
数据库操作
7 / 0 / 创建于 3年前 /
 HuDu 的个人博客
HuDu 的个人博客
数据库权限管理和备份
用户管理
用户表:mysql.user
本质:对这张表进行增删改查
-- 创建用户,不指定host默认是%
CREATE USER hudu IDENTIFIED BY '123456';
-- CREATE USER 'username'@'host' IDENTIFIED BY 'password'
-- 修改指定用户密码
-- 旧版本使用上面的
-- SET PASSWORD FOR 'hudu'@'%' = PASSWORD('111111');
ALTER USER 'hudu'@'%' IDENTIFIED BY '111111'
-- 重命名
RENAME USER hudu TO alex;
-- 用户授权 ALL PRIVILEGES 全部的权限,库.表
-- 除了给别人授权,其它权限都有
GRANT ALL PRIVILEGES ON *.* TO hudu;
-- 也可以加上
GRANT ALL PRIVILEGES ON *.* TO 'hudu'@'%' WITH GRANT OPTION;
-- 查看权限
SHOW GRANTS FOR hudu;
-- 回收权限 revoke 哪些权限,在哪个库撤销,给谁撤销
REVOKE ALL PRIVILEGES ON *.* FROM 'hudu'@'%';
-- 删除用户
DROP USER hudu;数据库备份
- 保证重要的数据不丢失
- 数据转移 A—–>B
MySQL备份的方式
- 直接拷贝物理文件
- 在可视化工具中手动导出
- 使用命令行导出 mysqldump命令行使用
可视化工具navicate备份数据库
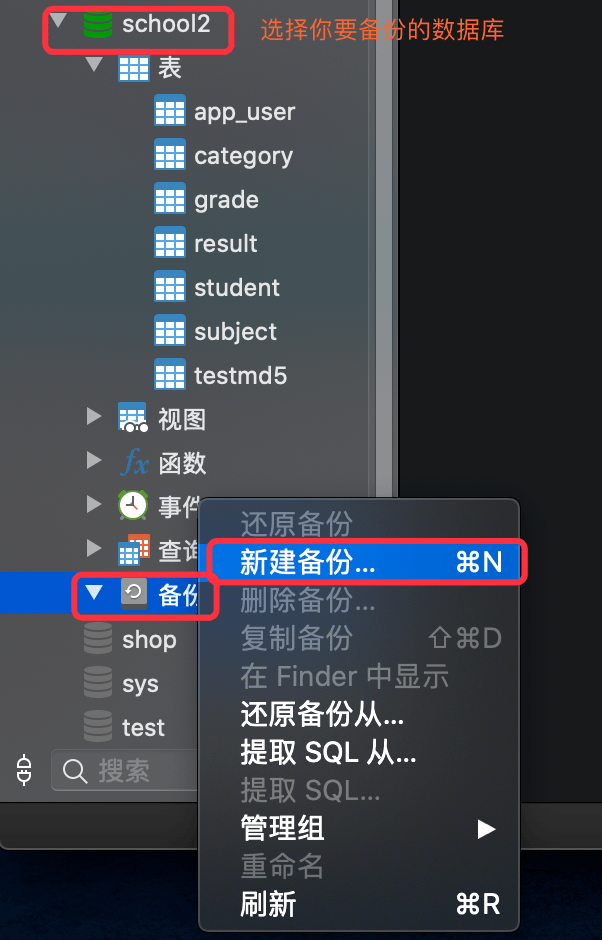
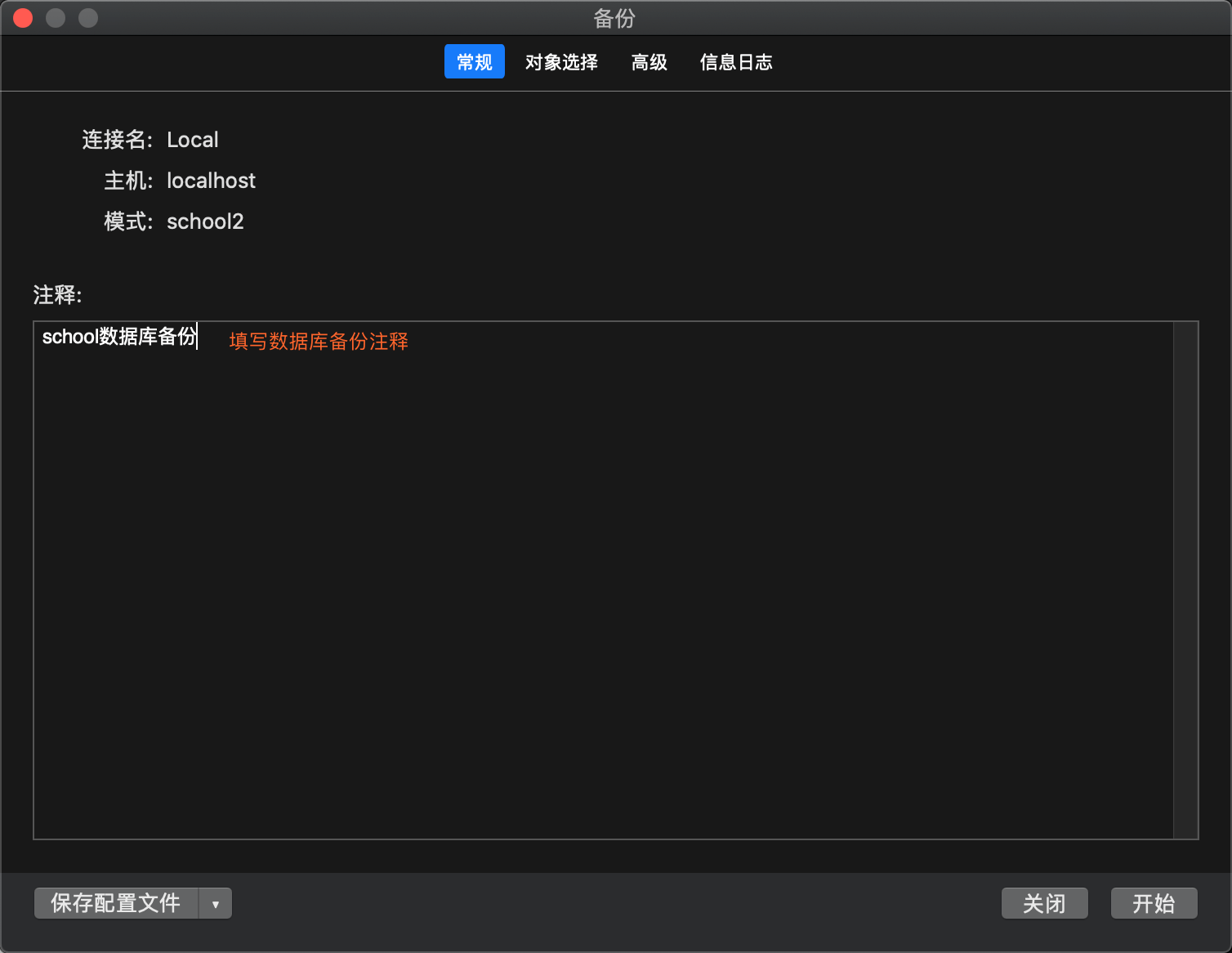
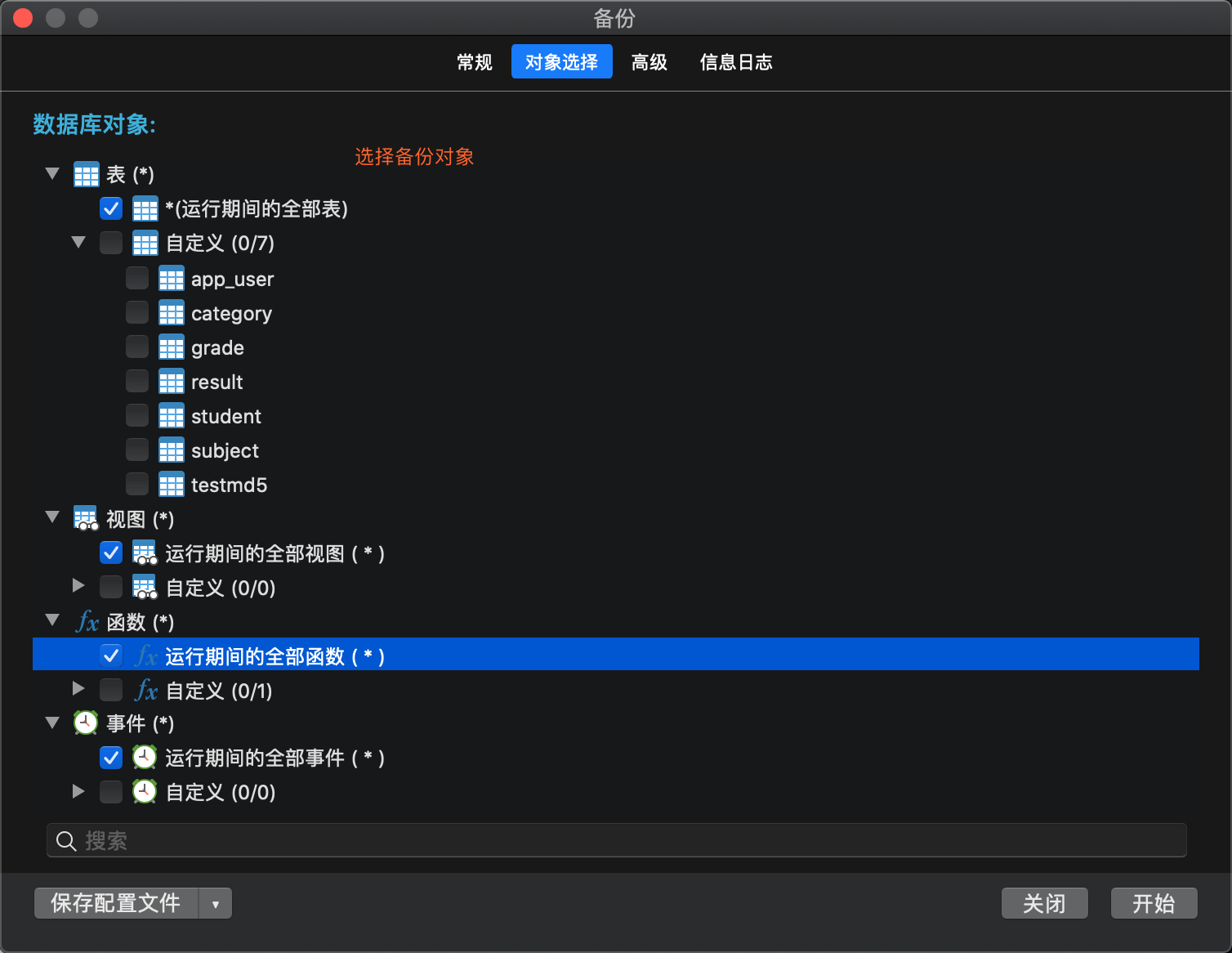

- 数据库定期备份


- 命令行导出
mysqldump -h主机名 -u用户名 -p密码 数据库 [表1 表2 表3...] > 物理磁盘位置/文件名
$ mysqldump -hlocalhost -uroot -p123456 school student > ~/File/mysql_backup/1.sql
mysqldump: [Warning] Using a password on the command line interface can be insecure.- 导入
# 先进入数据库
$ mysql -uroot -p123456-- 如果是备份的表
use school;
source ~/File/1.sql直接导入也是可以的
mysql -u用户名 -p密码 库名 < 备份文件规范数据库设计
当数据库比较复杂的时候,就要设计
糟糕的数据库设计:
- 数据冗余,浪费空间
- 数据插入和删除都会麻烦/异常【屏蔽物理外键】
- 程序的性能差
良好的数据库设计:
- 节省内存空间
- 保证数据库的完整性
- 方便开发系统
软件开发中,关于数据库的设计:
- 分析需求:分析业务和需要处理的数据库的需求
- 概要设计:设计关系图 E-R图
设计数据库的步骤:(个人博客)
- 收集信息,分析需求
- 用户表(用户登陆注销,用户个人信息,写博客,创建分类)
- 分类表(文章分类,谁创建的)
- 文章表(文章的信息)
- 评论表
- 友链表(友情信息)
- 自定义表(系统信息,某个关键的字,或者一些主字段)key:value
- 标识实体类(把需求落地到每个字段)
create database blog_test character set utf8 collate utf8_general_ci;
-- 用户数据库
CREATE TABLE `user`(
`id` int(11) NOT NULL auto_increment,
`username` VARCHAR(50) NOT NULL,
`password` VARCHAR(50) NOT NULL,
`phone` VARCHAR(11) DEFAULT NULL,
`sex` VARCHAR(2) NOT NULL,
`age` INT(3) NOT NULL,
`sign`VARCHAR(200),
PRIMARY KEY(`id`)
)ENGINE = INNODB DEFAULT CHARSET = utf8
-- 分类数据库
CREATE TABLE `catrgory`(
`id` int(10) NOT NULL,
`category_name` VARCHAR(30) NOT NULL,
`create_user_id` INT(10) NOT NULL,
PRIMARY KEY(id)
)ENGINE = INNODB DEFAULT CHARSET = utf8
-- 文章数据库
CREATE TABLE `blog`(
`id` int(10) NOT NULL,
`title` VARCHAR(100) NOT NULL,
`author_id` int(10),
`category_id` int(10),
`content` text NOT NULL,
`create_time` datetime,
`update_time` datetime,
`like` int(10),
PRIMARY KEY(`id`)
)ENGINE = INNODB DEFAULT CHARSET = utf8
-- 评论表
CREATE TABLE `comment`(
id int(10) NOT NULL,
blog_id int(10) NOT NULL,
user_id int(10) NOT NULL,
content VARCHAR(2000) NOT NULL,
create_time datetime NOT NULL,
user_id_parent int(10) NOT NULL COMMENT '回复的人的id',
PRIMARY KEY(`id`)
)ENGINE = INNODB DEFAULT CHARSET = utf8
-- 友链表
CREATE TABLE `links`(
`id` int(10) NOT NULL,
`links` VARCHAR(50) NOT NULL COMMENT '网站名称',
`href` VARCHAR(2000) NOT NULL COMMENT '网站链接',
sort int(10) NOT NULL COMMENT '排序',
PRIMARY KEY(`id`)
)ENGINE = INNODB DEFAULT CHARSET = utf8- 标识实体之间的关系
- 写博客:user –> blog
- 创建分类:user –> category
- 关注:user –> user
- 友链:links
- 评论:user-user-blog
三大范式
- 信息重复
- 更新异常
- 插入异常
- 无法显示信息
- 删除异常
- 丢失有效的信息
第一范式(1NF)
原子性:保证每一列不可再分
第二范式(2NF)
前提:满足第一范式
每张表只描述一件事情
第三范式(3NF)
前提:满足第一范式和第二范式
第三范式需要确保数据表中每一列数据都和主键直接相关,而不能间接相关。
规范数据库的设计
规范性和性能的问题
关联查询的表不得查过三张表
- 考虑商业化的需求和目标,成本,用户体验,数据库性能更为重要
- 在规范性能的问题的时候,需要适当考虑规范性
- 故意给某些字段增加一些冗余的字段。(从多表查询中变为单表查询)
- 故意增加一些计算列(大数据量降低为小数据量的查询:索引)
本作品采用《CC 协议》,转载必须注明作者和本文链接


 关于 LearnKu
关于 LearnKu



