
DevOps 自动化实践 — K8s 自动化执行 Database Migration
2 / 9 / 创建于 6年前 /
 RightCapital 的个人博客
RightCapital 的个人博客
Database Migration 是什么
Database migration,译为数据库迁移,使用代码来定义对数据库数据库的修改变更。相比手动编写 SQL,DB migration 将数据库的修改代码化、自动化,并方便在不同环境中同步这些变更。
我们遇到的问题
在早期我们的产品部署到 EC2 后,由人工 SSH 上机器执行 migration,这在当时虽然不理想,但可以接受。
后来随着团队的扩大以及部署流程逐渐自动化,由 CI 部署应用到 Kubernetes 集群,此时继续依靠人工执行 migration 给我们带来了几个问题:
- 需要沟通且容易遗漏:我们的产品会每周 cut 一个 release 到 producton。但并不是每个 release 都包含数据库变更,所以需要开发团队告知运维团队,某次 release 要处理 migration,但我们有遇到过几次由于沟通失效导致的遗漏执行 migration 的情况。
- Migration 可能在执行中被中断:在 Kubernetes node 资源不足的情况下,Pod 可能被 reschedule 到其它节点,原有 Pod 将会被 terminated。假如此刻正在使用
kubectl exec运行 migration,该过程很有可能被打断,出现不可预料的「中间状态」。 - 数据库需要备份:为了确保数据的安全性,我们希望在每次执行 migration 之前先完整备份数据库,但依靠人工处理不仅浪费了宝贵的工程师时间,还容易造成 human error。
综上,我们决定将执行 migration 的过程自动化。
使用 Job 自动化执行
为了把 migration 的执行过程自动化,我们在 Helm chart 内添加了一个 Job 资源,在每次部署时都创建一个新的 Job。
与普通的 Job 不同,执行 migration 的 Job 需要保证:
- Pod 优先级高,尽可能不中断。
- 禁止自动重试,一旦执行失败则必须人工介入,确保数据安全。
- 命名唯一不冲突,每次 Helm 部署都应该创建一个全新的 Job。
- 由于每次部署会产生新的 Job,因此成功运行完成一段时间后应当自行删除。
- 需要数据库 root 密码。
基于这些要求,我们编写的 Job 大概长这样:
{{- $fullName := printf "migration-%s" (include "chart.fullname" .) -}}
---
apiVersion: batch/v1
kind: Job
metadata:
name: {{ $fullName }}.{{ .Release.Revision }}
labels:
# 略
spec:
ttlSecondsAfterFinished: 172800 # 2 days
backoffLimit: 0
template:
metadata:
# 略
spec:
priorityClassName: high-priority-class
terminationGracePeriodSeconds: 86400 # 24 hours
restartPolicy: Never
containers:
- name: php
# 部分略
env:
- name: DB_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: {{ include "chart.fullname" . }}-db-root-password
key: dbRootPassword
args:
- php
- artisan
- migrate
- --force可以看到:
- 在 PodSpec 中,我们配置了超长的
terminationGracePeriodSeconds,即使收到 terminate 信号,也留有足够的时间让 migration 跑完。更重要的是,我们给这个 Pod 非常高的优先级(priorityClassName字段),当 Kubernetes 因资源问题开始驱逐 Pod 时,能够尽可能保证高优先级 Pod 的正常运行。 - Job 的
backoffLimit: 0,Pod 的restartPolicy: Never,确保 Job 不会重试、Pod 不会重启。 - Job 的命名与 helm release 的 revision 挂钩,因此能够保证每次部署时唯一。
- Job 的
ttlSecondsAfterFinished为172800秒,在 Job 成功执行完成后 48 小时会自动被删除。 - 在 Container
env内注入了名为DB_ROOT_PASSWORD的环境变量,值引用自一个单独的 secret 而不是直接填写明文,确保安全。关于机密信息的存放和管理,我们之前曾介绍过相关方案,可参考我们的前作《使用 SOPS 管理 Secret》。
另外,如果你也在使用 Laravel,在 APP_ENV 为 production 时执行 migration 会有这样的 interactive prompt:
**************************************
* Application In Production! *
**************************************
Do you really wish to run this command? (yes/no) [no]:
>而 Pod 运行环境中不存在 TTY,因此别忘了给 php artisan migrate 命令加上 --force 参数,强制在 production 环境下直接运行。
自定义的 Migrate 命令
由于 Laravel 自带的 php artisan migrate 命令无法完全满足需求,我们在其上做了一层封装,并自定义了一些附加功能。
自动进入 Maintenance 状态
为了保证数据一致性,在迁移过程中不应当有业务请求更新数据。因此在开始 migrate 之前,应用需要进入 maintenance 状态;在 migration 成功完成后,应当恢复服务。因此我们在调用 php artisan migrate 之前分别调用了 php artisan down 和 php artisan up。另外我们还指定了 --message 选项以便于分辨维护原因:
Artisan::call('down', ['--message' => 'running migration'], $this->output);
// ...
Artisan::call('up', [], $this->output);自动备份数据
我们使用的数据库是 AWS RDS。为了防止自动化迁移出现任何预料外的问题,我们在 migrate:privileged 命令中,通过 AWS PHP SDK 调用 CreateDBSnapshot API,为 RDS 创建 Snapshot。一旦迁移失败,我们可以通过 Snapshot 将数据回滚到迁移前的状态。
禁止同时执行多个 Migration
虽然概率极小,但考虑到以下两种情况:
- 两次 CI pipeline 时间非常接近,前者的 migrations 还没有运行完,第二个 migration job 就被创建出来同时开始运行。
- 出现问题需要手动执行 migration,此时另一个 migration job 还正在运行。
为了避免这两种可能导致数据异常的情况出现,我们还在该命令内加了互斥锁,同一时间内只能有单个实例在运行。
Slack 通知
最后,我们给整个流程加上了 Slack 通知,以便于工程师们实时得知 migration 的执行状况:
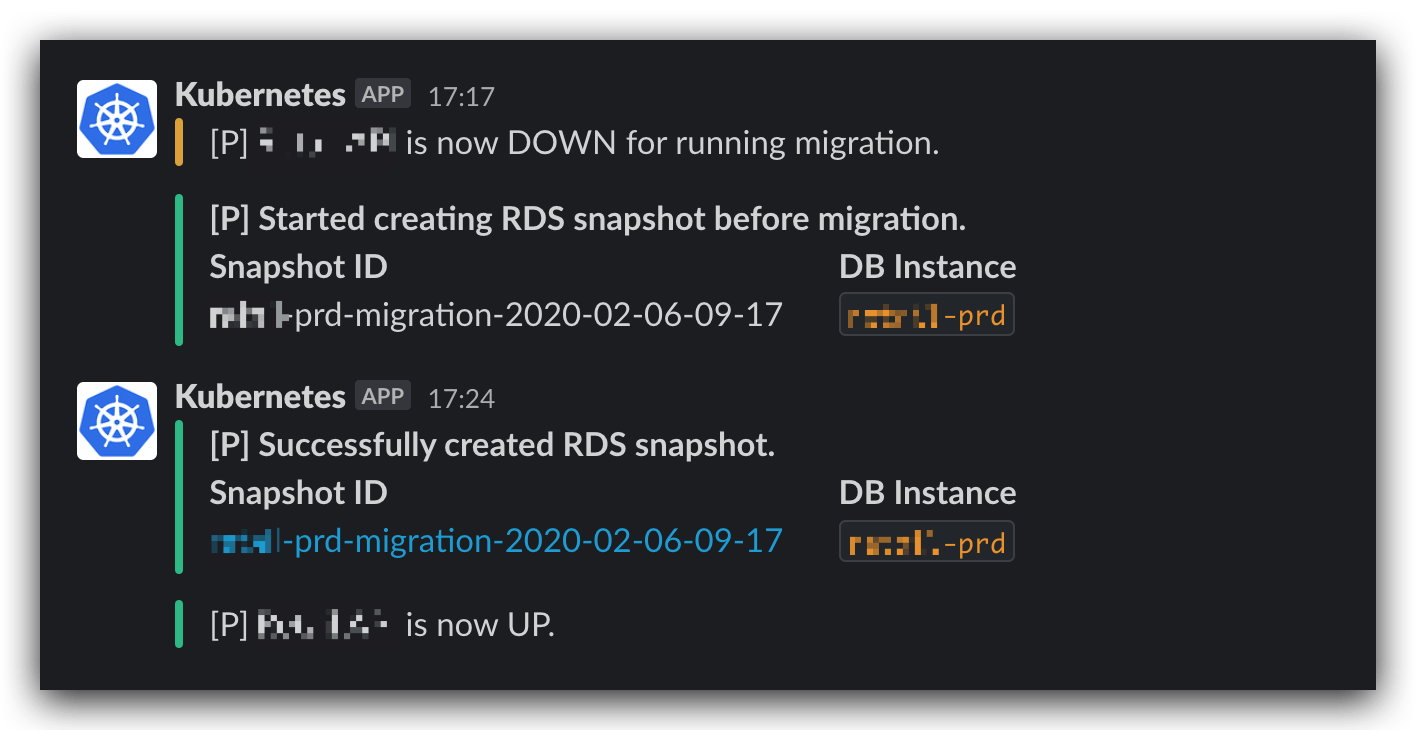
通过监听 \Illuminate\Console\Events\CommandFinished 事件,在 php artisan down 和 up 被调用后,将 message 通知到 Slack。
final class MaintenanceNotification
{
public function handle(CommandFinished $event): void
{
if (!in_array($event->command, ['up', 'down'], true)) {
return;
}
if ($event->command === 'down') {
$message = $event->input->getOption('message') === null ? 'maintenance' : $event->input->getOption('message');
}
if (app()->isDownForMaintenance()) {
$color = 'warning';
$text = "API is now DOWN for $message.";
} else {
$color = 'good';
$text = "API is now UP.";
}
// Send to Slack webhook...
}
}本作品采用《CC 协议》,转载必须注明作者和本文链接


















 关于 LearnKu
关于 LearnKu




推荐文章: