
MySQL 高级优化
0 / 0 / 创建于 5年前 /
 HuDu 的个人博客
HuDu 的个人博客
索引(阿里规约)
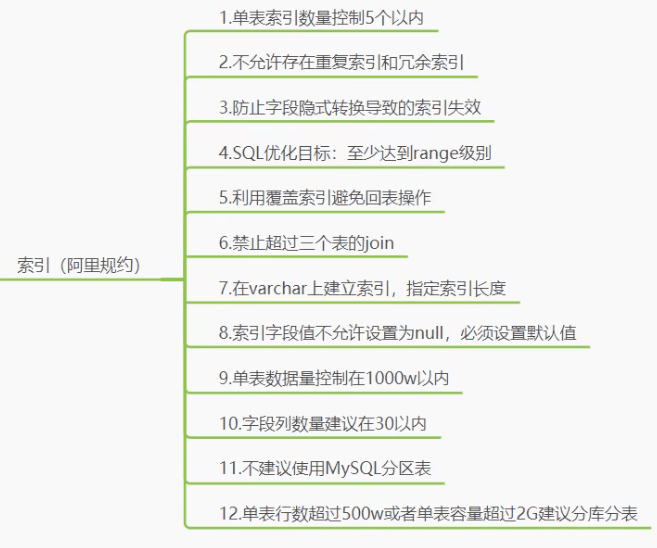
索引数据结构
B+ 树
Hash
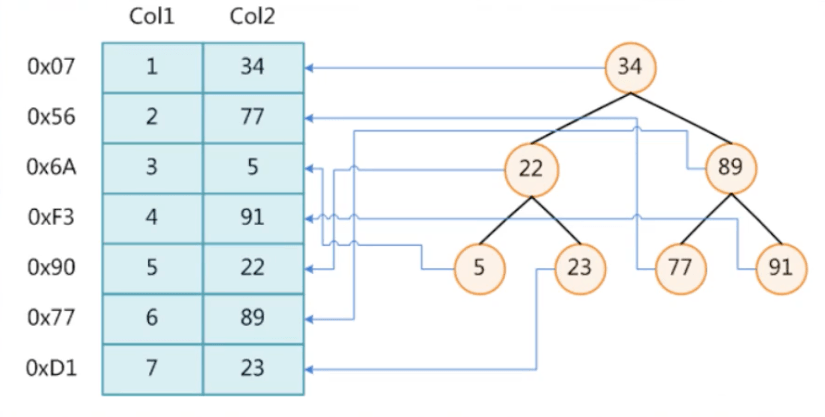
以Col2为例,当插入数据时,会对插入的数据进行一个哈希运算,把运算的哈希散列的值作为地址值。
但是hash没法很好的处理范围查找,但是B+ 树在底层时对所有的数据进行了维护,树的每层都是有序的。
B 树
- 叶子节点具有相同的深度,叶节点的指针为空
- 所有索引元素不重复
- 节点中的数据索引从左到右递增排列
B+ 树
多叉平衡树
- 非叶子节点不存储data,只存储索引(冗余),可以放更多的索引
- 叶子芥蒂娜包含所有索引字段
- 叶子节点用指针连接,提高区间访问的性能
查看mysql底层给B+ 树的一个节点设置的大小数为16KB
SHOW GLOBAL STATUS LIKE 'Innodb_page_size';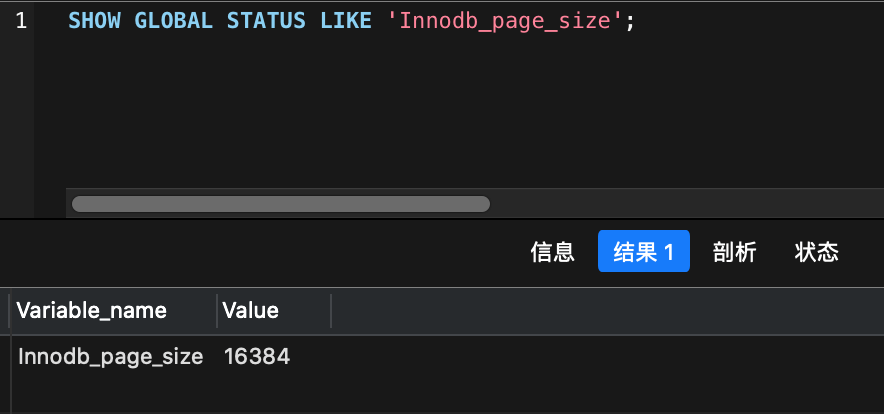
以下图为例,三层,索引拿bigint来计算一下,bigint是占8个字节,然后一个节点会有很多索引,一个索引会有一个指针,对应6个字节,所以一个索引全部大小为(8+6)就是14个字节,一个节点可以放1170个索引。
第二层同样可以放1170个索引,不过第三层每个索引对应不止有bigint,还有data数据,data数据可能是索引所在行的磁盘文件的地址,也可能是索引所在行的其它列的字段,放不了1170个,如果按一个索引1kb算,第三层每个节点放16个索引。
所以树的高度为3的B+树就 总共放1170 X 1170 X 16 = 21902400 个索引
并且MySQL索引底层的B+树的根节点是常驻内存(RAM)的。

MySQL的存储引擎是表级别的。
创建两张表,分别用不同的数据库引擎
CREATE TABLE `test_innodb_lock`(
`a` int(11) NOT NULL,
`b` varchar(255) DEFAULT NULL,
KEY `idx_a` (`a`),
KEY `idx_b` (`b`)
)ENGINE=INNODB DEFAULT charset=utf8
CREATE TABLE `test_myisam`(
`id` int(11) NOT NULL auto_increment,
`name` varchar(20) DEFAULT NULL,
PRIMARY KEY(`id`)
)ENGINE=myisam auto_increment=2 default charset=utf8可以看到实际上是在磁盘文件中mysql的data目录下具体的目录下存储。
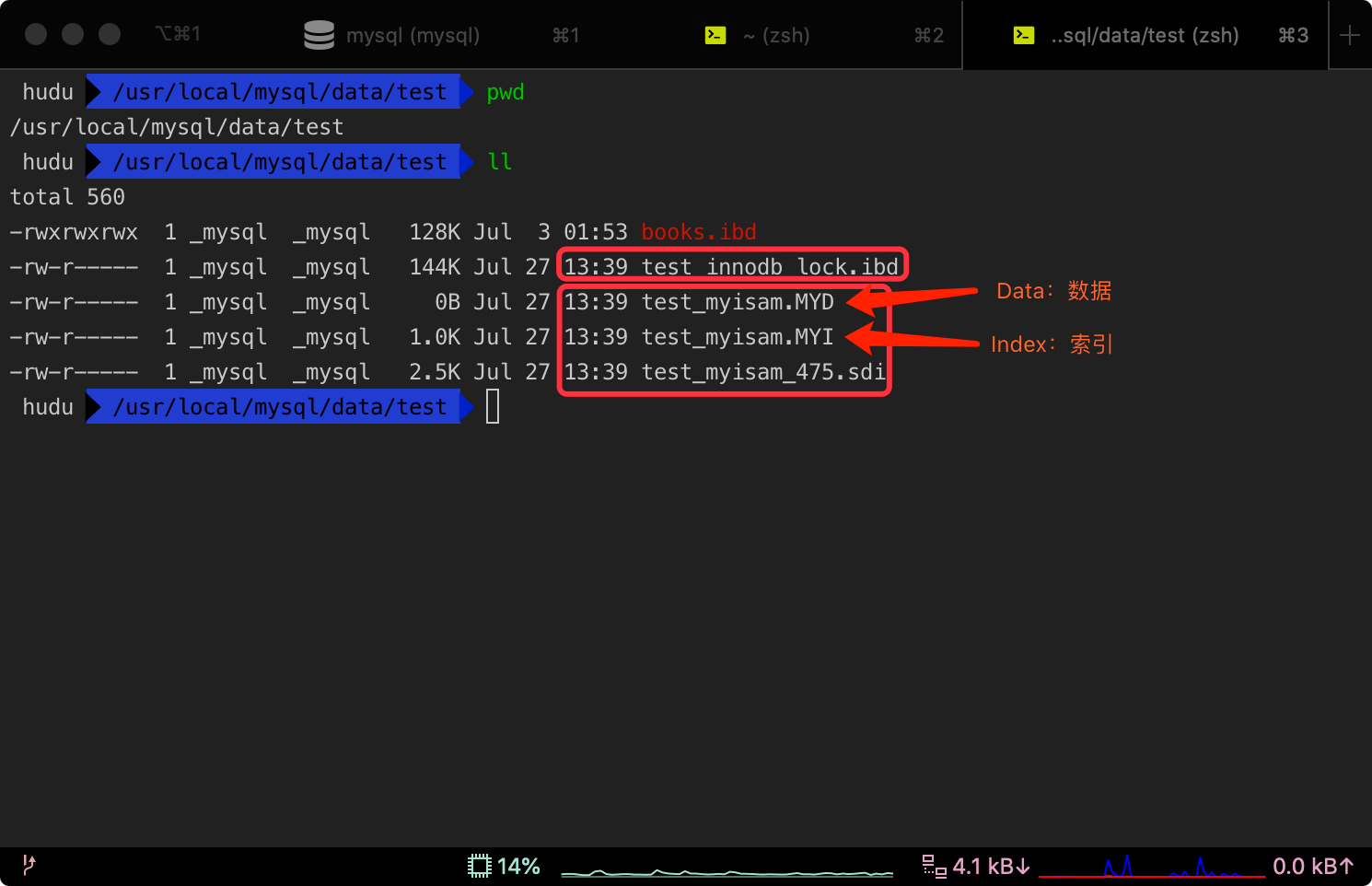
SDI是Serialized Dictionary Information的缩写,是MySQL8.0重新设计数据词典后引入的新产物。对于非InnoDB引擎,MySQL提供了另外一中可读的文件格式来描述表的元数据信息,在磁盘上以 $tbname.sdi的命名存储在数据库目录下。
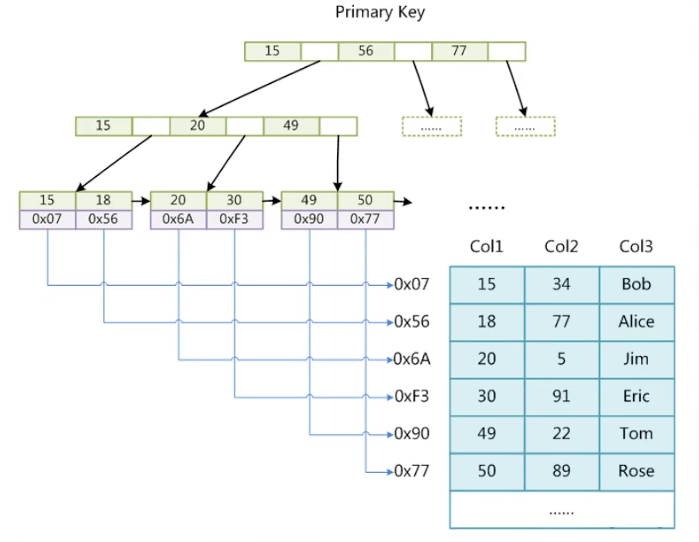
- MyISAM索引文件和数据文件是分离的(非聚集)
查找过程为,现判断是否有索引,有的话根据myi文件找到索引,然后根据myd找到所在行的文件地址
- InnoDB 索引实现(聚集)
- 表数据文件本身就是按B+ Tree组织的一个索引结构文件
- 聚集索引叶子节点包含了完整的数据记录
- 为什么InnoDB表必须有主键,并且推荐使用整型的自增主键?
- 为什么非空主键索引结构叶子节点存储的是主键值?(一致性和节省存储空间)
如果innodb表没有主键,会自动根据找一列数据,这一列数据会中的每一个数据都是唯一的,会把那一列数据拿出来对表进行维护。
如果连数据唯一的列都没有,innodb会在最后增加一列隐藏列,它帮你维护表。都是B+ 树。mysql资源是非常紧张的,每个表最好一定要建立主键,并且最好是整型自增,不推荐UUID这种字符串比较,因为效率会变慢。为什么要自增,不自增B+要自平衡,会导致执行insert语句等效率。
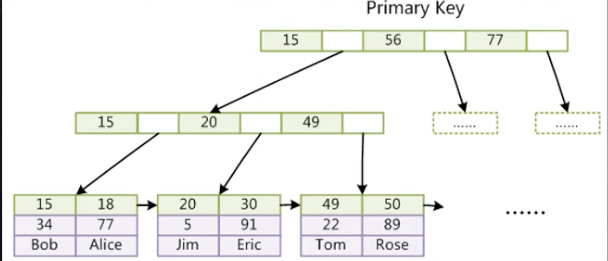
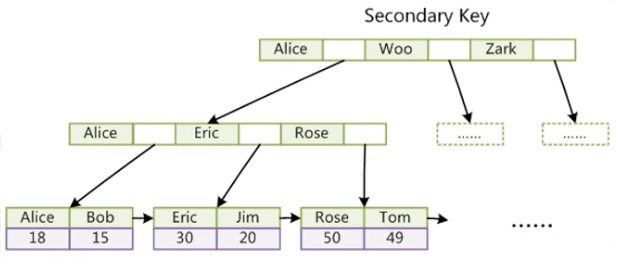
B+ 树索引的叶子节点两两之间,是有一个双向指针,放相邻节点的磁盘文件地址,可以在任意节点通过指针快速定位相邻节点的位置。
若要查找索引大于20的数据,先从根节点,快速定位到索引为20的节点,然后直接把索引20之后的所有的数据拿出来。
B 树叶子节点之间没有双向指针。B 树是每个节点都会有数据,B+ 树把所有的数据都放到叶子几点上,非叶子节点是冗余索引,叶子有完整的索引。
由于B 树上的每个节点都会放置数据,所以层放的节点会更少,存放相同量的数据,B树的层数会更加高。
联合索引
创建示例表
CREATE TABLE `employees` (
`id` int(11) not null auto_increment,
`name` varchar(24) not null default '' COMMENT '姓名',
`age` int(11) not null default '0' comment '年龄',
`position` varchar(20) not null default '' comment '职位',
`hire_time` timestamp not null default current_timestamp comment '入职时间',
primary key(`id`),
key `idx_name_age_position` (`name`,`age`,`position`) using btree
)ENGINE = innodb auto_increment=4 default charset=utf8 comment='员工记录表';
INSERT INTO employees(name,age,position,hire_time) VALUES('LiLei',22,'manager',NOW()),('HanMeimei',23,'dev',NOW()),('Lucy',23,'dev',NOW());
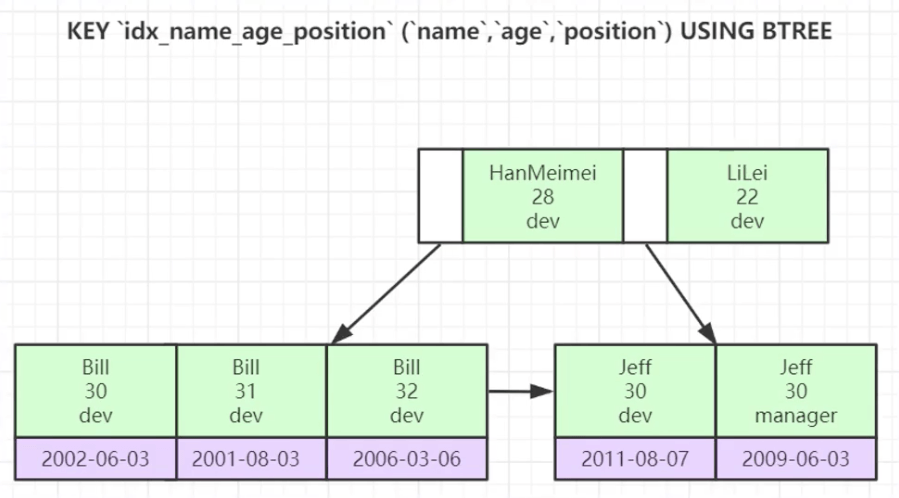
它是按照建立索引的顺序进行依次比较。
key `idx_name_age_position` (`name`,`age`,`position`) using btree;
EXPLAIN SELECT * FROM employees WHERE NAME = 'Bill' AND age = 31;
EXPLAIN SELECT * FROM employees WHERE age = 30 AND position = 'dev';
EXPLAIN SELECT * FROM employees WHERE position = 'manager';最左前缀原则,所以上面的语句只有第一条会执行。
原因:
在整张表之中查找,如果忽略索引的第一个字段,直接从后面字段查找,字段不是排好序的,无法通过索引查找,还需要全树比对查找。
本作品采用《CC 协议》,转载必须注明作者和本文链接






 关于 LearnKu
关于 LearnKu



