
Redis 实用小技巧——浅谈 Redis 使用规范
40 / 8 / 创建于 2年前 /
 快乐的皮拉夫 的个人博客
快乐的皮拉夫 的个人博客
简介
我们都知道,Redis 作为一款基于内存的「非关系型数据库」,无论是作为缓存还是其他高并发的场景的数据库存储,都有着得天独厚的优势。而 Redis 的优势,主要体现在以下几个方面:
- 极快的读写速度
- 丰富的数据类型
- 操作的原子性
- 丰富的特性
正所谓「好钢用在刀刃上」。要想充分发挥 Redis 的优势,各种规范问题也就显得尤为重要。本篇文章,我们就来聊一聊关于 Redis 使用规范中需要注意的一些问题。
话不多说,准备发车~
规范说明
一、键命名规范
- 大小写保持一致(建议使用全部大写的格式,非强制要求)
- 键名称的长度保持适中(太长占用过多内存资源,太短可读性太差)
- 合理使用命名空间,每一级之间使用
:进行分隔,如果是复合单词,单词之间使用_进行分隔。一般按照项目标识:模型标识:字段标识:标识ID进行命名。比如在 CMS 系统中,我们需要记录用户的登录 token ,我们就可以设计如下的键:CMS:USER:LOGIN_TOKEN:123 - 避免在键中使用敏感信息,以免造成信息泄露
二、合理设置过期时间
在使用 Redis 的过程中,我们一般都会给键设置过期时间。在设置过期时间时,需要注意以下规范问题:
- 批量设置过期时间的时候最好加一个随机值,避免「缓存雪崩」的问题
- 对于需要长期保留的数据(如配置信息),可以考虑直接存储在 Redis 内存中,而不设置过期时间
- 对于一般的缓存信息,建议设置一个相对较长的过期时间。当修改数据时,同时刷新缓存即可
三、选择合适的键类型
在之前的系列文章《Redis 实用小技巧——一文教你如何选择合适的 Key 类型》一文中详细介绍过如何选择合适的数据类型,这里仅作简单总结:
- 简单的字符串存储,优先考虑使用
String - 如果是普通的对象属性存储,优先考虑使用
Hash - 需要「先进先出」的任务场景,优先考虑使用
List - 需要存储一组元素,且元素具有唯一性,优先考虑使用
Set - 需要存储一组元素,且元素具有唯一性和「分值」,而且需要对元素进行排序比较,优先考虑使用
Zset
四、线上禁用或慎用高危命令
对于业务体量比较大的公司,线上 Redis 无论是数据量还是请求量都是很大的,一旦操作不当,将造成线程阻塞甚至服务不可用的情况。所以一些线上的 Redis 命令是需要禁用或者是谨慎使用的。
如果使用的是本地 Redis 服务,需要在配置文件中添加
rename-command keys ""来禁用命令。如果使用的是 Redis 云服务器的话,需要在参数设置的禁用命令列表中添加需要禁用的命令。
KEYS 命令【禁用】
危险指数:
禁用原因:KEYS命令执行的时候是需要进行全库扫描的,如果数据库中 key 很多的话,会造成命令线程阻塞,从而导致 Redis 不可用。如果需要遍历全库的 key 的话,使用 SCAN 命令替代。
FLUSHDB、FLUSHALL 命令【禁用】
危险指数:
禁用原因:FLUSHDB 会清除指定数据库的所有 key,而 FLUSHALL 会清除所有数据库的 key。这两个命令本身就属于高危操作,如果开启的是 RDB 持久化方案的话,数据就无法恢复了。所以即使有类似需求,也需要特殊权限的运维人员进行操作。另外清空数据库的操作耗时比较长,会造成线程阻塞。
SHUTDOWN 命令【禁用】
危险指数:
禁用原因:SHUTDOWN 命令可以直接停止 Redis 服务。高危命令自然不必多说。
CONFIG 命令【禁用】
危险指数:
禁用原因: CONFIG 命令属于运维命令,可以直接修改 Redis 配置信息,因此,需要指定特殊权限的运维人员操作此命令。
DEBUG 命令【禁用】
危险指数:
禁用原因:DEBUG 命令是一个内部命令。 旨在用于开发和测试 Redis,线上环境可能会造成灾难性的后果。比如下面命令,可以直接让 Redis 服务崩溃:
DEBUG SEGFAULTEVAL 命令【慎用】
危险指数:
慎用原因:EVAL 命令用于执行 lua 脚本,在一些处理程序中直接使用 EVAL 命令执行 lua 脚本效率会更好。但是此命令需要慎重使用,如果在 lua 脚本里面构造大量循环,会导致 Redis 主进程卡死。
注意:
SCRIPT LOAD+EVALSHA命令组合也会实现EVAL的效果。
HGETALL 命令【慎用】
危险指数:
慎用原因: HGETALL 的时间复杂度为 O(N), N 为哈希表的大小。也就是说,字段越多,耗时越长。类似的命令还有:LRANGE key 0 -1、SMEMBERS、ZRANGE key 0 -1等,这些集合类获取元素的命令时间复杂度都是 O(N)。所以在使用前需要先使用元素个数查询命令(如 HLEN、LLEN、SCARD、ZCARD)查看下集合元素的数量,然后再决定能否使用。
五、避免 bigkey
因为 Redis 命令是单线程执行的,所以 bigkey 的读写操作都会造成线程阻塞。因此,在日常开发中,我们需要注意,尽量从源头上避免 bigkey 的产生。
bigkey 的影响主要有以下几个方面:
- 阻塞请求。Redis 单线程执行命令时,对
bigkey的读写操作会造成线程阻塞的情况。 - 阻塞网络。读取
bigkey操作会占用较大的网络带宽,会影响到同节点下其他实例正常的网络通信。 - 内存占用变大。如果使用了集群,还会造成集群负载分布不均衡的情况。
- 影响主从同步,主从切换。
注意:关于如何排查数据库中的
bigkey,感兴趣的小伙伴可以参考 《Redis 实用小技巧—— key 分布情况分析》 一文。
为了避免 bigkey 情况的产生,我们在日常开发中需要注意以下几点:
- 针对
String类型的 key,理论上值的大小不得超过 512 MB。尽管 Redis 文档中并没有明确规定bigkey边界的具体大小,但是我们本着越小越好的原则,尽量控制在KB级别的范围内。 - 针对
Hash,List,Set和ZSet类型的 key,理论上包含的元素数量不得超过2^32 - 1个,且每个元素的大小不得超过 512 MB。实际应用中,我们最好将元素的数量控制在 10000 以内,且单个元素的大小不宜过大。 - 定期排查数据库中
bigkey的情况,针对bigkey及时做切分或者清理的处理。
六、避免缓存穿透
缓存穿透是怎么回事呢?我们用下面一张图来说明一下:
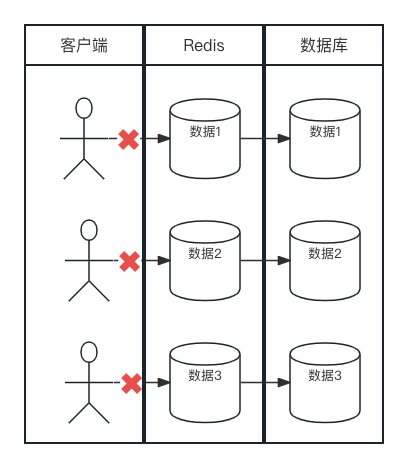
在并发较高的业务系统中,一般逻辑都是当请求来了的时候先查询缓存,如果缓存未命中的话,再去查询数据库。这就存在一个缓存命中率的问题,当大量请求缓存中不存在的数据时,会导致大量的查询请求到数据库,这就会给数据库造成巨大的压力,严重时会导致服务器压力倍增甚至瘫痪。
那应该如何避免缓存穿透这种情况呢?
一般我们在设计缓存的时候需要注意以下情况:
- 增加参数校验逻辑。将非法参数的请求直接在前端进行拦截。
- 缓存空对象(不推荐,造成内存浪费且效率较低)。
- 布隆过滤器(推荐,实现方案请参考 《Redis 实用小技巧—— bitmap 应用之「布隆过滤器」》)。
七、避免缓存雪崩
缓存雪崩的结果和缓存穿透基本是一样的:都是因为缓存命中率直线下降导致请求压力给到数据库,造成服务卡顿甚至瘫痪的情况。不同之处在于,缓存穿透主要是来自外部非法的请求,而缓存雪崩主要是因为热点 key 集中过期,导致大量的请求给到数据库造成的。
那应该如何避免缓存雪崩这种情况呢?
一般我们在设计缓存的时候需要注意以下情况:
- 给 key 设置过期时间的时候,在固定时间的基础上增加一个随机值,避免 key 集中过期。
- 通过定时任务刷新热点 key,定期更新 key 的过期时间,保证热点 key 一直可以命中。
八、避免缓存击穿
缓存击穿是怎么回事呢?我们用下面一张图来说明一下:
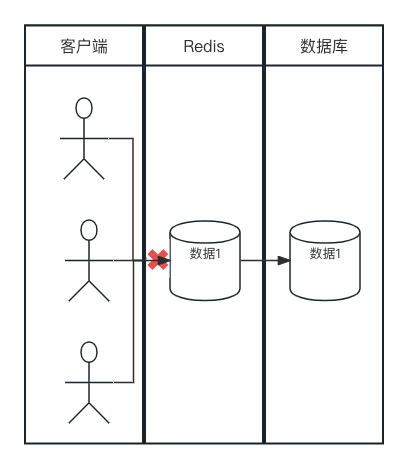
与上述两种场景不同的是,缓存击穿主要是个别热点 key 过期,导致大量指向该 key 的请求无法命中缓存,集中请求到数据库,导致数据库压力激增,造成服务器卡顿甚至瘫痪的情况。
那应该如何避免缓存雪崩这种情况呢?
一般我们在设计缓存的时候需要注意以下情况:
- 查询热点 key 时增加互斥锁的逻辑。这样做会避免压力集中给到数据库的情况,但是对性能会有一定影响,且有可能会产生死锁的情况。
- 使用逻辑过期。性能优于互斥锁的逻辑,但可能会出现数据不一致的情况,会有一定的内存损耗,实现起来也有一定的复杂度。
九、未完,待续……
总结
本篇文章给大家介绍了 Redis 使用过程中的一些规范问题,欢迎大家在评论区留言讨论。同时我也会对本文持续进行整理归纳,以方便大家的查阅。
感谢大家的持续关注~
本作品采用《CC 协议》,转载必须注明作者和本文链接





















 关于 LearnKu
关于 LearnKu




推荐文章: