输
提交方式 采用POST方法提交
数据格式 提交和返回数据都为XML格式,根节点名为xml
字符编码 统一采用UTF-8字符编码
签名算法 MD5,后续会兼容SHA1、SHA256、HMAC等。
签名要求 请求和接收数据均需要校验签名,详细方法请参考安全规范-签名算法
证书要求 调用申请退款、撤销订单接口需要商户证书
判断逻辑 先判断协议字段返回,再判断业务返回,最后判断交易状态
2.参数规定
1、交易金额
交易金额默认为人民币交易,接口中参数支付金额单位为【分】,参数值不能带小数。对账单中的交易金额单位为【元】。
外币交易的支付金额精确到币种的最小单位,参数值不能带小数点。
2、交易类型
JSAPI--JSAPI支付(或小程序支付)、NATIVE--Native支付、APP--app支付,MWEB--H5支付,不同trade_type决定了调起支付的方式,请根据支付产品正确上传
MICROPAY--付款码支付,付款码支付有单独的支付接口,所以接口不需要上传,该字段在对账单中会出现
3、货币类型
货币类型的取值列表:
CNY:人民币
4、时间
标准北京时间,时区为东八区;如果商户的系统时间为非标准北京时间。参数值必须根据商户系统所在时区先换算成标准北京时间, 例如商户所在地为0时区的伦敦,当地时间为2014年11月11日0时0分0秒,换算成北京时间为2014年11月11日8时0分0秒。
5、时间戳
标准北京时间,时区为东八区,自1970年1月1日 0点0分0秒以来的秒数。注意:部分系统取到的值为毫秒级,需要转换成秒(10位数字)。
6、商户订单号
商户支付的订单号由商户自定义生成,仅支持使用字母、数字、中划线-、下划线_、竖线|、星号*这些英文半角字符的组合,请勿使用汉字或全角等特殊字符。微信支付要求商户订单号保持唯一性(建议根据当前系统时间加随机序列来生成订单号)。重新发起一笔支付要使用原订单号,避免重复支付;已支付过或已调用关单、撤销(请见后文的API列表)的订单号不能重新发起支付。
7、body字段格式
使用场景 支付模式 商品字段规则 样例 备注
PC网站 扫码支付 浏览器打开的网站主页title名 -商品概述 腾讯充值中心-QQ会员充值
微信浏览器 公众号支付 商家名称-销售商品类目 腾讯-游戏 线上电商,商家名称必须为实际销售商品的商家
门店扫码 公众号支付 店名-销售商品类目 小张南山店-超市 线下门店支付
门店扫码 扫码支付 店名-销售商品类目 小张南山店-超市 线下门店支付
门店刷卡 刷卡支付 店名-销售商品类目 小张南山店-超市 线下门店支付
第三方手机浏览器 H5支付 浏览器打开的移动网页的主页title名-商品概述 腾讯充值中心-QQ会员充值
第三方APP APP支付 应用市场上的APP名字-商品概述 天天爱消除-游戏充值
8、银行类型
3.安全规范
1、签名算法
(签名校验工具)
签名生成的通用步骤如下:
第一步,设所有发送或者接收到的数据为集合M,将集合M内非空参数值的参数按照参数名ASCII码从小到大排序(字典序),使用URL键值对的格式(即key1=value1&key2=value2…)拼接成字符串stringA。
特别注意以下重要规则:
◆ 参数名ASCII码从小到大排序(字典序);
◆ 如果参数的值为空不参与签名;
◆ 参数名区分大小写;
◆ 验证调用返回或微信主动通知签名时,传送的sign参数不参与签名,将生成的签名与该sign值作校验。
◆ 微信接口可能增加字段,验证签名时必须支持增加的扩展字段
第二步,在stringA最后拼接上key得到stringSignTemp字符串,并对stringSignTemp进行MD5运算,再将得到的字符串所有字符转换为大写,得到sign值signValue。
◆ key设置路径:微信商户平台(pay.weixin.qq.com)-->账户设置-->API安全-->密钥设置
第一步:对参数按照key=value的格式,并按照参数名ASCII字典序排序如下:
第二步:拼接API密钥:
2、生成随机数算法
微信支付API接口协议中包含字段nonce_str,主要保证签名不可预测。我们推荐生成随机数算法如下:调用随机数函数生成,将得到的值转换为字符串。
3、API证书
(1)获取API证书(什么是api证书?如何升级?)
微信支付接口中,涉及资金回滚的接口会使用到API证书,包括退款、撤销接口。商家在申请微信支付成功后,收到的相应邮件后,可以按照指引下载API证书,也可以按照以下路径下载:微信商户平台(pay.weixin.qq.com)-->账户中心-->账户设置-->API安全 。证书文件说明如下:
证书附件 描述 使用场景 备注
pkcs12格式
(apiclient_cert.p12、 包含了私钥信息的证书文件,为p12(pfx)格式,由微信支付签发给您用来标识和界定您的身份 撤销、退款申请API中调用 windows上可以直接双击导入系统,导入过程中会提示输入证书密码,证书密码默认为您的商户ID(如:10010000)
以下两个证书在PHP环境中使用:
证书附件 描述 使用场景 备注
证书pem格式
(apiclient_cert.pem) 从apiclient_cert.p12中导出证书部分的文件,为pem格式,请妥善保管不要泄漏和被他人复制 PHP等不能直接使用p12文件,而需要使用pem,为了方便您使用,已为您直接提供 您也可以使用openssl命令来自己导出:openssl pkcs12 -clcerts -nokeys -in apiclient_cert.p12 -out apiclient_cert.pem
证书密钥pem格式
(apiclient_key.pem) 从apiclient_key.pem中导出密钥部分的文件,为pem格式,请妥善保管不要泄漏和被他人复制 PHP等不能直接使用p12文件,而需要使用pem,为了方便您使用,已为您直接提供 您也可以使用openssl命令来自己导出:openssl pkcs12 -nocerts -in apiclient_cert.p12 -out apiclient_key.pem
(2)使用API证书
◆ apiclient_cert.p12是商户证书文件,除PHP外的开发均使用此证书文件。
◆ 商户如果使用.NET环境开发,请确认Framework版本大于2.0,必须在操作系统上双击安装证书apiclient_cert.p12后才能被正常调用。
◆ API证书调用或安装需要使用到密码,该密码的值为微信商户号(mch_id)
(3)API证书安全
1.证书文件不能放在web服务器虚拟目录,应放在有访问权限控制的目录中,防止被他人下载;
2.建议将证书文件名改为复杂且不容易猜测的文件名;
3.商户服务器要做好病毒和木马防护工作,不被非法侵入者窃取证书文件。
4、商户回调API安全
在普通的网络环境下,HTTP请求存在DNS劫持、运营商插入广告、数据被窃取,正常数据被修改等安全风险。商户回调接口使用HTTPS协议可以保证数据传输的安全性。所以微信支付建议商户提供给微信支付的各种回调采用HTTPS协议。pay.weixin.qq.com/wiki/doc/api/app...
122.状态码
1 消息
▪ 100 Continue
▪ 101 Switching Protocols
▪ 102 Processing
2 成功
▪ 200 OK
▪ 201 Created
▪ 202 Accepted
▪ 203 Non-Authoritative Information
▪ 204 No Content
▪ 205 Reset Content
▪ 206 Partial Content
▪ 207 Multi-Status
3 重定向
▪ 300 Multiple Choices
▪ 301 Moved Permanently
▪ 302 Move temporarily
▪ 303 See Other
▪ 304 Not Modified
▪ 305 Use Proxy
▪ 306 Switch Proxy
▪ 307 Temporary Redirect
4 请求错误
▪ 400 Bad Request
▪ 401 Unauthorized
▪ 402 Payment Required
▪ 403 Forbidden
▪ 404 Not Found
▪ 405 Method Not Allowed
▪ 406 Not Acceptable
▪ 407 Proxy Authentication Required
▪ 408 Request Timeout
▪ 409 Conflict
▪ 410 Gone
▪ 411 Length Required
▪ 412 Precondition Failed
▪ 413 Request Entity Too Large
▪ 414 Request-URI Too Long
▪ 415 Unsupported Media Type
▪ 416 Requested Range Not Satisfiable
▪ 417 Expectation Failed
▪ 421 too many connections
▪ 422 Unprocessable Entity
▪ 423 Locked
▪ 424 Failed Dependency
▪ 425 Unordered Collection
▪ 426 Upgrade Required
▪ 449 Retry With
▪ 451Unavailable For Legal Reasons
5 服务器错误
▪ 500 Internal Server Error
▪ 501 Not Implemented
▪ 502 Bad Gateway
▪ 503 Service Unavailable
▪ 504 Gateway Timeout
▪ 505 HTTP Version Not Supported
▪ 506 Variant Also Negotiates
▪ 507 Insufficient Storage
▪ 509 Bandwidth Limit Exceeded
▪ 510 Not Extended
▪ 600 Unparseable Response Headers
100 客户端应当继续发送请求。这个临时响应是用来通知客户端它的部分请求已经被服务器接收,且仍未被拒绝。客户端应当继续发送请求的剩余部分,或者如果请求已经完成,忽略这个响应。服务器必须在请求完成后向客户端发送一个最终响应。
101 服务器已经理解了客户端的请求,并将通过Upgrade 消息头通知客户端采用不同的协议来完成这个请求。在发送完这个响应最后的空行后,服务器将会切换到在Upgrade 消息头中定义的那些协议。 只有在切换新的协议更有好处的时候才应该采取类似措施。例如,切换到新的HTTP 版本比旧版本更有优势,或者切换到一个实时且同步的协议以传送利用此类特性的资源。
102 由WebDAV(RFC 2518)扩展的状态码,代表处理将被继续执行。
200 请求已成功,请求所希望的响应头或数据体将随此响应返回。
201 请求已经被实现,而且有一个新的资源已经依据请求的需要而建立,且其 URI 已经随Location 头信息返回。假如需要的资源无法及时建立的话,应当返回 '202 Accepted'。
202 服务器已接受请求,但尚未处理。正如它可能被拒绝一样,最终该请求可能会也可能不会被执行。在异步操作的场合下,没有比发送这个状态码更方便的做法了。 返回202状态码的响应的目的是允许服务器接受其他过程的请求(例如某个每天只执行一次的基于批处理的操作),而不必让客户端一直保持与服务器的连接直到批处理操作全部完成。在接受请求处理并返回202状态码的响应应当在返回的实体中包含一些指示处理当前状态的信息,以及指向处理状态监视器或状态预测的指针,以便用户能够估计操作是否已经完成。
203 服务器已成功处理了请求,但返回的实体头部元信息不是在原始服务器上有效的确定集合,而是来自本地或者第三方的拷贝。当前的信息可能是原始版本的子集或者超集。例如,包含资源的元数据可能导致原始服务器知道元信息的超级。使用此状态码不是必须的,而且只有在响应不使用此状态码便会返回200 OK的情况下才是合适的。
204 服务器成功处理了请求,但不需要返回任何实体内容,并且希望返回更新了的元信息。响应可能通过实体头部的形式,返回新的或更新后的元信息。如果存在这些头部信息,则应当与所请求的变量相呼应。 如果客户端是浏览器的话,那么用户浏览器应保留发送了该请求的页面,而不产生任何文档视图上的变化,即使按照规范新的或更新后的元信息应当被应用到用户浏览器活动视图中的文档。 由于204响应被禁止包含任何消息体,因此它始终以消息头后的第一个空行结尾。
205 服务器成功处理了请求,且没有返回任何内容。但是与204响应不同,返回此状态码的响应要求请求者重置文档视图。该响应主要是被用于接受用户输入后,立即重置表单,以便用户能够轻松地开始另一次输入。 与204响应一样,该响应也被禁止包含任何消息体,且以消息头后的第一个空行结束。
206 服务器已经成功处理了部分 GET 请求。类似于 FlashGet 或者迅雷这类的 HTTP 下载工具都是使用此类响应实现断点续传或者将一个大文档分解为多个下载段同时下载。 该请求必须包含 Range 头信息来指示客户端希望得到的内容范围,并且可能包含 If-Range 来作为请求条件。 响应必须包含如下的头部域: Content-Range 用以指示本次响应中返回的内容的范围;如果是 Content-Type 为 multipart/byteranges 的多段下载,则每一 multipart 段中都应包含 Content-Range 域用以指示本段的内容范围。假如响应中包含 Content-Length,那么它的数值必须匹配它返回的内容范围的真实字节数。 Date ETag 和/或 Content-Location,假如同样的请求本应该返回200响应。 Expires, Cache-Control,和/或 Vary,假如其值可能与之前相同变量的其他响应对应的值不同的话。 假如本响应请求使用了 If-Range 强缓存验证,那么本次响应不应该包含其他实体头;假如本响应的请求使用了 If-Range 弱缓存验证,那么本次响应禁止包含其他实体头;这避免了缓存的实体内容和更新了的实体头信息之间的不一致。否则,本响应就应当包含所有本应该返回200响应中应当返回的所有实体头部域。 假如 ETag 或 Last-Modified 头部不能精确匹配的话,则客户端缓存应禁止将206响应返回的内容与之前任何缓存过的内容组合在一起。 任何不支持 Range 以及 Content-Range 头的缓存都禁止缓存206响应返回的内容。
207 由WebDAV(RFC 2518)扩展的状态码,代表之后的消息体将是一个XML消息,并且可能依照之前子请求数量的不同,包含一系列独立的响应代码。
300 被请求的资源有一系列可供选择的回馈信息,每个都有自己特定的地址和浏览器驱动的商议信息。用户或浏览器能够自行选择一个首选的地址进行重定向。 除非这是一个 HEAD 请求,否则该响应应当包括一个资源特性及地址的列表的实体,以便用户或浏览器从中选择最合适的重定向地址。这个实体的格式由 Content-Type 定义的格式所决定。浏览器可能根据响应的格式以及浏览器自身能力,自动作出最合适的选择。当然,RFC 2616规范并没有规定这样的自动选择该如何进行。 如果服务器本身已经有了首选的回馈选择,那么在 Location 中应当指明这个回馈的 URI;浏览器可能会将这个 Location 值作为自动重定向的地址。此外,除非额外指定,否则这个响应也是可缓存的。
301 被请求的资源已永久移动到新位置,并且将来任何对此资源的引用都应该使用本响应返回的若干个 URI 之一。如果可能,拥有链接编辑功能的客户端应当自动把请求的地址修改为从服务器反馈回来的地址。除非额外指定,否则这个响应也是可缓存的。 新的永久性的 URI 应当在响应的 Location 域中返回。除非这是一个 HEAD 请求,否则响应的实体中应当包含指向新的 URI 的超链接及简短说明。 如果这不是一个 GET 或者 HEAD 请求,因此浏览器禁止自动进行重定向,除非得到用户的确认,因为请求的条件可能因此发生变化。 注意:对于某些使用 HTTP/1.0 协议的浏览器,当它们发送的 POST 请求得到了一个301响应的话,接下来的重定向请求将会变成 GET 方式。
302 请求的资源现在临时从不同的 URI 响应请求。由于这样的重定向是临时的,客户端应当继续向原有地址发送以后的请求。只有在Cache-Control或Expires中进行了指定的情况下,这个响应才是可缓存的。 新的临时性的 URI 应当在响应的 Location 域中返回。除非这是一个 HEAD 请求,否则响应的实体中应当包含指向新的 URI 的超链接及简短说明。 如果这不是一个 GET 或者 HEAD 请求,那么浏览器禁止自动进行重定向,除非得到用户的确认,因为请求的条件可能因此发生变化。 注意:虽然RFC 1945和RFC 2068规范不允许客户端在重定向时改变请求的方法,但是很多现存的浏览器将302响应视作为303响应,并且使用 GET 方式访问在 Location 中规定的 URI,而无视原先请求的方法。状态码303和307被添加了进来,用以明确服务器期待客户端进行何种反应。
303 对应当前请求的响应可以在另一个 URI 上被找到,而且客户端应当采用 GET 的方式访问那个资源。这个方法的存在主要是为了允许由脚本激活的POST请求输出重定向到一个新的资源。这个新的 URI 不是原始资源的替代引用。同时,303响应禁止被缓存。当然,第二个请求(重定向)可能被缓存。 新的 URI 应当在响应的 Location 域中返回。除非这是一个 HEAD 请求,否则响应的实体中应当包含指向新的 URI 的超链接及简短说明。 注意:许多 HTTP/1.1 版以前的 浏览器不能正确理解303状态。如果需要考虑与这些浏览器之间的互动,302状态码应该可以胜任,因为大多数的浏览器处理302响应时的方式恰恰就是上述规范要求客户端处理303响应时应当做的。
304 如果客户端发送了一个带条件的 GET 请求且该请求已被允许,而文档的内容(自上次访问以来或者根据请求的条件)并没有改变,则服务器应当返回这个状态码。304响应禁止包含消息体,因此始终以消息头后的第一个空行结尾。 该响应必须包含以下的头信息: Date,除非这个服务器没有时钟。假如没有时钟的服务器也遵守这些规则,那么代理服务器以及客户端可以自行将 Date 字段添加到接收到的响应头中去(正如RFC 2068中规定的一样),缓存机制将会正常工作。 ETag 和/或 Content-Location,假如同样的请求本应返回200响应。 Expires, Cache-Control,和/或Vary,假如其值可能与之前相同变量的其他响应对应的值不同的话。 假如本响应请求使用了强缓存验证,那么本次响应不应该包含其他实体头;否则(例如,某个带条件的 GET 请求使用了弱缓存验证),本次响应禁止包含其他实体头;这避免了缓存了的实体内容和更新了的实体头信息之间的不一致。 假如某个304响应指明了当前某个实体没有缓存,那么缓存系统必须忽视这个响应,并且重复发送不包含限制条件的请求。 假如接收到一个要求更新某个缓存条目的304响应,那么缓存系统必须更新整个条目以反映所有在响应中被更新的字段的值。
305 被请求的资源必须通过指定的代理才能被访问。Location 域中将给出指定的代理所在的 URI 信息,接收者需要重复发送一个单独的请求,通过这个代理才能访问相应资源。只有原始服务器才能建立305响应。 注意:RFC 2068中没有明确305响应是为了重定向一个单独的请求,而且只能被原始服务器建立。忽视这些限制可能导致严重的安全后果。
306 在最新版的规范中,306状态码已经不再被使用。
307 请求的资源现在临时从不同的URI 响应请求。由于这样的重定向是临时的,客户端应当继续向原有地址发送以后的请求。只有在Cache-Control或Expires中进行了指定的情况下,这个响应才是可缓存的。 新的临时性的URI 应当在响应的 Location 域中返回。除非这是一个HEAD 请求,否则响应的实体中应当包含指向新的URI 的超链接及简短说明。因为部分浏览器不能识别307响应,因此需要添加上述必要信息以便用户能够理解并向新的 URI 发出访问请求。 如果这不是一个GET 或者 HEAD 请求,那么浏览器禁止自动进行重定向,除非得到用户的确认,因为请求的条件可能因此发生变化。
400 1、语义有误,当前请求无法被服务器理解。除非进行修改,否则客户端不应该重复提交这个请求。 2、请求参数有误。
401 当前请求需要用户验证。该响应必须包含一个适用于被请求资源的 WWW-Authenticate 信息头用以询问用户信息。客户端可以重复提交一个包含恰当的 Authorization 头信息的请求。如果当前请求已经包含了 Authorization 证书,那么401响应代表着服务器验证已经拒绝了那些证书。如果401响应包含了与前一个响应相同的身份验证询问,且浏览器已经至少尝试了一次验证,那么浏览器应当向用户展示响应中包含的实体信息,因为这个实体信息中可能包含了相关诊断信息。参见RFC 2617。
402 该状态码是为了将来可能的需求而预留的。
403 服务器已经理解请求,但是拒绝执行它。与401响应不同的是,身份验证并不能提供任何帮助,而且这个请求也不应该被重复提交。如果这不是一个 HEAD 请求,而且服务器希望能够讲清楚为何请求不能被执行,那么就应该在实体内描述拒绝的原因。当然服务器也可以返回一个404响应,假如它不希望让客户端获得任何信息。
404 请求失败,请求所希望得到的资源未被在服务器上发现。没有信息能够告诉用户这个状况到底是暂时的还是永久的。假如服务器知道情况的话,应当使用410状态码来告知旧资源因为某些内部的配置机制问题,已经永久的不可用,而且没有任何可以跳转的地址。404这个状态码被广泛应用于当服务器不想揭示到底为何请求被拒绝或者没有其他适合的响应可用的情况下。
405 请求行中指定的请求方法不能被用于请求相应的资源。该响应必须返回一个Allow 头信息用以表示出当前资源能够接受的请求方法的列表。鉴于 PUT,DELETE 方法会对服务器上的资源进行写操作,因而绝大部分的网页服务器都不支持或者在默认配置下不允许上述请求方法,对于此类请求均会返回405错误。
406 请求的资源的内容特性无法满足请求头中的条件,因而无法生成响应实体。 除非这是一个 HEAD 请求,否则该响应就应当返回一个包含可以让用户或者浏览器从中选择最合适的实体特性以及地址列表的实体。实体的格式由 Content-Type 头中定义的媒体类型决定。浏览器可以根据格式及自身能力自行作出最佳选择。但是,规范中并没有定义任何作出此类自动选择的标准。
407 与401响应类似,只不过客户端必须在代理服务器上进行身份验证。代理服务器必须返回一个 Proxy-Authenticate 用以进行身份询问。客户端可以返回一个 Proxy-Authorization 信息头用以验证。参见RFC 2617。
408 请求超时。客户端没有在服务器预备等待的时间内完成一个请求的发送。客户端可以随时再次提交这一请求而无需进行任何更改。
409 由于和被请求的资源的当前状态之间存在冲突,请求无法完成。这个代码只允许用在这样的情况下才能被使用:用户被认为能够解决冲突,并且会重新提交新的请求。该响应应当包含足够的信息以便用户发现冲突的源头。冲突通常发生于对 PUT 请求的处理中。例如,在采用版本检查的环境下,某次 PUT 提交的对特定资源的修改请求所附带的版本信息与之前的某个(第三方)请求向冲突,那么此时服务器就应该返回一个409错误,告知用户请求无法完成。此时,响应实体中很可能会包含两个冲突版本之间的差异比较,以便用户重新提交归并以后的新版本。
410 被请求的资源在服务器上已经不再可用,而且没有任何已知的转发地址。这样的状况应当被认为是永久性的。如果可能,拥有链接编辑功能的客户端应当在获得用户许可后删除所有指向这个地址的引用。如果服务器不知道或者无法确定这个状况是否是永久的,那么就应该使用404状态码。除非额外说明,否则这个响应是可缓存的。 410响应的目的主要是帮助网站管理员维护网站,通知用户该资源已经不再可用,并且服务器拥有者希望所有指向这个资源的远端连接也被删除。这类事件在限时、增值服务中很普遍。同样,410响应也被用于通知客户端在当前服务器站点上,原本属于某个个人的资源已经不再可用。当然,是否需要把所有永久不可用的资源标记为'410 Gone',以及是否需要保持此标记多长时间,完全取决于服务器拥有者。
411 服务器拒绝在没有定义 Content-Length 头的情况下接受请求。在添加了表明请求消息体长度的有效 Content-Length 头之后,客户端可以再次提交该请求。
412 服务器在验证在请求的头字段中给出先决条件时,没能满足其中的一个或多个。这个状态码允许客户端在获取资源时在请求的元信息(请求头字段数据)中设置先决条件,以此避免该请求方法被应用到其希望的内容以外的资源上。
413 服务器拒绝处理当前请求,因为该请求提交的实体数据大小超过了服务器愿意或者能够处理的范围。此种情况下,服务器可以关闭连接以免客户端继续发送此请求。如果这个状况是临时的,服务器应当返回一个 Retry-After 的响应头,以告知客户端可以在多少时间以后重新尝试。
414 请求的URI 长度超过了服务器能够解释的长度,因此服务器拒绝对该请求提供服务。这比较少见,通常的情况包括: 本应使用POST方法的表单提交变成了GET方法,导致查询字符串(Query String)过长。 重定向URI “黑洞”,例如每次重定向把旧的 URI 作为新的 URI 的一部分,导致在若干次重定向后 URI 超长。 客户端正在尝试利用某些服务器中存在的安全漏洞攻击服务器。这类服务器使用固定长度的缓冲读取或操作请求的 URI,当 GET 后的参数超过某个数值后,可能会产生缓冲区溢出,导致任意代码被执行[1]。没有此类漏洞的服务器,应当返回414状态码。
415 对于当前请求的方法和所请求的资源,请求中提交的实体并不是服务器中所支持的格式,因此请求被拒绝。
416 如果请求中包含了 Range 请求头,并且 Range 中指定的任何数据范围都与当前资源的可用范围不重合,同时请求中又没有定义 If-Range 请求头,那么服务器就应当返回416状态码。 假如 Range 使用的是字节范围,那么这种情况就是指请求指定的所有数据范围的首字节位置都超过了当前资源的长度。服务器也应当在返回416状态码的同时,包含一个 Content-Range 实体头,用以指明当前资源的长度。这个响应也被禁止使用 multipart/byteranges 作为其 Content-Type。
417 在请求头 Expect 中指定的预期内容无法被服务器满足,或者这个服务器是一个代理服务器,它有明显的证据证明在当前路由的下一个节点上,Expect 的内容无法被满足。
421 从当前客户端所在的IP地址到服务器的连接数超过了服务器许可的最大范围。通常,这里的IP地址指的是从服务器上看到的客户端地址(比如用户的网关或者代理服务器地址)。在这种情况下,连接数的计算可能涉及到不止一个终端用户。
422 从当前客户端所在的IP地址到服务器的连接数超过了服务器许可的最大范围。通常,这里的IP地址指的是从服务器上看到的客户端地址(比如用户的网关或者代理服务器地址)。在这种情况下,连接数的计算可能涉及到不止一个终端用户。
422 请求格式正确,但是由于含有语义错误,无法响应。(RFC 4918 WebDAV)423 Locked 当前资源被锁定。(RFC 4918 WebDAV)
424 由于之前的某个请求发生的错误,导致当前请求失败,例如 PROPPATCH。(RFC 4918 WebDAV)
425 在WebDav Advanced Collections 草案中定义,但是未出现在《WebDAV 顺序集协议》(RFC 3658)中。
426 客户端应当切换到TLS/1.0。(RFC 2817)
449 由微软扩展,代表请求应当在执行完适当的操作后进行重试。
500 服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理。一般来说,这个问题都会在服务器的程序码出错时出现。
501 服务器不支持当前请求所需要的某个功能。当服务器无法识别请求的方法,并且无法支持其对任何资源的请求。
502 作为网关或者代理工作的服务器尝试执行请求时,从上游服务器接收到无效的响应。
503 由于临时的服务器维护或者过载,服务器当前无法处理请求。这个状况是临时的,并且将在一段时间以后恢复。如果能够预计延迟时间,那么响应中可以包含一个 Retry-After 头用以标明这个延迟时间。如果没有给出这个Retry-After 信息,那么客户端应当以处理500响应的方式处理它。 注意:503状态码的存在并不意味着服务器在过载的时候必须使用它。某些服务器只不过是希望拒绝客户端的连接。
504 作为网关或者代理工作的服务器尝试执行请求时,未能及时从上游服务器(URI标识出的服务器,例如HTTP、FTP、LDAP)或者辅助服务器(例如DNS)收到响应。 注意:某些代理服务器在DNS查询超时时会返回400或者500错误
505 服务器不支持,或者拒绝支持在请求中使用的 HTTP 版本。这暗示着服务器不能或不愿使用与客户端相同的版本。响应中应当包含一个描述了为何版本不被支持以及服务器支持哪些协议的实体。
506 由《透明内容协商协议》(RFC 2295)扩展,代表服务器存在内部配置错误:被请求的协商变元资源被配置为在透明内容协商中使用自己,因此在一个协商处理中不是一个合适的重点。
507 服务器无法存储完成请求所必须的内容。这个状况被认为是临时的。WebDAV (RFC 4918)
509 服务器达到带宽限制。这不是一个官方的状态码,但是仍被广泛使用。
510 获取资源所需要的策略并没有没满足。(RFC 2774)123. 如何使用git提交 合并 解决冲突?
124.interface 和 api接口有什么区别?
125.access-token是什么 ?
126.什么是curl?
127.什么是php curl?
128.json_encode 和json_decode 区别?
129. 请讲出几个你常用的设计模式
130.请写一个算法列子(冒泡等)
131.php如何实现多线程2018以后版本
第一种:
利用旧的exec函数通过异步处理方法实现多线程的,exec函数本身就是一个执行外部程序的php函数。
第二:
用于多线程的方法(pthreads)
它可以比上面使用exec的方法更简单。
详情看 :www.php.cn/php-weizijiaocheng-4147...
132. PHP7 和 PHP5 的区别,具体多了哪些新特性?
性能提升了两倍
结合比较运算符 (<=>)
标量类型声明
返回类型声明
try…catch 增加多条件判断,更多 Error 错误可以进行异常处理
匿名类,现在支持通过new class 来实例化一个匿名类,这可以用来替代一些“用后即焚”的完整类定义
…… 了解更多查看文章链接 PHP7 新特性
133. 为什么 PHP7 比 PHP5 性能提升了?
变量存储字节减小,减少内存占用,提升变量操作速度
改善数组结构,数组元素和 hash 映射表被分配在同一块内存里,降低了内存占用、提升了 cpu 缓存命中率
改进了函数的调用机制,通过优化参数传递的环节,减少了一些指令,提高执行效率
134. laravel,服务提供者是什么?
服务提供者是所有 Laravel 应用程序引导启动的中心, Laravel 的核心服务器、注册服务容器绑定、事件监听、中间件、路由注册以及我们的应用程序都是由服务提供者引导启动的。
135. IoC 容器是什么?
IoC(Inversion of Control)译为 「控制反转」,也被叫做「依赖注入」(DI)。什么是「控制反转」?对象 A 功能依赖于对象 B,但是控制权由对象 A 来控制,控制权被颠倒,所以叫做「控制反转」,而「依赖注入」是实现 IoC 的方法,就是由 IoC 容器在运行期间,动态地将某种依赖关系注入到对象之中。
其作用简单来讲就是利用依赖关系注入的方式,把复杂的应用程序分解为互相合作的对象,从而降低解决问题的复杂度,实现应用程序代码的低耦合、高扩展。
Laravel 中的服务容器是用于管理类的依赖和执行依赖注入的工具。
136. Facades 是什么?
Facades(一种设计模式,通常翻译为外观模式)提供了一个”static”(静态)接口去访问注册到 IoC 容器中的类。提供了简单、易记的语法,而无需记住必须手动注入或配置的长长的类名。此外,由于对 PHP 动态方法的独特用法,也使测试起来非常容易。
137. Contract 是什么?
Contract(契约)是 laravel 定义框架提供的核心服务的接口。Contract 和 Facades 并没有本质意义上的区别,其作用就是使接口低耦合、更简单。
138. 依赖注入的原理?
依赖注入(DI)和控制反转(IOC)是从不同的角度的描述的同一件事情,就是指通过引入IOC容器,利用依赖关系注入的方式,实现对象之间的解耦。
我们把依赖注入应用到软件系统中,再来描述一下这个过程:
对象A依赖于对象B,当对象 A需要用到对象B的时候,IOC容器就会立即创建一个对象B送给对象A。IOC容器就是一个对象制造工厂,你需要什么,它会给你送去,你直接使用就行了,而再也不用去关心你所用的东西是如何制成的,也不用关心最后是怎么被销毁的,这一切全部由IOC容器包办。
在传统的实现中,由程序内部代码来控制组件之间的关系。我们经常使用new关键字来实现两个组件之间关系的组合,这种实现方式会造成组件之间耦合。IOC很好地解决了该问题,它将实现组件间关系从程序内部提到外部容器,也就是说由容器在运行期将组件间的某种依赖关系动态注入组件中。
139.什么是 Composer, 工作原理是什么?
Composer 是 PHP 的一个依赖管理工具。工作原理就是将已开发好的扩展包从 packagist.org composer 仓库下载到我们的应用程序中,并声明依赖关系和版本控制。
####140. 什么是索引,作用是什么?常见索引类型有那些?Mysql 建立索引的原则?
索引是一种特殊的文件,它们包含着对数据表里所有记录的引用指针,相当于书本的目录。其作用就是加快数据的检索效率。常见索引类型有主键、唯一索引、复合索引、全文索引。
索引创建的原则
最左前缀原理
选择区分度高的列作为索引
尽量的扩展索引,不要新建索引
高并发如何处理?
使用缓存
优化数据库,提升数据库使用效率
负载均衡
####141. 设计模式之SOLID原则
php设计模式不多说了,但是记住,要能讲出来.
SRP 单一责任原则
OCP 开放封闭原则
LSP 里氏替换原则
ISP 接口隔离原则
DIP 依赖倒置原则
####142. 其他php问题
- 分库分表怎么设计
- 如何处理 MySQL 死锁?
- 谈谈你对闭包的理解
- PHP 内存回收机制
- 如何解决 PHP 内存溢出问题
- 数据库优化的方法
- 简述 Laravel 的运行原理
- Laravel 路由实现原理
- cookie 和 session 区别,session
- 保存在服务器的哪里?服务端是如何获取客户端的cookie?
- 服务器集群搭建、负载均衡、反向代理
- 服务器常用命令
本作品采用《CC 协议》,转载必须注明作者和本文链接



































 关于 LearnKu
关于 LearnKu




推荐文章: