
从一道前端面试题引发的原理性探究
0 / 0 / 创建于 6年前 /
 王老板的前端 的个人博客
王老板的前端 的个人博客
Vue 和 React 中的 key 到底有什么用?
key 是给每一个 vnode 的唯一 id,依靠 key,我们的 diff 操作可以更准确、更快速。 对于简单列表页渲染来说 diff 节点也更快,但会产生一些隐藏的副作用,比如可能不会产生过渡效果,或者在某些节点有绑定数据(表单)状态,会出现状态错位。)
diff 算法的过程中,先会进行新旧节点的首尾交叉对比,当无法匹配的时候会用新节点的 key 与旧节点进行比对,从而找到相应旧节点。
你以为这样回答,面试官就能放过你。Too young,To simple。下面是面试官的反问三连击:
为什么更准确?
因为带 key 就不是就地复用了,在 sameNode 函数 a.key === b.key 对比中可以避免就地复用的情况。所以会更加准确,如果不加 key,会导致之前节点的状态被保留下来,会产生一系列的 bug。
为什么更快速?
key 的唯一性可以被 Map 数据结构充分利用,相比于遍历查找的时间复杂度 O(n),Map 的时间复杂度仅仅为 O(1)。
为什么 Map 数据结构会更快?
Map / Set / WeakSet / WeakMap 就是使用隐藏的 Hash code 优化哈希表
ECMAScript 2015 引入了几个新的数据结构,例如 Map,Set,WeakSet和 WeakMap,所有这些结构都在后台使用哈希表。下面详细介绍了V8 v6.3+ 如何将 key 存储在哈希表中的最新进展。
哈希码 Hash code
散列函数用于将给定的 key 映射到哈希表中的特定位置。一个哈希码是给定的 key 运行此散列函数的运算结果。
hashCode = hashFunc(key)在 V8 中,哈希码只是一个随机数,与对象值无关。因此,我们无法重新计算它,这意味着我们必须存储它。
以前,对于那些把 JavaScript 对象作为 key 的情况,V8 将哈希码作为私有符号(private symbol)存储在对象上。V8 中的私有符号类似于Symbol,只是它不可枚举,也不会不会泄漏到用户空间 JavaScript 中。也就是说这个 symbol 只在 V8 引擎内部使用,用户的 JavaScript 代码访问不到。
function GetObjectHash(key) {
let hash = key[hashCodeSymbol];
if (IS_UNDEFINED(hash)) {
hash = (MathRandom() * 0x40000000) | 0;
if (hash === 0) hash = 1;
key[hashCodeSymbol] = hash;
}
return hash;
}之所以行之有效,是因为在将对象添加到哈希表之前,我们不必为哈希码字段保留内存。当对象被添加到哈希表时,才把新的私有符号存储在对象上。
与使用内联缓存(IC)系统进行的任何其他属性查找一样,V8 还可以优化哈希码符号查找,从而为哈希码提供非常快速的查找。当键具有相同的隐藏类时,这对于单态内联缓存查找非常有效。但是,大多数现实世界的代码都不遵循这种模式,并且键通常具有不同的隐藏类,导致散列码的复态内联缓存查找变慢。
私有符号方法的另一个问题是,它在存储哈希码时触发了密钥的隐藏类转换。这导致不仅对哈希代码查找也为上键和其他财产查找差的多形态代码去优化从优化代码。
JavaScript 对象支持存储
V8 的 JavaScript 对象(JSObject)使用 2 个 word(除了它的头部):一个 word 用于存储指向元素存储的指针,另一个 word 用于存储指向属性存储的指针。
- word (computer architecture)
元素存储用于像数组索引的属性,而属性存储用于其键为字符串或符号的属性。有关这些的更多信息,请参见 Camillo Bruni 的 V8 博客文章。
const x = {};
x[1] = 'bar'; // ← stored in elements
x['foo'] = 'bar'; // ← stored in properties隐藏哈希码 Hiding the hash code
存储哈希码最简单的方法是将 JavaScript 对象的大小扩展一个字,并将散列码直接存储在对象上。但是,对于那些没有添加到哈希表中的对象,这会浪费内存。相反,我们可以尝试将散列码存储在元素存储或属性存储中。
元素存储是一个包含其长度和所有元素的数组。在这里没有太多的工作要做,因为可以把哈希码存储在一个保留的槽中(比如第 0 个索引),不过,当我们不使用这个对象作为哈希表中的关键字时,仍然会浪费内存。
让我们看看属性存储。有两种数据结构用作属性存储:数组和字典。
与元素存储中使用的数组不同,元素存储不具有上限,而属性存储中使用的数组的上限为 1022 个值。由于性能原因,V8 在超过此限制时则转换为使用字典模式。(我略微简化了这一点 - V8 也可以在其他情况下使用字典,但是可以存储在数组中的值的数量有一个固定的上限。)
因此,属性存储有三种可能的状态:
- 空(没有属性)
- 数组(最多可以存储 1022 个值)
- 字典
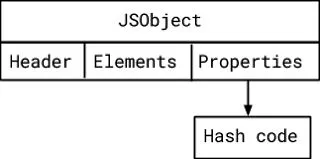
1、属性存储是空的
对于空的情况,我们可以直接在 JSObject 的偏移量上存储哈希码。
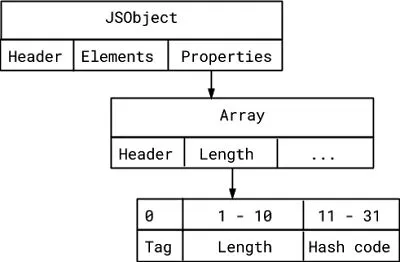
2、属性存储是一个数组
V8 表示小于 231 的整数(在 32 位系统上)更加高效,如 Smi。在一个 Smi 中,最低有效位是用来区别指针的 tag,而其余的 31 位保存实际的整数值。
通常,数组将它们的长度存储为 Smi。既然我们知道这个数组的最大容量只有 1022 个,我们只需要 10 个比特就可以存储这个长度。我们可以使用剩下的 21 位来存储哈希码!
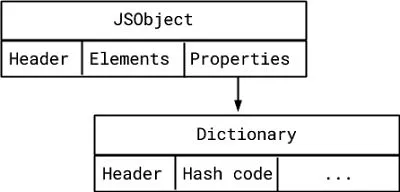
3、属性支持存储是一个字典
对于字典的情况,我们将字典大小增加1个字,以便将哈希码存储在字典起始位置的专用槽中。在这种情况下,我们可能会浪费掉一个字的存储空间,因为这个比例增长的大小并不像数组那么大。
通过这些更改,哈希码查找不再需要经过复杂的 JavaScript 属性查找机制。
性能改进
SixSpeed 对 Map 和 Set 的基准测试,这些变化导致了 5〜50% 的性能提升。

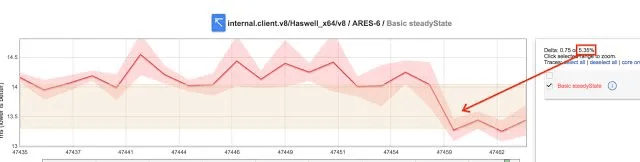
这一变化也导致 ARES6 中的基准测试提高了 5%。
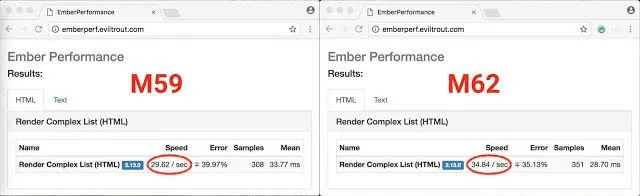
这也导致 Emberperf 基准测试套件中测试的 Ember.js 提高了 18%。
探究总结
掌握一门技术并合理使用它的最好办法就是深入理解这项技术背后的工作原理
参考资料
本作品采用《CC 协议》,转载必须注明作者和本文链接






 关于 LearnKu
关于 LearnKu




推荐文章: