
Redis 实用小技巧—— bitmap 应用之「位排序」
11 / 5 / 创建于 3年前 /
 快乐的皮拉夫 的个人博客
快乐的皮拉夫 的个人博客
简介
在之前的关于 bitmap 应用的系列文章中,我们分别介绍了「布隆过滤器」、「缓存穿透问题的处理」和「签到统计」几个比较典型的应用场景。接下来这篇文章,我们将以「位排序」作为收篇之作,结束我们 bitmap 系列的文章。
话不多说,准备发车~
位排序
概念
学习过算法的小伙伴对「排序」肯定不会陌生,所谓「排序」就是将一个序列按照规定的顺序重新排列的过程。比较典型的排序算法包括:冒泡排序,选择排序,插入排序,希尔排序,快速排序等。
我们今天要介绍的「位排序」,严格意义上讲,并不算是一种「排序算法」。在笔者看来,「位排序」的核心是借助 bit 位的存储优势,在「占位」的同时,遵循了 bit 位原有的存储顺序,最后排序的结果就是按照 bit 位的顺序,依次输出「占位」的 bit 位代表的数值。
场景
其实,说到位排序,在实际生产中的应用并不常见(至少我还没遇到过),倒是在一些算法讨论和一些面试题中出现的频率比较高。比如下面这道算法题(节选自《编程珠玑》):
输入: 一个最多包含 n 个正整数的文件,每个数都小于 n ,其中 n = 10^7。如果在输入文件中有任何整数重复出现就是致命错误。没有其他数据与该整数相关联。
输出: 按升序排列的输入整数的列表。
约束: 最多有(大约)1 MB 的内存空间可用,有充足的磁盘存储空间可用。运行时间最多几分钟,运行时间为 10 秒就不需要进一步优化了。
从这道题目中,我们可以提取到以下重要信息:
- 文件的数据集为一个长度为 n 的正整数集合,n 为 10^7 ,即 1000 万
- 集合中的正整数可能重复出现,需要找出重复出现的元素
- 对所有的正整数进行升序排序
- 分配内存控制在 1MB 左右,磁盘空间不限,运算时间控制在几分钟以内
这里我们分别使用「纯编程语言」和「 Redis bitmap」 两种方式来解决一下这个问题。
实现方式
纯编程语言实现
我们知道,在 32 位的 Linux 操作系统中,一个 int 整数占用 4 个字节,而在 64 位的 Linux 系统中,一个 int 整数占用 8 个字节,这里我们以 64 位 Linux 系统进行举例。
已知一个字节占用 8 个 bit 位,所以在 64 位的操作系统中,一个 int 整数占用 8 × 8 = 64 个 bit 位。
这里我们使用 PHP 的数组作为数据集的「容器」来进行存储。
假设我们使用普通的 int 类型的数组存储 1000 万的整数数据的话,需要分配多少内存呢(理论推理,和实际会有些出入)?
10000000 × 8 ÷ 1024 ÷ 1024 ≈ 76 Mb
这和我们的题目是不符的。
如果我们使用 bit 位来表示呢?
10000000 ÷ 8 ÷ 1024 ÷ 1024 ≈ 1.19 Mb
这和我们题目的要求基本是相符的。
为什么差距会这么大呢?其实我们在用 bit 位存储的时候,我们一个整数实际最大可以表示 64 个整数,所以比普通的存储方式小了 64 倍。举个例子:
在普通的整数存储方式中,十进制 7 表示的就是整数 7。而到了 bit 位存储中,我们需要先将十进制的 7 转换成二进制的表示方式 111,这实际上表示了三个十进制数,即通过每一位偏移量转换成十进制以后所对应的值:分别是 2^0 = 1,2^1 = 2 和 2^2 = 4。
通过数组的方式存储 bit 位结构可参考下图:
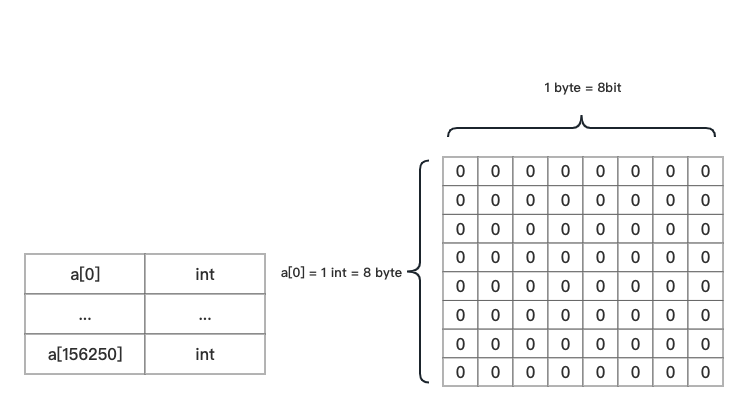
注意: 这里数组的最大下标是 156250。其运算方式就是通过我们上述的推导过程算出来的:10000000 ÷ 64 = 156250。下标看似很大,实际分配的内存仅为 1.19 MB。
相信看到这里,你已经大概知道实现的思路了。接下来就让我们看看具体的实现代码。
这里我们使用最复杂的情况进行示例,即正好 1000万 的数据,且都是倒序排序,文件格式如下:
sort-by-bit.txt
10000000
9999999
9999998
9999997
...实现代码如下:
...
//========== 记录排序前运行数据 ==========
$m1 = memory_get_usage(); //运行内存
$t1 = (int)(bcmul(microtime(true),1000)); //运行时间
// 1. 初始化数组
// PS: 申请长度为 156251 的整数数组,并将所有元素初始化为 0。申请为 156251 而不是 156250 是为了防止数组下标溢出
$bitmap = array_fill(0, 156251, 0);
//========== 计算整数占用 bit 位数 ==========
$intBitSize = PHP_INT_SIZE * 8;
// 2. 从源文件读取数据
$originFile = storage_path('tmp/sort-with-bit.txt');
//========== 使用SplFileObject类处理文件 ==========
$splFileObj = new \SplFileObject($originFile, 'r+');
while (!$splFileObj->eof()) {
//========== 读取行并移动文件指针 ==========
$number = trim($splFileObj->current());
$splFileObj->next();
//========== 文件行格式判断 ==========
if (!$number) {
continue;
}
// 3. 计算偏移量
$byteOffset = intval($number / $intBitSize); //字节偏移量
$bitOffset = $number % $intBitSize; //bit位偏移量
$offset = 1 << $bitOffset; //偏移量的十进制表示
// 4. 重复数据处理
if($bitmap[$byteOffset] == ($bitmap[$byteOffset] | $offset)){
echo '存在重复数据:' . $number . PHP_EOL;
}
// 5. bit位存储
$bitmap[$byteOffset] = $bitmap[$byteOffset] | $offset;
}
//========== 记录排序后运行数据 ==========
$m2 = memory_get_usage(); //运行内存
$t2 = (int)(bcmul(microtime(true),1000)); //运行时间
echo '排序消耗内存:' . ($m2 - $m1) . ' 字节' . PHP_EOL;
echo '排序消耗时间:' . ($t2 - $t1) . ' 毫秒' . PHP_EOL;
//========== 为了方便展示,加一个暂停 ==========
sleep(3);
// 6. 排序数组输出
echo '输出排序后数组:' . PHP_EOL;
foreach ($bitmap as $k => $v) {
for ($i = 0; $i < $intBitSize; $i++) {
$tmp = 1 << $i;
$exist = $tmp & $bitmap[$k];
if ($exist) {
echo $k * $intBitSize + $i . PHP_EOL;
// PS: 或者输出到目标文件
}
}
}
echo '排序完毕~' . PHP_EOL;
...运行以上代码后,结果如下:
排序消耗内存:8410056 字节
排序消耗时间:3571 毫秒
输出排序后数组:
1
2
3
4
...通过测试,我们发现 1000 万的数据我们通过位排序,用了大约 3.6 秒,而占用的内存在 8MB 左右。
这里你可能会有疑问:为什么理论分析的时候,内存占用在 1MB 左右,而实际数组分配的内存在 8MB 左右呢?
这是因为 PHP 的数组结构和 C 语言的数组结构不同,PHP 需要分配额外的内存空间来记录数组结构的相关信息,PHP 数组存储和 C 语言中数组存储差值在 10 倍左右(这里如果我们使用 C 语言实现的话,和实际情况会更接近)。
也就是说,在 C 语言中,10 MB 内存空间的数组,如果用 PHP 存储的话,可能需要 100 MB 左右的内存空间。造成这种差别的具体原因这里我们就不单独分析了,后续有机会的话我们再单独展开探讨。
通过「位排序」的方式我们基本解决了开篇提到的问题。这说明在这种「特殊」的场景下,「位排序」为我们提供了一种排序的思路。
接下来我们再来看看通过 Redis Bitmap 如何实现。
Redis Bitmap 实现
通过 Redis Bitmap 实现比较简单,这里我们先来测试下使用 Redis Bitmap 存储 1000 万数据的话需要分配多少内存,测试代码如下:
...
$key = 'BIT_SORT';
$m1 = Arr::get(Redis::info('memory'), 'Memory.used_memory', 0);
Redis::setBit($key, 10000000, 1);
$m2 = Arr::get(Redis::info('memory'), 'Memory.used_memory', 0);
dd(($m2 - $m1) / 1024 /1024);
...通过测试,我们发现 1000 万的 bitmap 占用的空间大概为:1.25 MB,和我们上面预估的数据差距不大,接下来我们就来看看如何实现具体的排序功能。
评估 Redis Bitmap 占用空间仅需要看设置了最大偏移量以后占用的空间大小即可。
代码示例如下:
...
$redisKey = 'BIT_SORT';
//========== 记录排序前运行数据 ==========
$t1 = (int)(bcmul(microtime(true),1000)); //运行时间
// 1. 从源文件读取数据
$originFile = storage_path('tmp/sort-with-bit.txt');
//========== 使用SplFileObject类处理文件 ==========
$splFileObj = new \SplFileObject($originFile, 'r+');
while (!$splFileObj->eof()) {
//========== 读取行并移动文件指针 ==========
$number = trim($splFileObj->current());
$splFileObj->next();
//========== 文件行格式判断 ==========
if (!$number) {
continue;
}
// 2. bit位存储及重复性判断
if(Redis::setBit($redisKey, $number, 1) == 1){
echo '存在重复数据:' . $number . PHP_EOL;
}
}
//========== 记录排序后运行数据 ==========
$t2 = (int)(bcmul(microtime(true),1000)); //运行时间
echo '排序消耗内存:' . ($m2 - $m1) . ' 字节' . PHP_EOL;
echo '排序消耗时间:' . ($t2 - $t1) . ' 毫秒' . PHP_EOL;
// 3. 排序数组输出
echo '输出排序后数组:' . PHP_EOL;
for ($i = 1; $i <= 10000000; $i++) {
if(Redis::getBit($redisKey, $i) == 1){
echo $i . PHP_EOL;
// PS: 或者输出到目标文件
}
}
echo '排序完毕~' . PHP_EOL;
...这里我们没有记录内存消耗,实际上,这里我们借助 Redis 存储数据,内存消耗主要在 Redis 一侧,我们已经通过实际测试内存消耗没有什么问题。
但是,通过记录排序时间会发现,计算时间会很长,已经超出了我们题目中的限制。这是因为,这里的时间消耗主要在 Redis 的操作命令,每一条 Redis 操作命令都涉及到网络开销。我们在本地 Redis 测试发现,通过 Laravel 程序执行一条 SETBIT 命令,大概在 2 毫秒左右,由此可以推算,执行完 1000 万条数据的写入操作,大概在 20000 秒左右,也就是 5.6 个小时左右(当然,这只是基于笔者的本地服务器测试得出的结论)。
如果需要输出排序后的数组,则需要通过 GETBIT 命令依次获取 bit 位的占用情况,来输出排序后的结果。输出结果同样会耗用大量的时间。
那有没有更快的操作方式呢?更快地写入 and 更快地读取?
pipeline。
之前的系列文章中提到过,这里我们可以借助 pipeline 或者 Lua 脚本来批量执行命令,从而减少网络通信的次数,缩小处理时间。但是并非批量的粒度越大,执行的时间就越少,因为当网络请求包体越来越大的时候,也会出现阻塞的情况。
那么使用 pipeline 批量的粒度多大算是合适呢?
这里我们来做一个测试,通过在本地 Linux 服务器上,执行以下代码,来测试不同批量粒度下 pipeline 的执行时长。测试代码如下:
...
$container = [1, 2, 3];
$t1 = (int)(bcmul(microtime(true),1000)); //运行时间
$result =Redis::pipeline(function ($redis) use ($key, $container) {
foreach ($container as $item) {
$redis->setBit($key, $item, 1);
}
});
$t2 = (int)(bcmul(microtime(true),1000)); //运行时间
dd($t2 - $t1);
...这里我们通过调整 $container 数组的长度,来统计 pipeline 执行所需的时间,统计结果如下:
| 元素数量 | 执行时长(毫秒) |
|---|---|
| 10 | 26 |
| 100 | 30 |
| 1000 | 44 |
| 10000 | 121 |
| 100000 | 849 |
| 1000000 | 5666 |
| 10000000 | 内存溢出 |
通过以上的测试,我们发现 pipeline 批量处理的粒度在 10000 的时候,响应时长在 120 毫秒左右,还是可以接受的。通过换算,处理 1000 万的数据,响应时长大概在:10000000 ÷ 10000 × 121 ÷ 1000 = 121 秒。
尽管当元素数量 100000 时,响应时长在 850 毫秒左右,但是这个时长对于单次请求来说,已经比较「危险」了。
让我们通过实际代码来测试下,调整后的代码结构如下:
...
$redisKey = 'BIT_SORT';
//========== 记录排序前运行数据 ==========
$t1 = (int)(bcmul(microtime(true),1000)); //运行时间
// 1. 从源文件读取数据
$originFile = storage_path('tmp/sort-with-bit.txt');
//========== 使用SplFileObject类处理文件 ==========
$splFileObj = new \SplFileObject($originFile, 'r+');
$container = [];
while (!$splFileObj->eof()) {
//========== 读取行并移动文件指针 ==========
$number = trim($splFileObj->current());
$splFileObj->next();
//========== 文件行格式判断 ==========
if (!$number) {
continue;
}
//========== 容器存储逻辑 ==========
$container[] = $number;
if(count($container) < 100000 && !$splFileObj->eof()){
continue;
}
// 2. bit 位存储
$result =Redis::pipeline(function ($redis) use ($redisKey, $container) {
foreach ($container as $item) {
$redis->setBit($redisKey, $item, 1);
}
});
// 3. 重复性判断
foreach ($result as $key => $value) {
if($value == 1){
echo '存在重复数据:' . $container[$key] . PHP_EOL;
}
}
$container = [];
}
//========== 记录排序后运行数据 ==========
$t2 = (int)(bcmul(microtime(true),1000)); //运行时间
echo '排序消耗时间:' . ($t2 - $t1) . ' 毫秒' . PHP_EOL;
//========== 为了方便展示,加一个暂停 ==========
sleep(3);
// 4. 排序数组输出
echo '输出排序后数组:' . PHP_EOL;
$container = [];
for ($i = 1; $i <= 10000000; $i++) {
//========== 容器存储逻辑 ==========
$container[] = $i;
if(count($container) < 10000 && $i != 10000000){
continue;
}
$result =Redis::pipeline(function ($redis) use ($redisKey, $container) {
foreach ($container as $item) {
$redis->getBit($redisKey, $item);
}
});
foreach ($result as $key => $value) {
if($value == 1){
echo $container[$key] . PHP_EOL;
// PS: 或者输出到目标文件
}
}
$container = [];
}
...通过测试发现,1000 万的数据全部执行完一遍 SETBIT 操作,使用 pipeline 的粒度控制在 10000 时,总共耗时 3 分钟左右,这已经基本满足我们的条件了。
总结
本篇文章,我们讨论了一个实际生产中并不常见,但是面试题或者算法题中经常会提及到的一个问题,并且使用两种方式进行了实现。用一句话来总结就是:当数据集非常大,已经超出了正常存储方式的存储范围时,如果重复元素被视为异常数据,此时可以考虑通过「位排序」的方式来实现。
至此,我们「bitmap 应用」的系列文章已经告一段落,感谢大家的持续关注~
本作品采用《CC 协议》,转载必须注明作者和本文链接




















 关于 LearnKu
关于 LearnKu




推荐文章: