
py 爬取某网站直播集锦-抓取组装得到详情页视频集锦 url-现场敲代码
0 / 0 / 创建于 6年前
 wangchunbo 的个人博客
wangchunbo 的个人博客
分析 抓取二级页
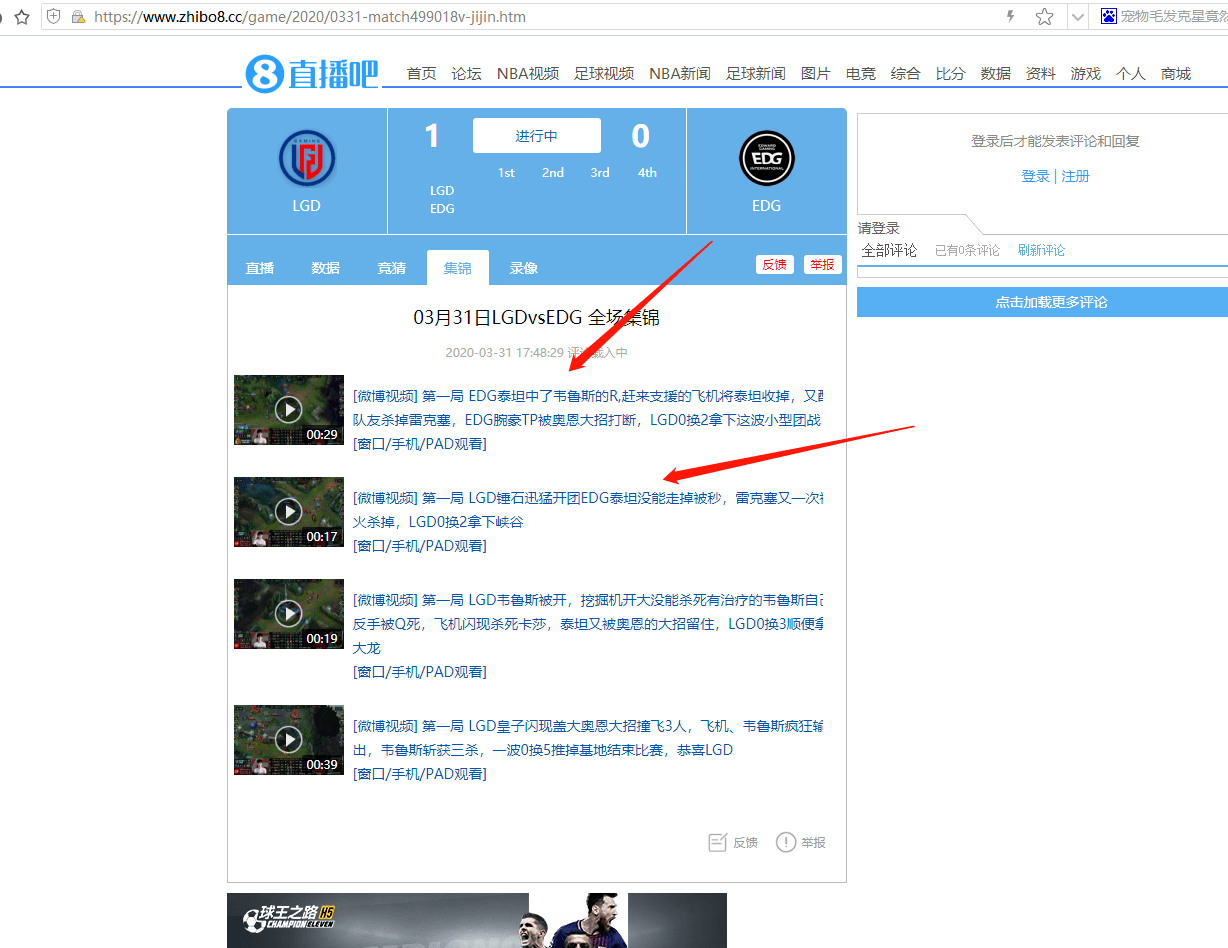
这里二级页,打开查看元素。
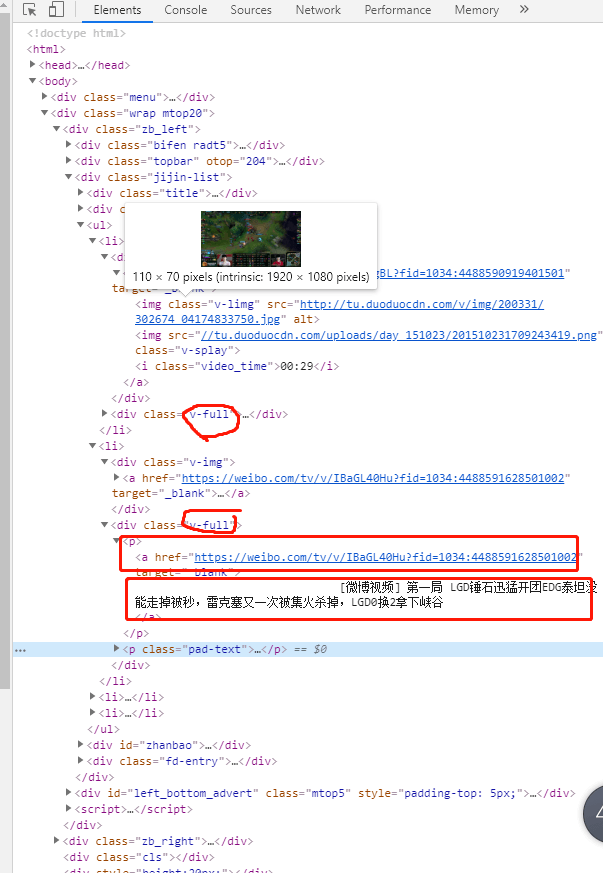
规则
如图,找到li 中的 v-full,下的a 标签。
附上代码
<a href="https://weibo.com/tv/v/IBaGL40Hu?fid=1034:4488591628501002" target="_blank">
[微博视频] 第一局 LGD锤石迅猛开团EDG泰坦没能走掉被秒,雷克塞又一次被集火杀掉,LGD0换2拿下峡谷 </a>
编写方法 getVideoList
附上代码
# 根据传入的 录像 集锦 来 执行爬虫。
def getVideoList(matches):
video_list = []
for i in matches:
doc = getLxml(i , lambda resp: BeautifulSoup(resp.text, 'lxml'))
# print('resp: ', doc)
if doc is None:
continue
for a in doc.select('.v-full a'):
title, href = a.text.strip(), a.attrs['href']
if next(filter(lambda v: v[1] == href, video_list), None) is None:
video_list.append((title, href))
print('video_list: ', video_list)
技术解析 BeautifulSoup
BeautifulSoup4简介
BeautifulSoup4和 lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据。
BeautifulSoup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它,则 Python 会使用 Python默认的解析器,lxml 解析器更加强大,速度更快,推荐使用lxml 解析器。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
下一篇会介绍。请查看。
爬取 录像页面
同理
最后附上执行结果
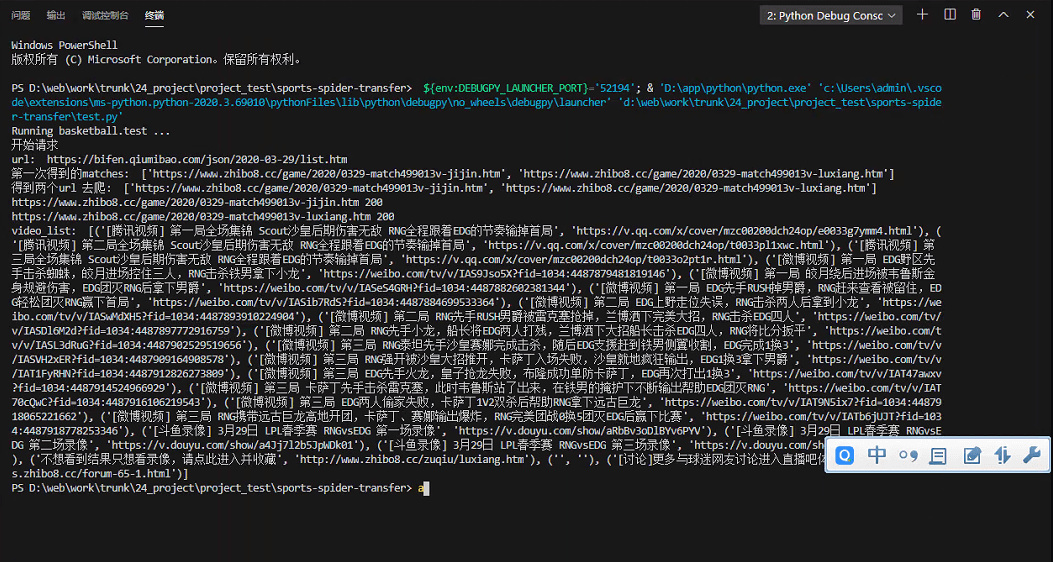
结束,成功!
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu




推荐文章: