
InnoDB从内分析之Page(二)
0 / 0 / 创建于 5年前 /
 so_easy 的个人博客
so_easy 的个人博客
前言
还是从这张图开始。
前一分享我已经知道了数据行是如何存储的,可是不知道是如何在数据页中存储的。本章的学习重点就是Page-数据页了。
Page(数据页)
首先,我很想知道Page的数据存储结构: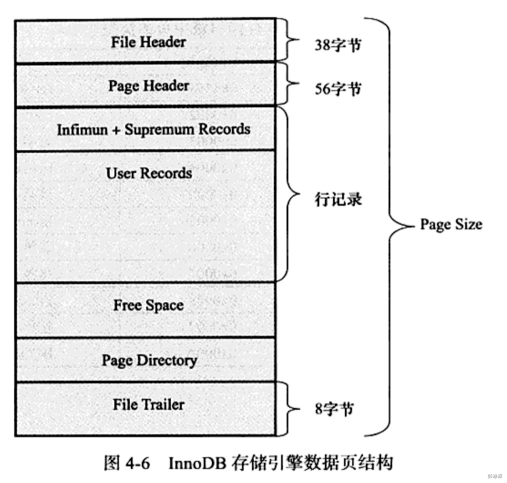
那么怎么理解这数据结构呢?继续从上一章的Row开始。
很明显User Reocrds属性就是用来存储用户的数据行,上一章知道行与行之间是通过单向链表存储。从图中看到除了我们自己用户的行记录之外,还有两条记录:Infimum(最小行)和Supermum(最大行)。这是InnoDB在创建表时自动生成的,所以一个数据表中最少有两条记录。如下图:
这个图的查询方式类似全表扫描,可是效率低下。于是需要改进,怎么改进呢?
(1)类似字典可以有目录查询,然后快速定位到需要查询的某页,在该页中我们在自己定位到要查的文字。
(2)类似图书馆有每一本书的档案查询,可以通过这本书的档案信息知道这本书放在了哪个房间、哪个书架,然后在查询到该书。
如果可以把这些记录编排一个目录,然后查找的时候只需要按这个目录快速定位就好了。这个目录就是槽点,多个槽点连在一起就是Slots(目录槽)。于是得到如下图: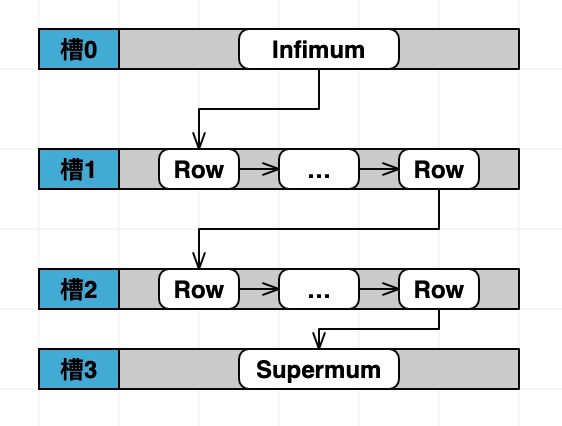
可是新的问题就出现了:
- 槽中应该放多少数据行?
- 槽应该怎么取值?
这里引入InnoDB的规定:
Infimum只能包含一条记录Supermum可以是[1,8]条记录- 其他的则是[4,8]条记录
槽应该怎么取值呢?
- 行分组内最大记录数的相对位置
- 注意是相对位置,不是偏移量。
看下别人画的图,就是好哇!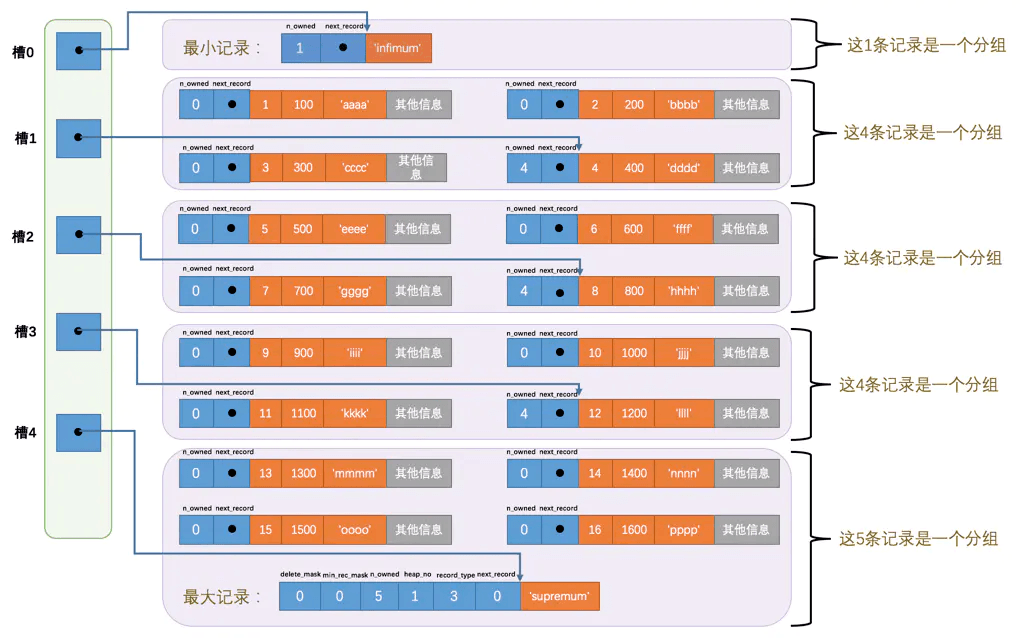
总结以上的几点:
目录槽其实就是页的Page Directory。Page Directory中就是记录的所有槽点的集合。- 一个槽中的行记录数就是
Row.n_owned,记录在行组内的最大行内。
File Header和File Trailer
File Header用来记录页的头信息,如下图: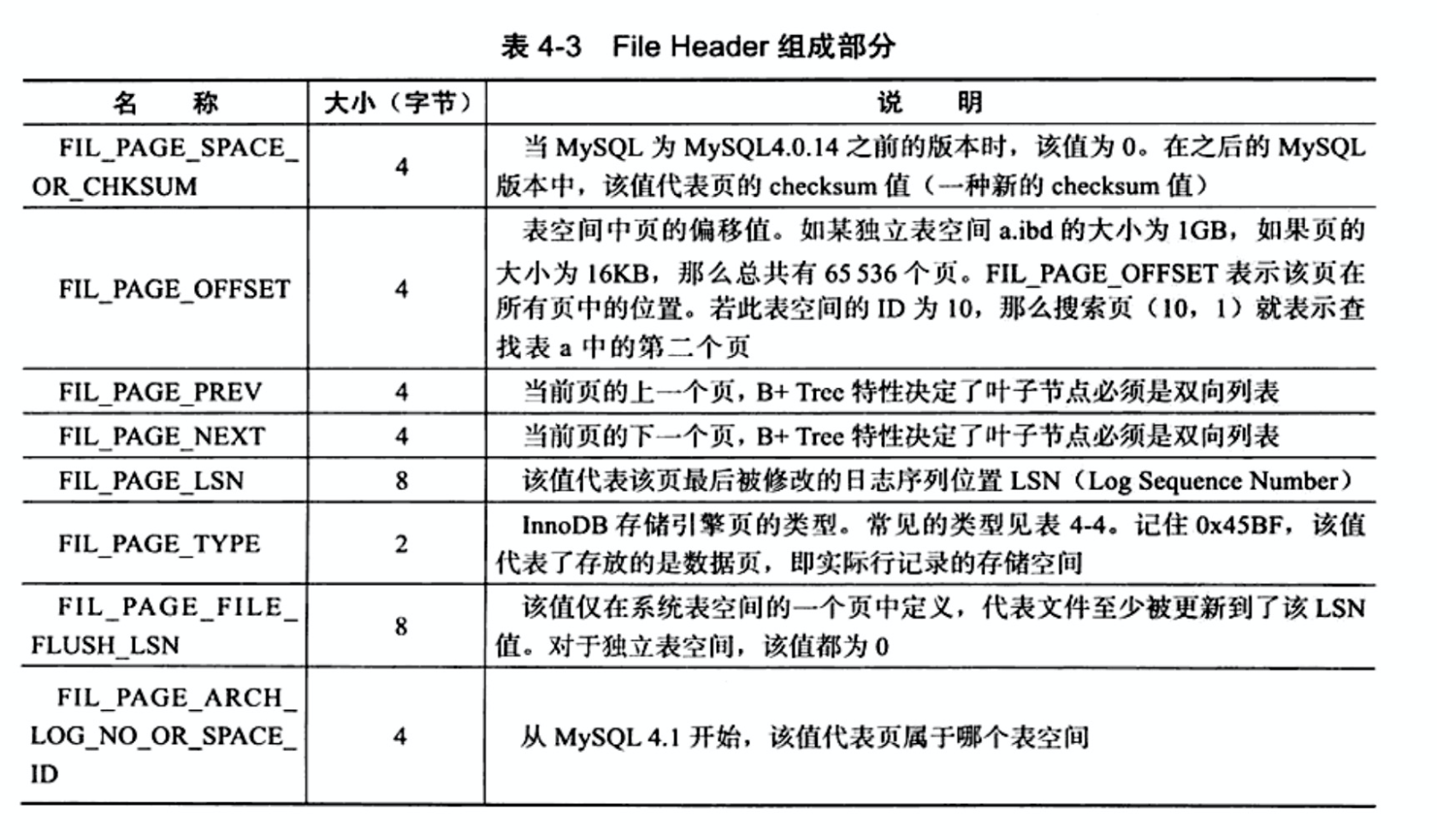
从头中可以归纳的几个功能点:
- 校验和
- 属于哪个表空间及表空间中页的偏移量
- 上下页指针形成页的链表结构
- 页的类型
- 刷脏页
Page Header
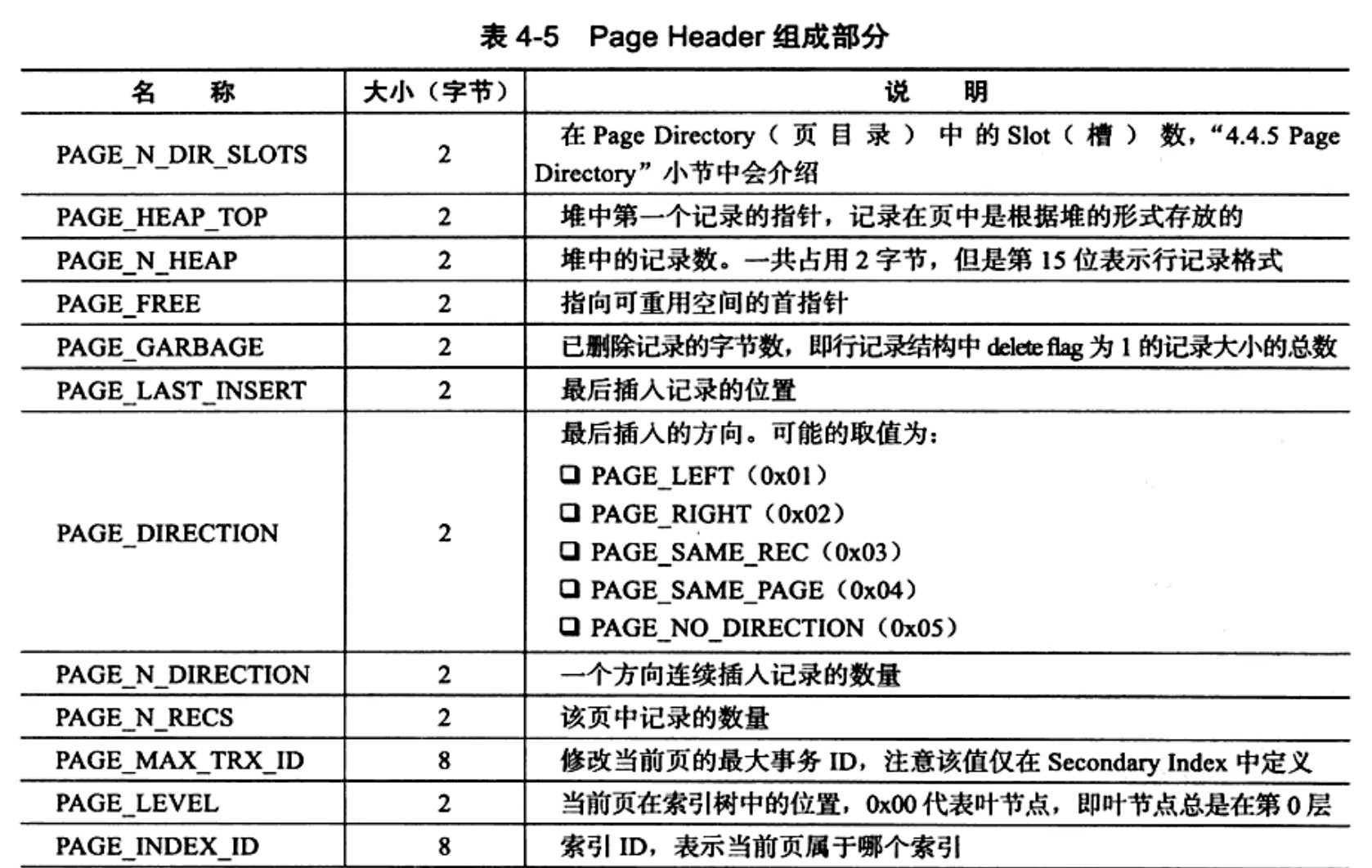

- PAGE_N_RECS(2B):该页中记录的数量。
2B换算成十进制那就是65535
Records和Free Space
数据行分为最大行、最小行和用户行。最大行和最小行是在创建数据表的时候就已有的两条记录,而用户行是通过用户在后续的过程中通过插入数据行添加的数据。如果用户行的数据被删除,则空间会被Free Space回收。
Page Directory
页目录记录的是页相对位置,而不是偏移量。B+树是通过二分查找粗略找到该记录所在的页,把该页载入到内存,然后通过Page Directory再进行二叉查找。因二叉查找速度快再加上在内存中,因此这部分的时间经常被忽略。
数据页结构示例分析
通过以上的概念分析只是有一个大致的了解,现在以具体的示例分析。
(1)创建表并写入数据,分析数据表的二进制文件

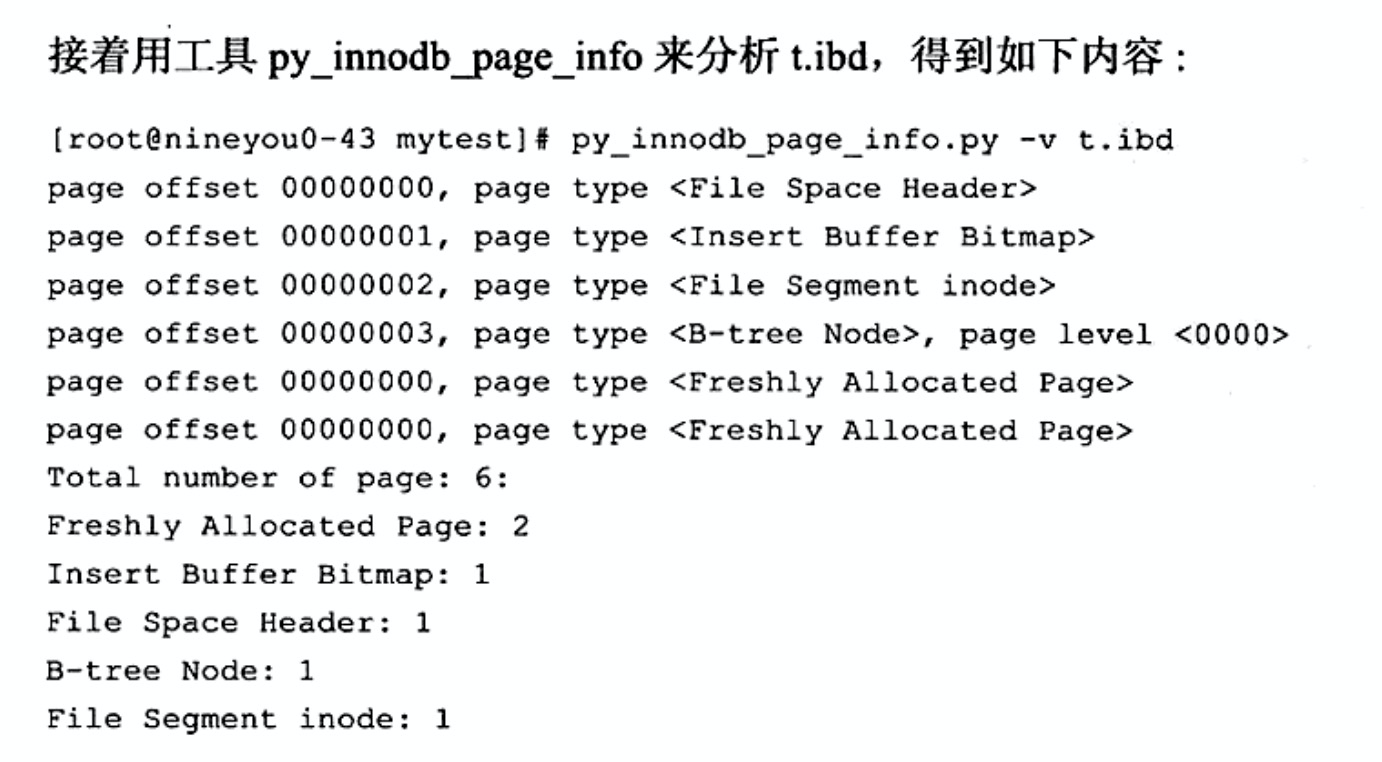
(2)Page offset 03就是数据页。Page level是0,表示的是根节点。一个Page=16KB,以第一页起始位置是:0x0000~0x3fff。第三页的起始就是:0xc000~0ffff。
怎么算呢?
16KB=16*1024KB=16*16*16*4B=0x4000
得到截图如下:
结合Page的组成内存占用情况:
File Header:38B
Page Header:56B
File Trailer:8B
那么已经可以确定这三个结构的位置。
(1)File Header:0xc000+38B-1 = 0xc025。即0xc000~0xc025
(2)Page Header:0xc026+56B-1= 0xc05d。即0xc026~0xc05d
(3)File Trailer:最后8个字节。
分析Page Header
PAGE_N_DIR_SLOTS(2B):0x001a=26。说明有26个槽点,每个槽点占用2B,所以可以从File Trailer往前数52B就是Page Directory的内容了。PAGE_HEAP_TOP(2B):表示堆第一个记录的指针。起始位置为0xc000+0x0dc0=0xcdc0。PAGE_N_HEAP(2B):当行格式为Compact时初始值为0x0802,行格式为Redundant是起始值是2。0x8066-0x0802=0x64,所以有100条记录。PAGE_FREE(2B):指向可重用空间的首指针,值为0x00。因为没有删除,所以为0。PAGE_GARBAGE(2B):已删除记录的字节数,没有删除所以为0x00。PAGE_LAST_INSERT(2B):最后插入记录的位置,值为:0xc000+0x0da5=0xcda5。PAGE_DIRECTION(2B):最后插入方向,值为0x0002。因为一直在插入数据,所以最终是向右插入。PAGE_N_DIRECTION(2B):一个方向连续插入的数量。值为0x0063,即往右连续插入了99条记录。PAGE_N_RECS(2B):该页中记录的数量。值为0x0064,即100条记录。PAGE_LEVEL:值为0x00,代表该页为叶子节点。目前记录行数较少,B+树只有一层。B+树叶子层总是0x00。PAGE_INDEX_ID(8B):索引ID,表示当前页属于哪个索引。
Infimum和Supermum
最小行和最大行紧跟着Page Header。最小行和最大行的行格式和用户行的行格式结构是一样的,只不过它们只有记录头信息和一个字段char(8)。于是可以得到下图:
Infimum:01 00 02 00 1c表示的是记录头信息的5B。69 6e 66 69 6d 75 6d 00即表示字符infimum+00。0x001c是Row.next_record,指向的位置是下一个记录的next_record=0xc062+0x001c=0xc07d。Supermum:同理也可以得到表示最大行的header+字符。
分析Page Directory
从Page Header中已经知道Page Directory一共有26个槽点,每个槽点占2B。得到如下图:
目录槽是按逆序存放的,便于从页尾开始查找。0x0063表示的就是最小行Infimum。0x0070表示的就是最大行Supermum。如果对于之前槽点记录的是
行分组内最大记录数的相对位置没有很直观的理解的话,在这里就可以很清楚的了解到槽点到底记录的是什么了:槽点记录的是行组内最大行数据列的起始位置。从槽点往前数5B就是记录头信息,从记录头信息的n_owned可以得知当前行组内有多少条数据。从槽点往后数就可以得到用户列的数据,结合分析Row的规则,就可以得到具体某个字段的值。
以查找主键a=5为例:
通过二分法查找Page Directory目录槽,定位到0x00e5,实际位置是0xc0e5。读取到这行的记录a=4,不是要查找的记录。通过Row.next_record找到下一行记录则是要找的数据。

页分裂
如果一直按照主键ID自增的方式插入数据,那么当一页写满之后在重新分配新的一页就好。可是如果插入的位置是页中,而不是页尾呢?并且碰巧当前的页已经满了,写不下这条新记录。那么就会发生页分裂。一旦发生页分裂就可能需要耗费大量的时间处理,所以尽量避免这种情况的发送。
- 尽量不要从页中插入数据,尽可能的从页尾插入数据。
- 最好创建主键并且以自增的方式插入。
回头看Row格式的header
B+树结构初步形成
行与行之间的单向链表关系,页与页之间的双向链表关系。这已经很容易得出下图: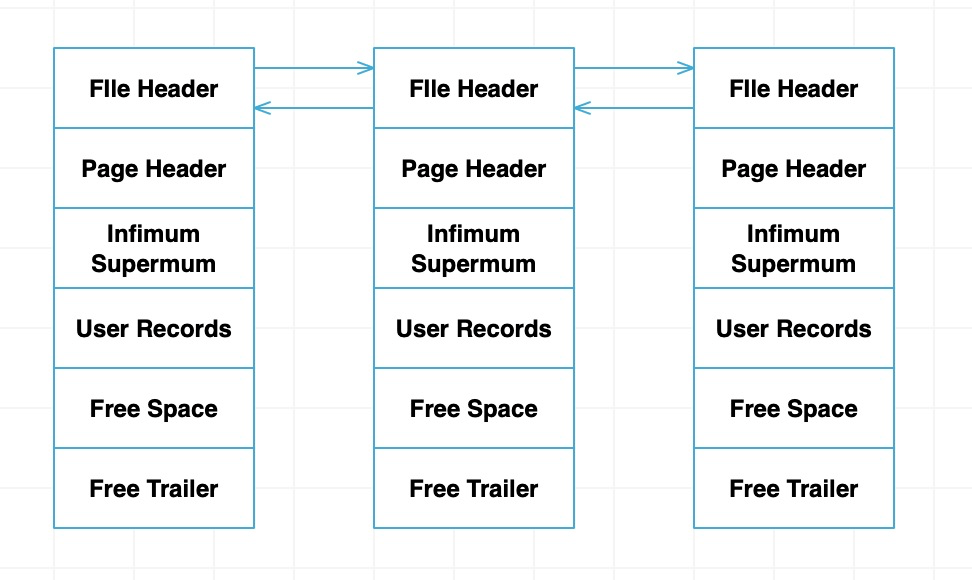
通过页与页和行与行之间的关系,我们的确可以找到要查询的某一条记录。可是页与页之间的查找效率却不高。于是还可以优化–将页号和键值在提及出来又形成一个页。这个页我们称之为非叶子节点。页号和键值则存储在Row格式中。于是稍作整理得到如下图:
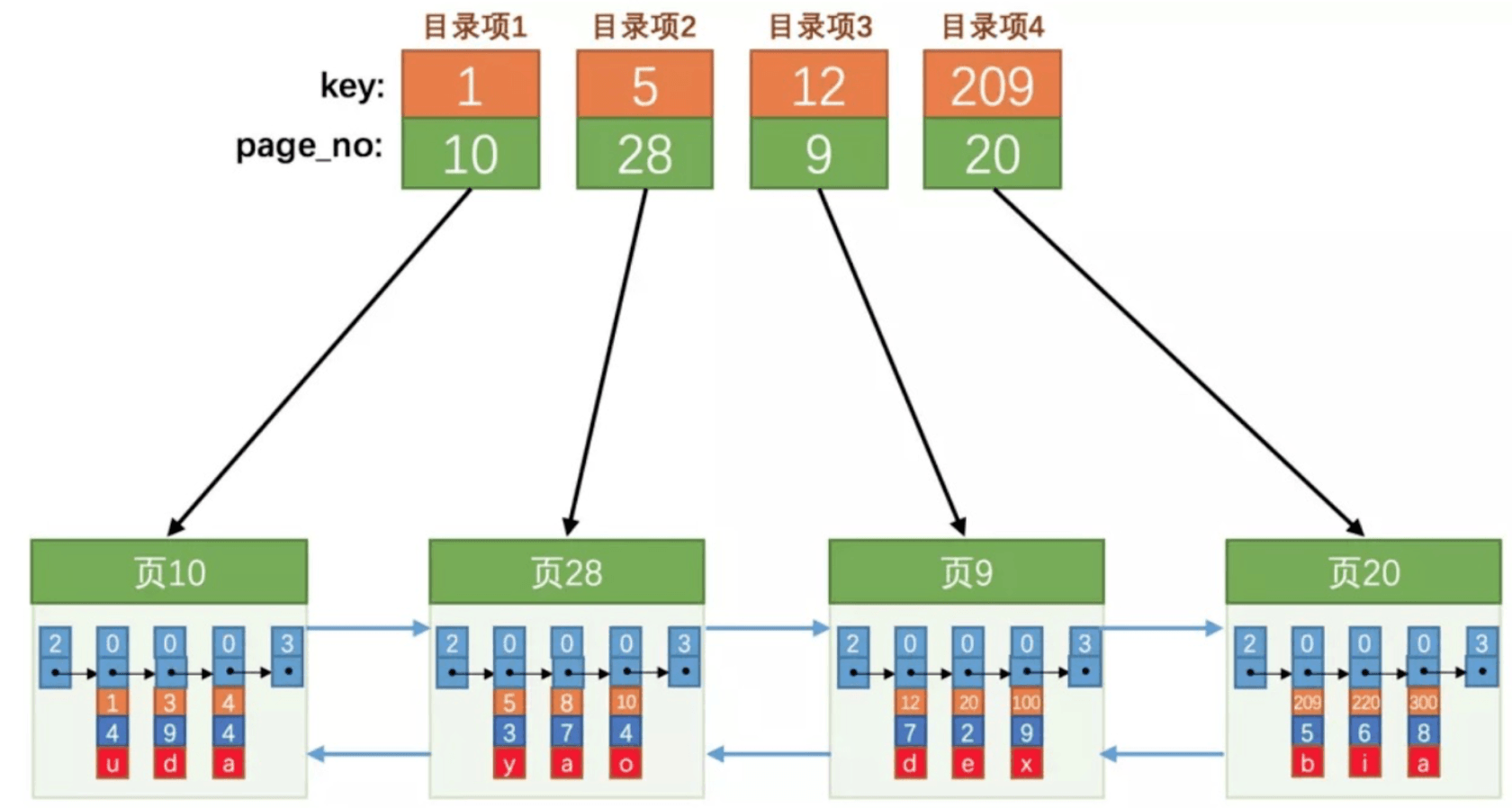
随着记录的增多,最终得到就是如下图: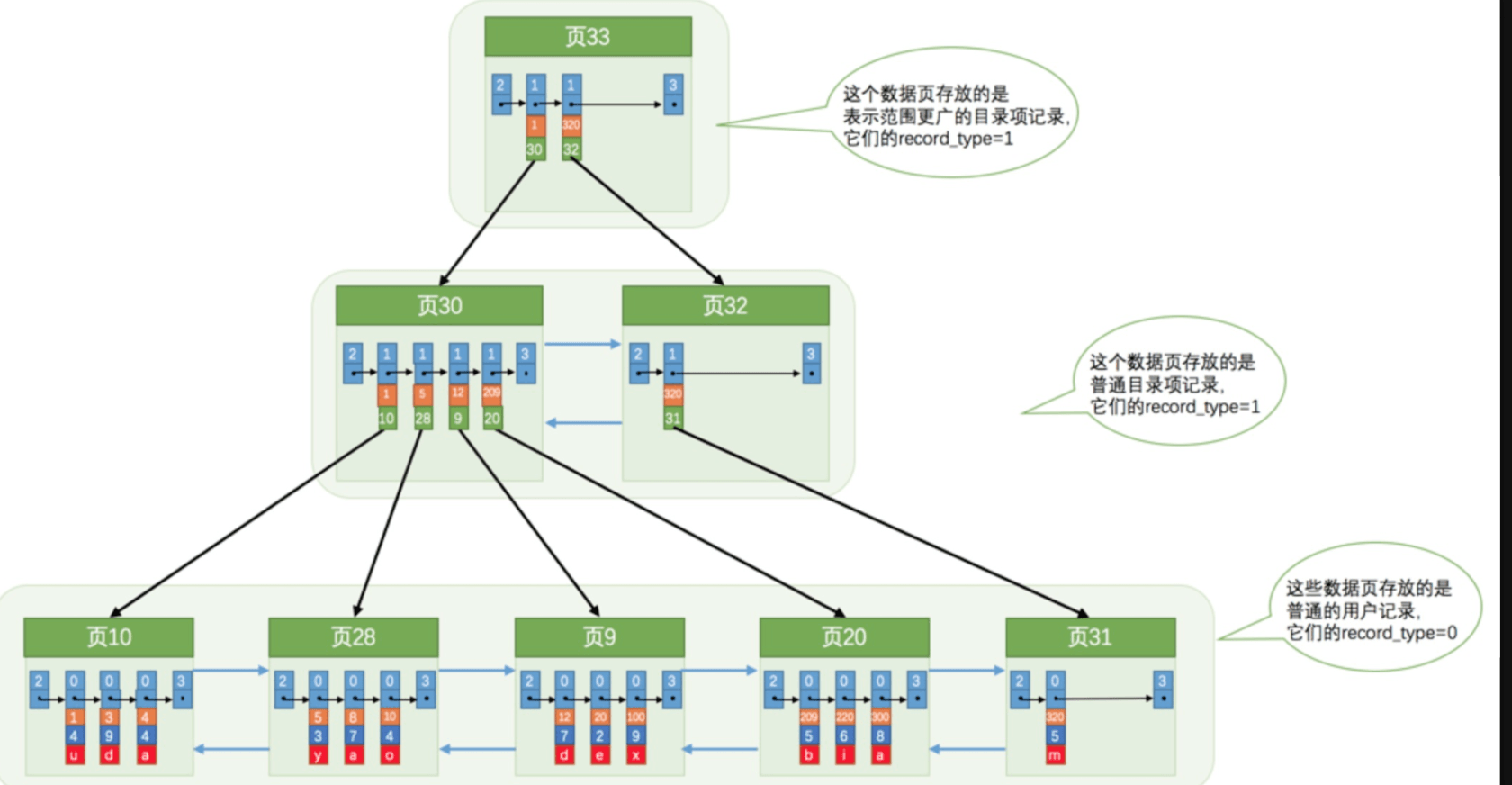
页10:表示的是FIL_PAGE_OFFSET的值。- 橙色的值1、3、4表示的是主键
- 页10下的第一行
2 0 0 0 3表示的是Row.record_type。
更多可参考:juejin.im/post/6844903582550982670
其他知识点
- 叶子节点:包含行数据和索引的
Page,称为叶子节点。 - 非叶子节点:只包含索引字段的
Page,则是非叶子节点。 - 聚簇索引:包含行数据和索引的B+树。定义了主键的数据表会创建以主键为索引的聚簇索引,如果没有定义主键则以唯一键为聚簇索引,否则使用隐藏
RowID为聚簇索引。 - 非聚簇索引:只包含主键和其他索引的B+树。如唯一索引、联合索引、普通索引都是。如果查找的列在非聚簇索引不存在,那么就会涉及到
回表查询。回表查询则会返回聚簇索引按主键去查找列值。
参考
1、mysql存储引擎InnoDB详解,从底层看清InnoDB数据结构
2、MySQL 技术内幕(InnoDB 存储引擎)第二版
本作品采用《CC 协议》,转载必须注明作者和本文链接





 关于 LearnKu
关于 LearnKu




推荐文章: