
DevOps 自动化实践 —— Incident 工作流
5 / 0 / 创建于 5年前
 RightCapital 的个人博客
RightCapital 的个人博客
作为 DevOps 难免遇到各种 alert 和 incident,如何高效可靠地管理这些意外事件成了 DevOps 工作流程中不可避免的话题。本篇文章为大家介绍我们的 incident 工作流,和一些实践过程中总结的经验。
Incident 来源
Incident 的来源有许多,例如客服团队人工上报、监控系统发出的 alert 等。我们绝大多数 incident 都源自后者,而 alert 则分别来自白盒、黑盒、基础设施的监控。
白盒监控
所谓白盒监控,重点在于关注应用内部的指标,例如每秒请求数。力求在用户可察觉的意外发生前,将它们扼杀在源头。
我们采用的是 Prometheus + Alertmanager 的组合。Prometheus 通过 exporters 采集各个应用内部的指标,计算告警规则表达式,并将符合规则的告警发送给 Alertmanager。
Node Exporter <---+
Kube-state-metrics <---| +------------+
Nginx exporter <-------+ Prometheus |
Redis exporter <---| +------+-----+
... <---+ |
|
+------+ | +-------+
| ^ v v |
| Evaluate alert rules |
+----------+-----------+
|
Send alerts if |
any condition hits |
|
+-------v------+
| Alertmanager |
+-------+------+
|
v
+--+--+
| ? |
+-----+我们在之前的文章中有梳理过 Prometheus 配合 Alertmanager 的详细用法,本文不再展开相关内容。
黑盒监控
黑盒监控更多关注的是「正在发生的事件」,例如某应用响应时间过高。它们常常与用户的角色一致,与用户可观察到的现象一致。尽可能在意外发生时,能够及时上报问题,而不是等待用户的反馈。
曾经我们选用的是 StatusCake 作为探针,定时向我们的服务发起请求,若出现超时、拒绝连接、响应未包含特定内容等问题则触发告警。但后来偶然一次被我们发现,部分监控意外停止超过一个小时,此时服务宕机完全没有任何告警,StatusCake 官方也没有及时告知这一问题,后续跟 StatusCake Support 确认是 bug:
Hi there,
We’ve since resolved this issue and we have credited a half month’s credit to your account to be deducted from the next subscription cost. The issue at the time was related to an error on a single testing server.
My apologies for the inconvenience here and won’t see that happen again!
Kind regards,
StatusCake Team
我们不确定此前是否有过类似事件我们没有发现,加上用户交互体验较差等因素,我们决定彻底放弃 StatusCake 转向 Pingdom。
+---------+
| Pingdom |
+---+--+--+
| |
Continuously sending | | Send alerts if
requests to probe | | the services are
the black box | | considered down
+------+ |
| |
+------v---+ +v----+
| Services | | ? |
+----------+ +-----+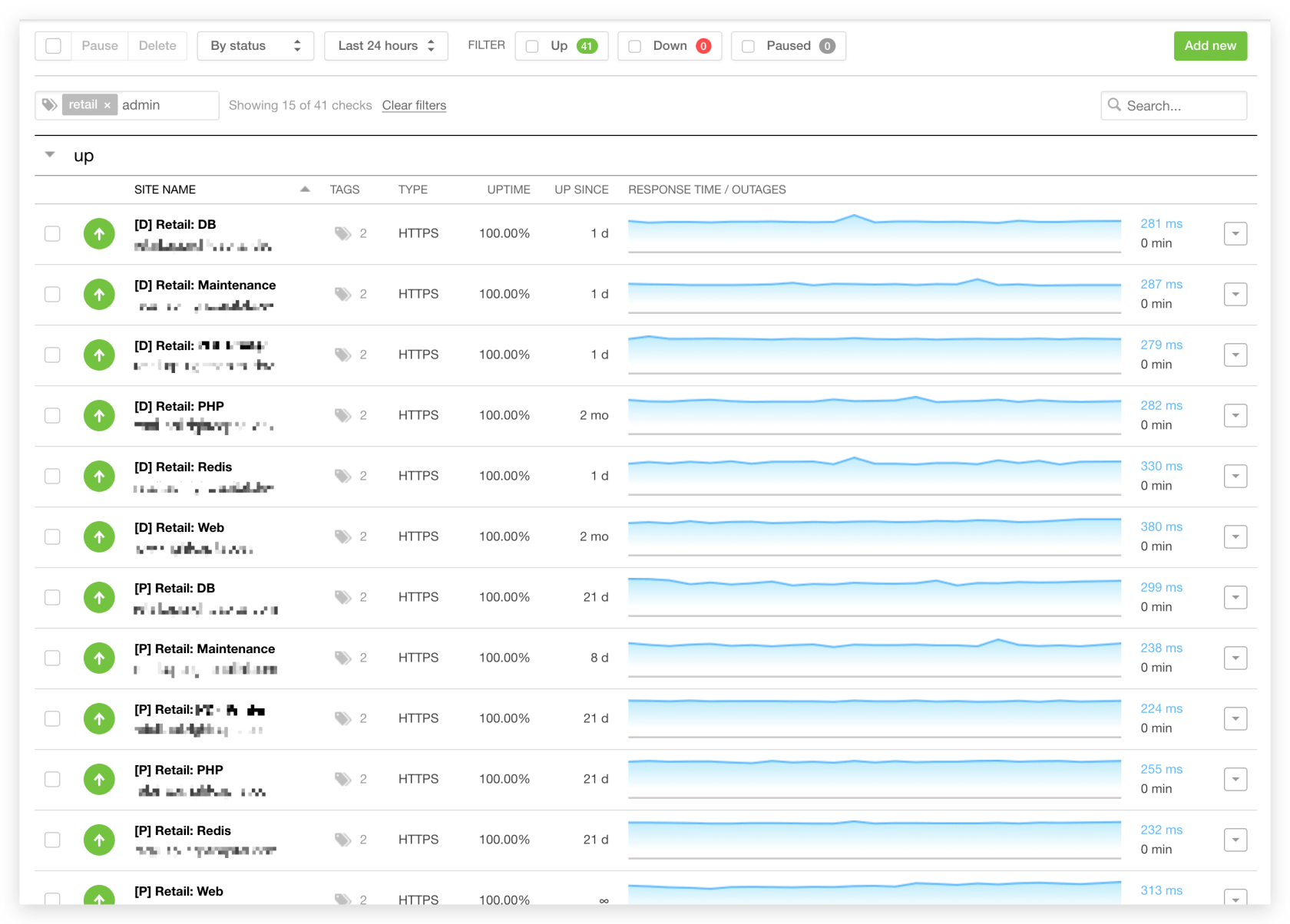
从图中可以看到我们创建了大量的监控项,尽可能多地覆盖每个项目、每个环境、每个独立组件,让 Pingdom 帮助我们时刻关注着各项服务的状态。
对于定时任务的监控我们选用了 Cronitor,在之前的文章有过详细介绍。
以上这些监控项我们全部使用 Terraform 代码化管理。同时,我们强烈建议使用第三方服务作为黑盒监控,而不是基于 AWS、Azure 之类的云服务自主搭建。例如 StatusCake 就在帮助文档中 明确表示 有大量合作供应商,绝对不用 AWS 或者 Azure 的节点,以避免单点故障问题。我们认为黑盒监控是 incident 工作流中非常重要的一环,需要尽最大可能避免由于云服务商出现大规模故障而导致监控失效。虽然这种可能性非常非常之小,但不是没有发生过,例如当年 AWS S3 出现故障导致无法更新 status dashboard,因为警告图标就存放在宕机的服务上。
基础设施监控
除了应用的白盒监控、服务的黑盒监控之外,基础设施监控也是比较重要的一环。我们的主要云服务提供商是 AWS,使用了 RDS、SQS、ElastiCache 等 AWS managed 的服务,因此也需要关注它们的指标和告警信息。这部分我们采用的是 AWS 官方的 Amazon CloudWatch。
限于篇幅,基础设施的告警通常比较少见,此处不再详细展开。
Incident 通知
Incident 发生后,相关信息应当通知到 DevOps。我们目前规定了两个主要途径作为 Incident 的「出口」。
Slack
作为我司内部的即时沟通工具,Slack 同时承担了大量的消息通知工作,包括 GitLab、Cronitor 等。我们为告警信息创建了一个单独的 channel 叫做 #ops-alerts。
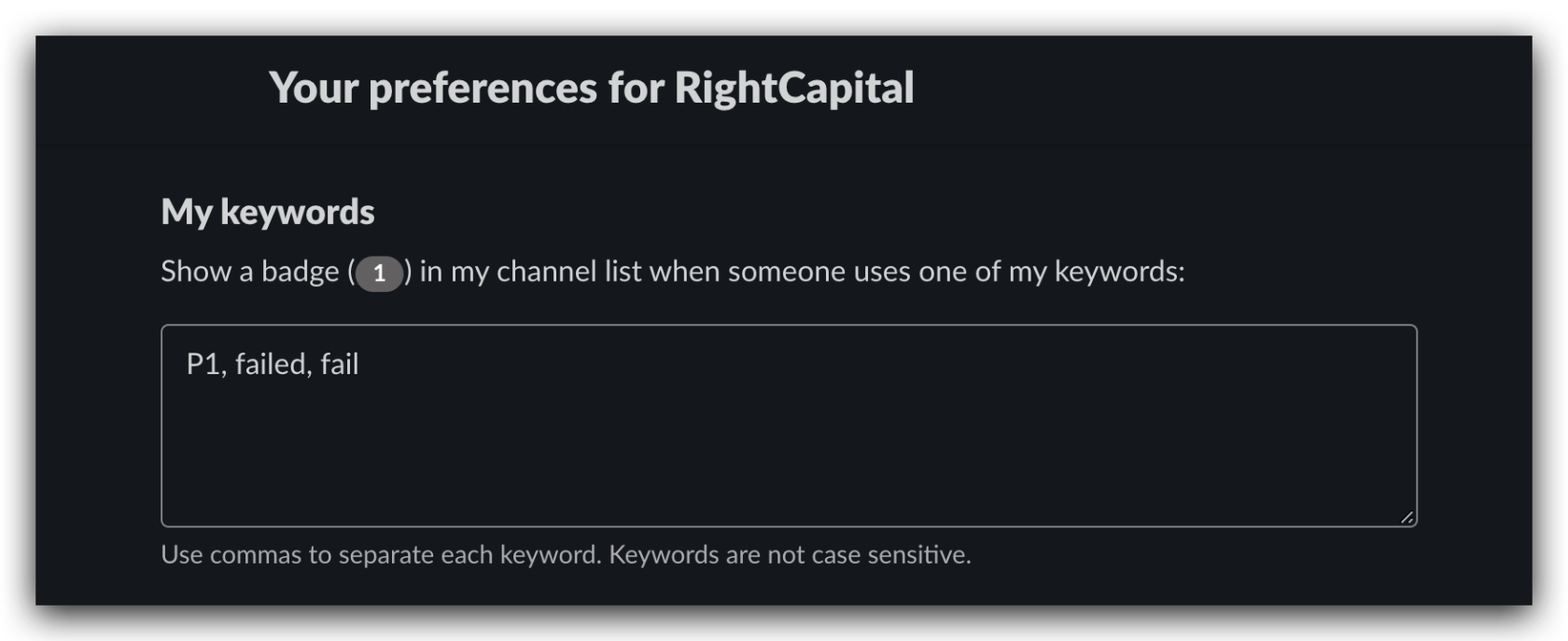
DevOps 团队成员将该频道的 Notification Preferences 改为 Every new messages,或是在全局 Preferences -> Notifications -> My keywords 中配置好例如 failed、warning 之类的关键字,即可确保通知消息能够及时送达 iPhone、iMac 等终端。

On-call
国内 on-call 工作机制似乎不太普遍,简单来说,就是随时做好接听「告警通知电话」的准备。
虽然 DevOps 工程师会尽可能关注 Slack 通知,但还有些时候不一定能够及时收到告警信息,例如:
- 非工作时间,
- 漏看消息,
- 正在处理其它问题等。
如果发生比较紧急的告警,例如 production down,需要立刻被处理。于是我们配置了 on-call,由 DevOps 工程师轮流值班,根据 on-call schedule,将优先级较高的 incident 通过文字转语音(TTS)拨打电话通知到人。
另外,DevOps 团队还会把告警的电话号码加入 iPhone 联系人,并打开 Emergency Bypass,这样就不用担心误触静音开关或是勿扰模式接不到电话了。

连接来源与通知并规划工作流
Opsgenie 是一款 Atlassian 旗下的 incident 管理产品。它提供了大量的 integrations,从 AWS CloudWatch、Pingdom 之类的监控系统,到 Slack、RingCentral 等通讯工具。这使得它几乎能从任何来源接收 alert、创建 incident,又能把这些 incident 以各种各样的方式通知到负责人员。
例如在上文中提到的几款产品:
另外,在工程师收到告警通知后,应当第一时间 acknowledge,表示已知悉:

如果没有在特定时间内 acknowledge,该报警信息将会被 escalate,将通知信息发送给更高等级的负责人。
Opsgenie 还提供了一个清晰的 dashboard。它能够在 DevOps 收到通知后,提供详细的 incident 信息;另外由于多个来源的 alert 汇总在同一页面,这会帮助 DevOps 了解此时整个系统的宏观状态,有助于排查问题的根本原因。

我们还对不同来源、tag 的 alert 标记了不同的优先级,例如 P1 和 P3。在上图中的两个 Watchdog 告警均为 P3 优先级。P1 优先级的 incident 将会 On-call 通知,其它优先级则通过 Slack 消息。
+--------------+ +---------+ +------------+
| Alertmanager | | Pingdom | | CloudWatch |
+------+-------+ +---+-----+ +---------+--+
| | |
| | |
+-----------v v v---------------+
+-----+------+
| |
| Opsgenie |
| |
+----+--+----+
| |
P1| |P3
Alerts| |Alerts
| |
+---------+ | | +-------+
| On-call | <---+ +---> | Slack |
+---------+ +-------+总结
以上就是我们的 incident 工作流,欢迎与我们分享你的经验。
请关注我们的微信公众号「rightcapital」

本作品采用《CC 协议》,转载必须注明作者和本文链接









 关于 LearnKu
关于 LearnKu




推荐文章: