
机器学习之清理数据
0 / 0 / 创建于 6年前
 Lois 的个人博客
Lois 的个人博客
苹果树结出的果子有品相上乘的, 也有虫蛀坏果.而高端便利店出售的苹果是 100% 完美的水果.从果园到水果店之间,专门有人花费大量时间将坏苹果剔除或给可以挽救的苹果涂上一层薄薄的蜡.作为一名机器学习工程师, 您将花费大量的时间挑出坏样本并加工可以挽救的样本.即使是非常少量的“坏苹果”也会破坏掉一个大规模数据集
缩放特征值
缩放是将浮点特征值从自然范围 ( 例如 100 到 900 ) 转换为标准范围 ( 例如 0 到 1 或 -1 到 +1 ).如果某个特征集只包含一个特征, 则缩放可以提供的实际好处微乎其微或根本没有.不过, 如果特征集包含多个特征, 则缩放特征可以带来以下优势:
1.帮助梯度下降法更快素地收敛
2.帮助避免 “NaN 陷阱”.在这种陷阱中, 模型中的一个数值变成 NaN ( 例如, 当某个值在训练期间超出浮点精确率限制时 ) , 并且规模中的所有其他数值最终也会因数学运算而变成 NaN.
3.帮助模型为每个特征确定合适的权重.如果没有进行特征缩放, 则模型会对范围较大的特征投入过多的精力.
您不需要对每个浮点特征进行完全相同的缩放.即使特征 A 的范围是 -1 到 +1 , 同时特征 B 的范围是 -3 到 +3, 也不会产生什么恶劣的影响.不过, 如果特征 B 的范围是从 5000 到 100000 , 您的模型会出现糟糕的响应.
处理极端离群值
下面的曲线图表示的是加利福尼亚州住房数据集中称为 roomsPerPerson 的特征. roomsPerPerson 值的计算方法是相应地区的房间总数除以相应地区的人口总数.该曲线图显示, 在加利福尼亚州的绝大部分地区, 人均房间数为 1 到 2 间.不过, 请看一下 X 轴.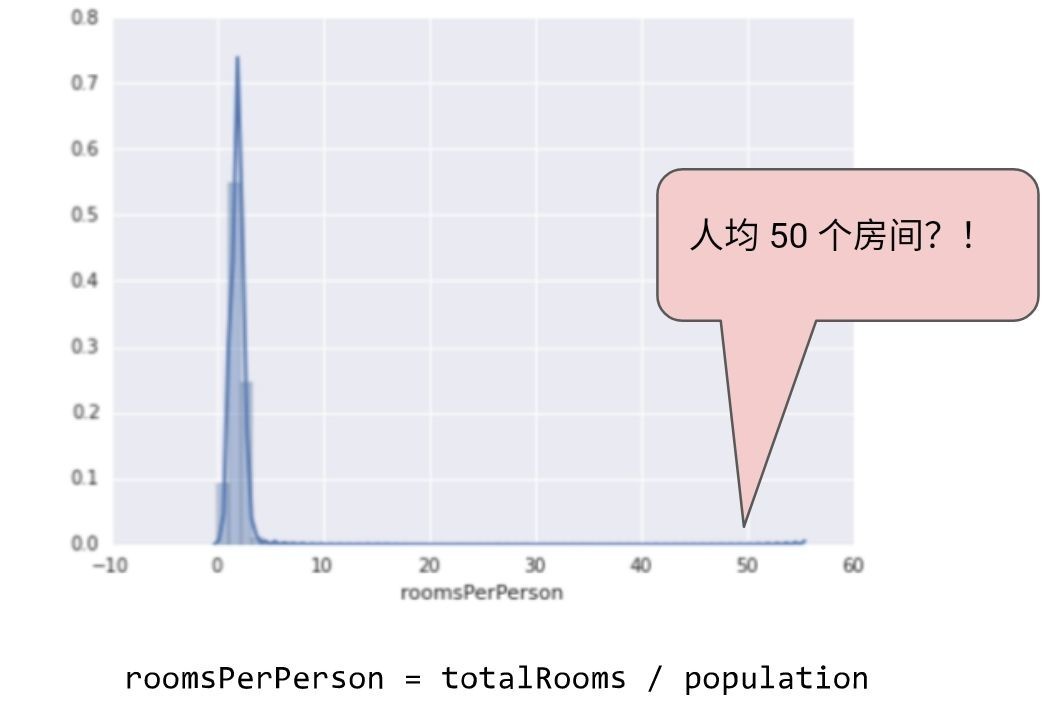
图 4.一个非常非常长的尾巴
如何最大限度降低这些极端离散群值的影响 ? 一种方法是对每个值取对数: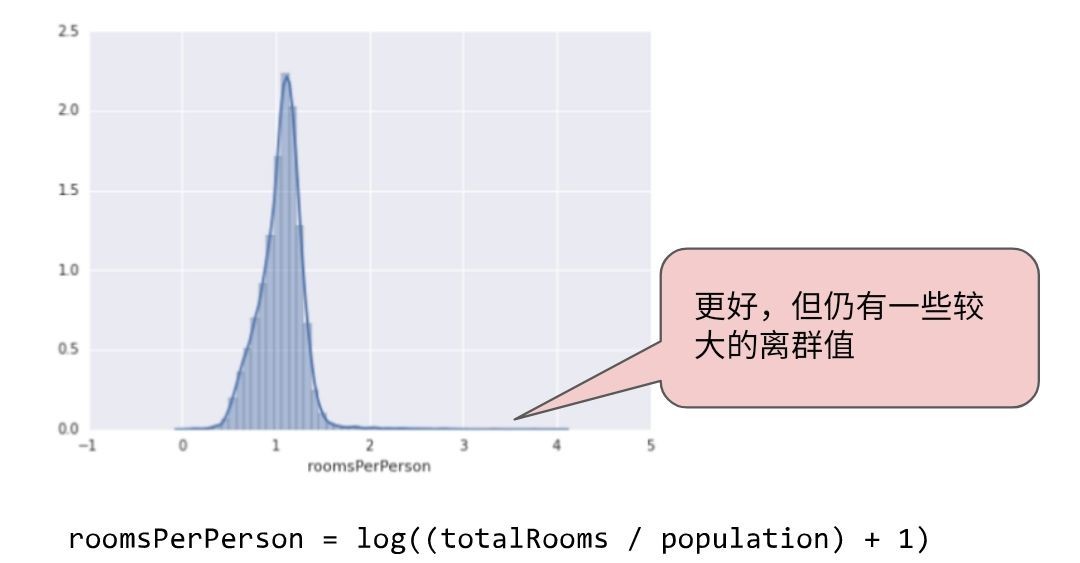
图 5.对数缩放仍然留有尾巴
对数缩放可以稍稍缓解这种影响, 但仍然存在离群值这个大尾巴.我们来采用另一种方法.如果我们只简单地将 roomsPerPerson 的最大值“限制”为某个任意值 ( 比如 4.0 ) , 会发生什么情况呢 ?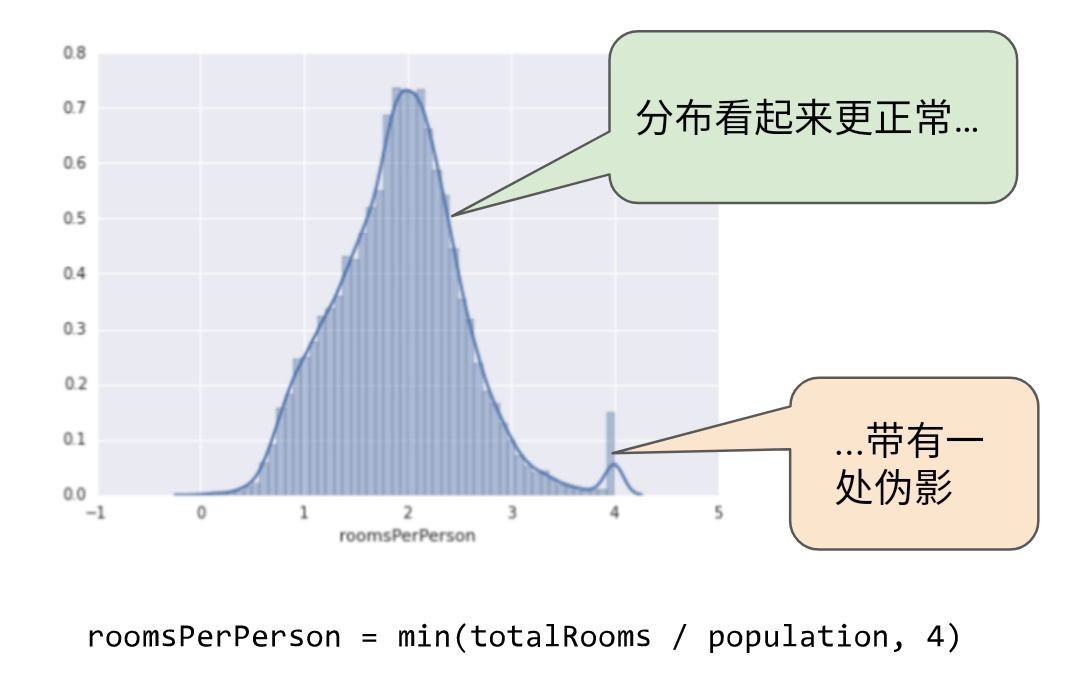
图 6.将特征值限制到 4.0
将特征值限制到 4.0 并不意味着我们会忽略所有大于 4.0 的值.而是说, 所有大于 4.0 的值都会变成 4.0 .这就解释了 4.0 处的那个有趣的小峰值, 但是缩放后的特征集现在依然比原始数据有用.
分箱
下面的曲线图显示了加利福尼亚州不同维度的房屋相对普及率.注意集群 -洛杉矶大致在维度 34 度处, 旧金山大约纬度 38 处.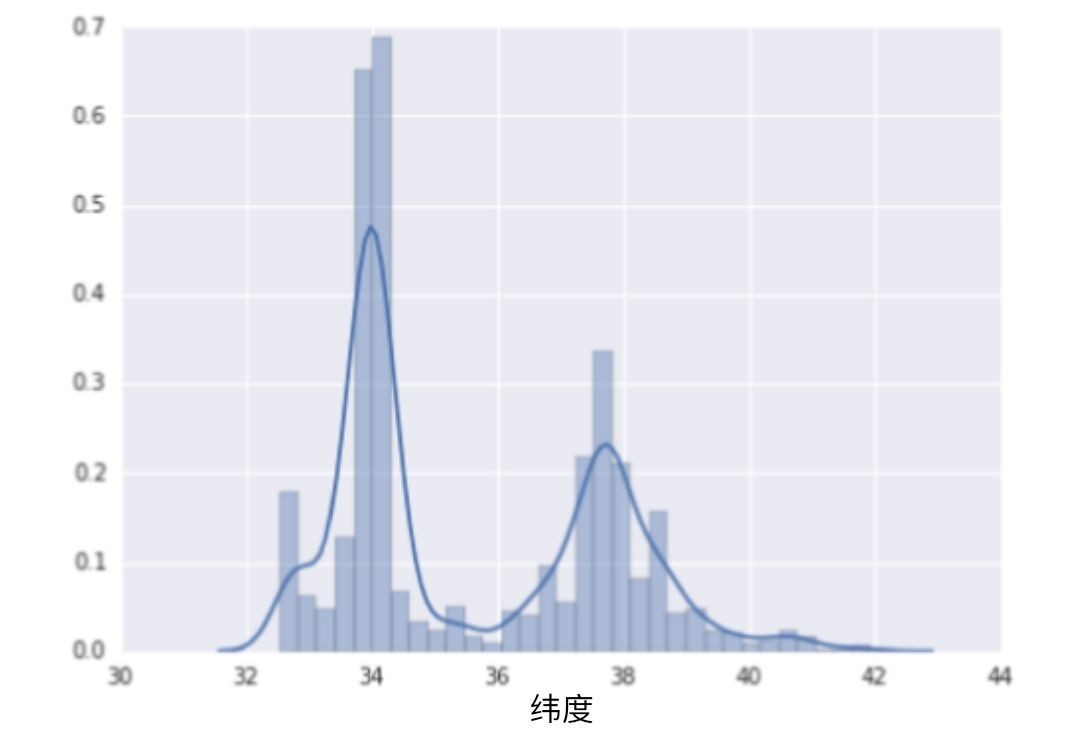
图 7. 每个维度的房屋数
在数据集中, latitude 是一个浮点值.不过, 在我们的模型中将 latitude 表示为浮点特征没有意义.只是因为维度和房屋价值之间不纯在线性关系,.例如, 纬度 35 处的房屋并不比纬度 34 处的房屋贵 35/34 ( 或更便宜 ) .但是, 纬度或许能很好地预测房屋价值.
为了将维度变为一项实用的预测指标, 我们对纬度 “分箱” , 如下图所示: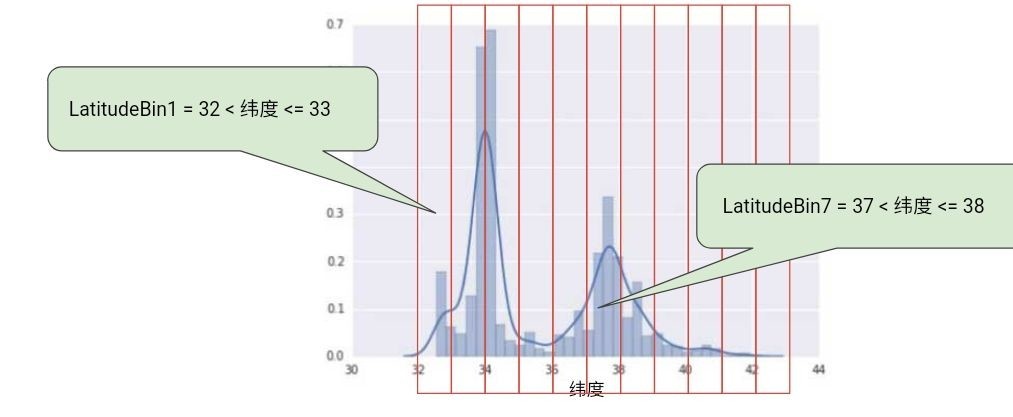
图 8.分箱值
我们现在拥有 11 个不同的布尔值特征 ( LatitudeBin1、LatitudeBin2、…、LatitudeBin11 ) , 而不是一个浮点特征.拥有 11 个不同的特征有点不太方便, 因此我们将它们统一成 11 个元素矢量.这样做之后, 我们可以将纬度 37.4 表示为:
分箱之后, 我们的模型可以为每个纬度学习完全不同的权重.
分箱边界
为了简单起见, 我们在纬度样本中使用整数作为分箱边界.如果我们需要更精细的解决方案, 我们可以每隔 1/10 个纬度拆分一次分箱边界.添加更多箱可让模型从纬度 37.4 处学习和纬度 37.5 处不一样的行为, 但前提是每 1/10 个纬度均有充足的样本可供学习.
另一种方法是按分位数分箱, 这种方法可以确保每个桶内的样本数量是相等的.按分位数分箱完全无需担心离群值.
清查
截至目前, 我们假定用于训练和测试的所有数据都是值得信赖的.在现实生活中, 数据集中的很多样本是不可靠的, 原因有以下一种或多种:
1.遗漏值.例如, 有人忘记为某个房屋的年龄输入值.
2.重复样本.例如, 服务器错误地将同一条记录上传了两次.
3.不良标签.例如, 有人错误地将一颗橡树的图片标记为枫树.
4.不良特征值.例如, 有人输入了多余的位数, 或者温度计被遗落在太阳底下.
一旦检测到存在这些问题, 您通常需要将相应的样本从数据集中移除, 从而 “修正” 不良样本.要检测遗漏值或重复样本, 您可以编写一个简单的程序. 检测不良特征值或标签可能比棘手.
除了检测各个不良样本之外, 您还必须检测集合中的不良数据.直方图是一种用于可视化集合中数据的很好机制.此外, 收集如下统计信息也会有所帮助:
1.最大值和最小值
2.均值和中间值
3.标准偏差
考虑生成离散特征的最常见值列表.例如, country :uk 的样本数是否符合您的预期 ?
language:jp 是否真的应该作为您数据集中的最常用语言 ?
了解数据
遵循以下规则:
1.记住您预期的数据状态.
2.确认数据是否满足这些预期 ( 或者您可以解释为何数据不满足预期 ).
3.仔细检查训练数据是否与其他来源 ( 例如信息中心 ) 的数据一致.
像处理任何任务关键型代码一样谨慎处理您的数据.良好的机器学习依赖于良好的数据.
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu




推荐文章: