
使用代理池用py完整的爬取一个网站(尾部有github源码)
0 / 0 / 创建于 5年前 /
 wangchunbo 的个人博客
wangchunbo 的个人博客
在使用代理ip之前,首先要了解几样东西:
一:对返回ip格式的操作,很显然XX代理是给出json格式的数据,可以直接请求后返回json数据进行操作包过提取,删除,增加。当然,在实际使用ip代理的时候最好先在浏览器中请求一次,复制下来新建一个py文件练习对其操作。
二:ip的有效期,现在大部分的ip代理都是有有效期的,(本文的ip处理,是一次性拿5个就扔了.所以没有处理过期,因为我这一个ip只能用几次就封了),当ip失效后你需要将此ip从ip池中删除。当ip不够的时候又要引入新的ip添加到当前的ip池中。要动态维护ip池。
三:python3使用代理ip的方式:下文会介绍,以前我的python3使用代理ip也有格式,你爬取的是http用http,是https用https就行。
四:异常处理,再写爬虫的时候一定要对所有可能产生异常的操作进行try except的异常处理。异常又要注意是否为超时异常,还是ip不可用,过期的异常,还是操作dom树的时候产生的异常。不同的异常要采用不同的策略。(可用状态码,全局变量判断)。
五:注意使用信息和要求:我买的那个蘑菇代理不能请求频率超过5s。还有就要有添加本地ip地址。(可能是基于安全考虑)
六:分析目标网站对ip的需求。你需要设置ip池的最小和请求ip的个数不至于太大或太小,可以预先测试。打个比方你爬的网站同一个时段10个ip更换就不够了。你不至于开100个ip去爬吧,ip过期而没咋么用就是对资源的浪费(当然土豪请随意。)
选择代理
自行找一个,人家会给你api. 你调用即可.
我这里用的是json格式的api

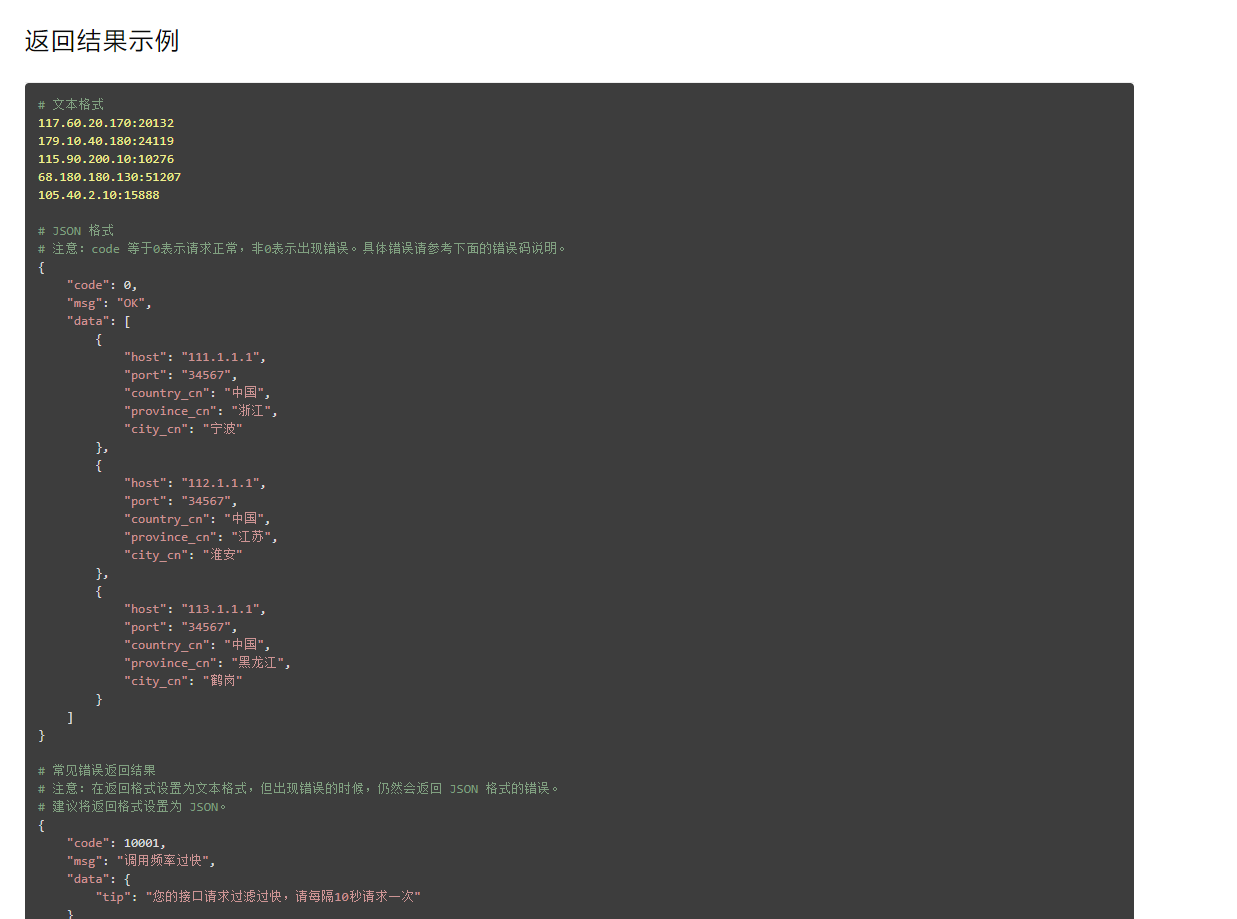
话不多说上简易说明代码
代码
1.配置环境,导入包
IP地址取自国内髙匿代理IP网站:www.xicidaili.com/nn/
仅仅爬取首页IP地址就足够一般使用
from bs4 import BeautifulSoup
import requests
import random
headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'}2.获取网页内容函数
def getHTMLText(url,proxies):
try:
r = requests.get(url,proxies=proxies)
r.raise_for_status()
r.encoding = r.apparent_encoding
except:
return 0
else:
return r.text3.从代理ip网站获取代理ip列表函数,并检测可用性,返回ip列表
def get_ip_list(url):
web_data = requests.get(url,headers)
soup = BeautifulSoup(web_data.text, 'html')
ips = soup.find_all('tr')
ip_list = []
for i in range(1, len(ips)):
ip_info = ips[i]
tds = ip_info.find_all('td')
ip_list.append(tds[1].text + ':' + tds[2].text)
#检测ip可用性,移除不可用ip:(这里其实总会出问题,你移除的ip可能只是暂时不能用,剩下的ip使用一次后可能之后也未必能用)
for ip in ip_list:
try:
proxy_host = "https://" + ip
proxy_temp = {"https": proxy_host}
res = urllib.urlopen(url, proxies=proxy_temp).read()
except Exception as e:
ip_list.remove(ip)
continue
return ip_list4.从ip池中随机获取ip列表
def get_random_ip(ip_list):
proxy_list = []
for ip in ip_list:
proxy_list.append('http://' + ip)
proxy_ip = random.choice(proxy_list)
proxies = {'http': proxy_ip}
return proxies5.调用代理
if __name__ == '__main__':
url = 'http://www.xicidaili.com/nn/'
ip_list = get_ip_list(url)
proxies = get_random_ip(ip_list)
print(proxies)作者的github
gitee.com/bobobobbb/proxy_scraby
本作品采用《CC 协议》,转载必须注明作者和本文链接



 关于 LearnKu
关于 LearnKu




推荐文章: