
Redis 底层详解
0 / 0 / 创建于 5年前 /
 CrazyZard 的个人博客
CrazyZard 的个人博客
redis 中所有出现的字符串 ,都是sds 实现的
typedef char *sds;
struct sdshdr {
// buf 已占用长度
int len;
// buf 剩余可用长度
int free;
// 实际保存字符串数据的地方
char buf[];
};类型 sds 是 char * 的别名(alias),而结构 sdshdr 则保存了 len 、 free 和 buf 三个属性
struct sdshdr {
len = 11;
free = 0;
buf = "hello world\0";
// buf 的实际长度为 len + 1
};内存预分配优化策略
def sdsMakeRoomFor(sdshdr, required_len):
# 预分配空间足够,无须再进行空间分配
if (sdshdr.free >= required_len):
return sdshdr
# 计算新字符串的总长度
newlen = sdshdr.len + required_len
# 如果新字符串的总长度小于 SDS_MAX_PREALLOC
# 那么为字符串分配 2 倍于所需长度的空间
# 否则就分配所需长度加上 SDS_MAX_PREALLOC 数量的空间
if newlen < SDS_MAX_PREALLOC:
newlen *= 2
else:
newlen += SDS_MAX_PREALLOC
# 分配内存
newsh = zrelloc(sdshdr, sizeof(struct sdshdr)+newlen+1)
# 更新 free 属性
newsh.free = newlen - sdshdr.len
# 返回
return newsh当长度小于 1MB 的字符串执行追加操作时, sdsMakeRoomFor 就为它们分配多于所需大小一倍的空间; 当字符串的长度大于 1MB , 那么 sdsMakeRoomFor 就为它们额外多分配 1MB 的空间。
惰性空间释放策略
sds在数据长度减少时,并不立刻释放多余空间。
双向链表
当对列表类型的键进行操作 —— 比如执行 RPUSH 、 LPOP 或 LLEN 等命令时, 程序在底层操作的可能就是双端链表。
双端链表的实现由 listNode 和 list 两个数据结构构成, 下图展示了由这两个结构组成的一个双端链表实例:

typedef struct listNode {
// 前驱节点
struct listNode *prev;
// 后继节点
struct listNode *next;
// 值
void *value;
} listNode;
typedef struct list {
// 表头指针
listNode *head;
// 表尾指针
listNode *tail;
// 节点数量
unsigned long len;
// 复制函数
void *(*dup)(void *ptr);
// 释放函数
void (*free)(void *ptr);
// 比对函数
int (*match)(void *ptr, void *key);
} list;因为双端链表占用的内存比压缩列表要多, 所以当创建新的列表键时, 列表会优先考虑使用压缩列表作为底层实现, 并且在有需要的时候, 才从压缩列表实现转换到双端链表实现。
压缩列表
因为其节约内存的性质,哈希键 、列表键 和 有序集合键 初始化的底层实现皆采用 ziplist
ziplist 结构

- zlbytes: 整个列表占用的内存字节数
- zltail: 尾部节点的偏移量
- zllen: 节点的个数,如果小于UINT16_MAX(65535),这个值就是节点的数量,如果等于65535,需要自己去遍历这个ziplist
- zlend: 标记ziplist的末端
entry 结构
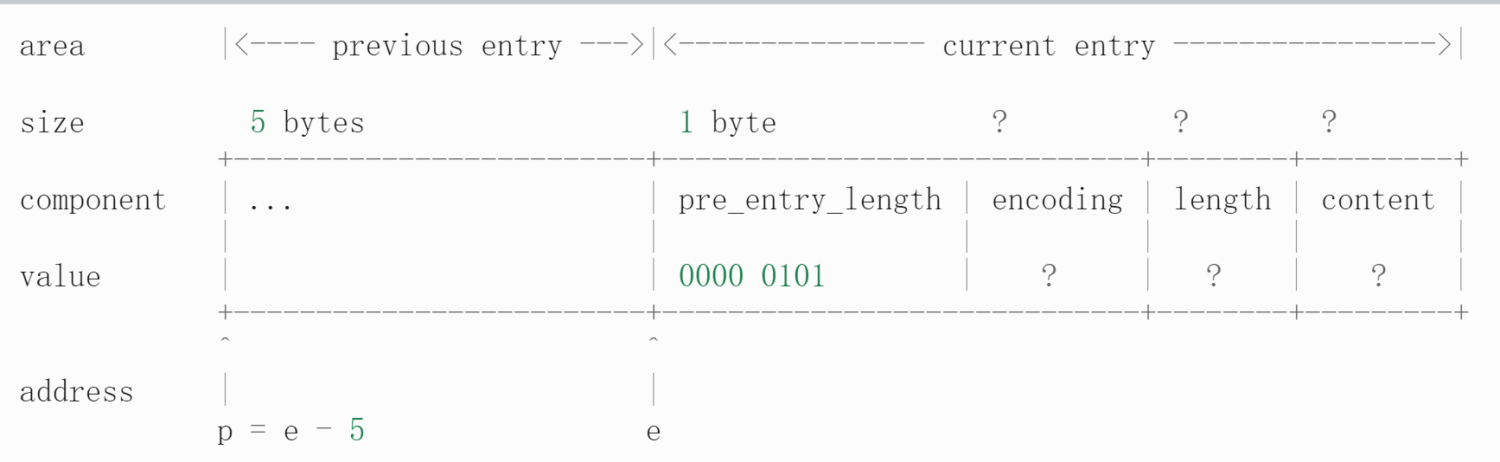
pre_entry_length :记录前一个
entry的长度 可能占用1字节或者是5字节前节点长度小于254字节,则使用一个字节保存
如果 大于等于254 字节,第一个字节值为254,后4个自己保存实际长度
encoding和length: 一起决定了content部分所保存的数据的类型(以及长度),encoding域的长度为两个 bit 有00、01、10和1100长度小于63字节的字符数组 占用1字节01长度小于等于16393字符数组 占用2字节10长度小于等于4294967295的字符数组 占用5字节11表示content 为整数content : 内容为二进制
添加和删除 ziplist 节点有可能会引起连锁更新,一般可以将添加和删除操作的复杂度视为 ( O(N) )
新增数据至末端
- 获取
ziplist末端所需的偏移量 - 根据新值,计算所需的空间、以及前一个节点的长度所需的空间,进行内存重分配
- 设置新节点属性 :
pre_entry_lengthencodinglength - 更新
ziplist各种属性 zlbyteslengthcontent
将节点添加至某节点前

会出现3中情况
- next 节点的
pre_entry_length刚好能表示 new 节点的的长度(都是1字节 或者是5字节) - next 节点的
pre_entry_length是1字节 但是 new 节点长度需要5字节 - next 节点的
pre_entry_length是5字节 但是 new 节点长度只需要1字节
如果出现第二种情况 ,redis 会对 ziplist 进行内存重分配,因为 next 空间长度变了,那么就得检查 next +1 的节点,看 pre_entry_length 能否编码 next 的新长度。 如果不能改变,则对 next + 1 的长度进行改变 。。。 现在就是无限套娃。直到下一个节点满足或者到 zlend 为止,由于连锁更新概率小,一般情况下默认看成 0(N) 的复杂度。
本作品采用《CC 协议》,转载必须注明作者和本文链接












 关于 LearnKu
关于 LearnKu




推荐文章: