
InnoDB从内分析之区和段(三)
0 / 0 / 创建于 5年前 /
 so_easy 的个人博客
so_easy 的个人博客
前言
还是先看这个图:
Segment(段)
段的概念:段是概念上区的分类集合。
Extent(区)
区的概念:由连续的64个16KB的Page组成的大小为1M的空间。区是实际的1M物理空间。当碎片区用完之后,就会申请1M的连续物理空间。
Fragment(碎片区)
新建的表空间并不会直接申请1M的区存储,实际只有96KB,即6页。从下文的结构分析知道Fragment由INODE页管理,如果32个Fragment都用完之后才会申请完整的1MExtent空间。
表空间的结构图
不论是系统表空间还是独立表空间,都可以看成是由若干个区组成的,每256个区被划分成一组。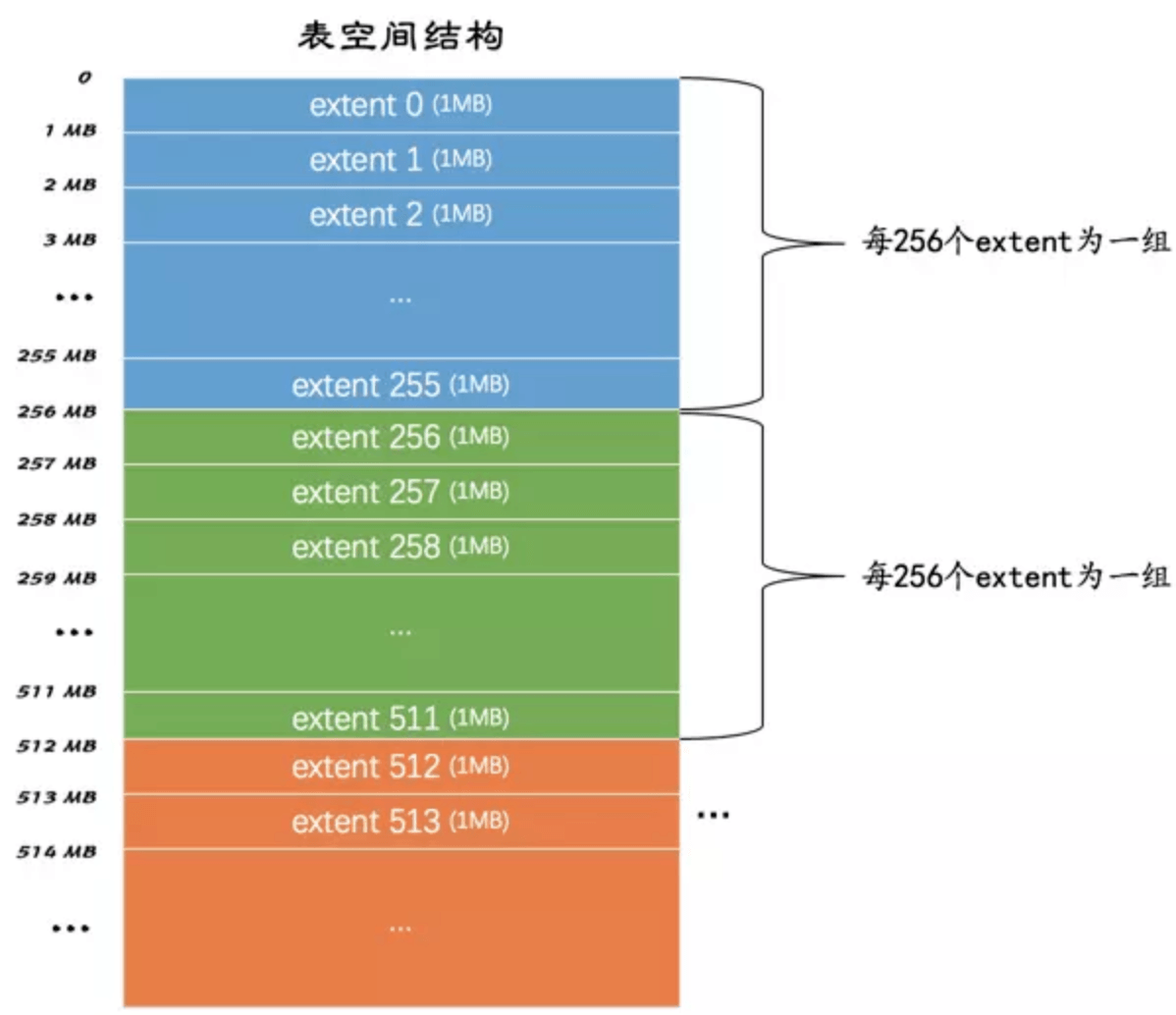
其中第一个组的extent0的前三个页面数据结构固定是:
- FSP_HDR:表空间头
- IBUF_BITMAP:
- INODE:段的数据结构其他的extent的前两个页面是固定的:
- XDES:这组区的描述
- IBUF_BITMAP: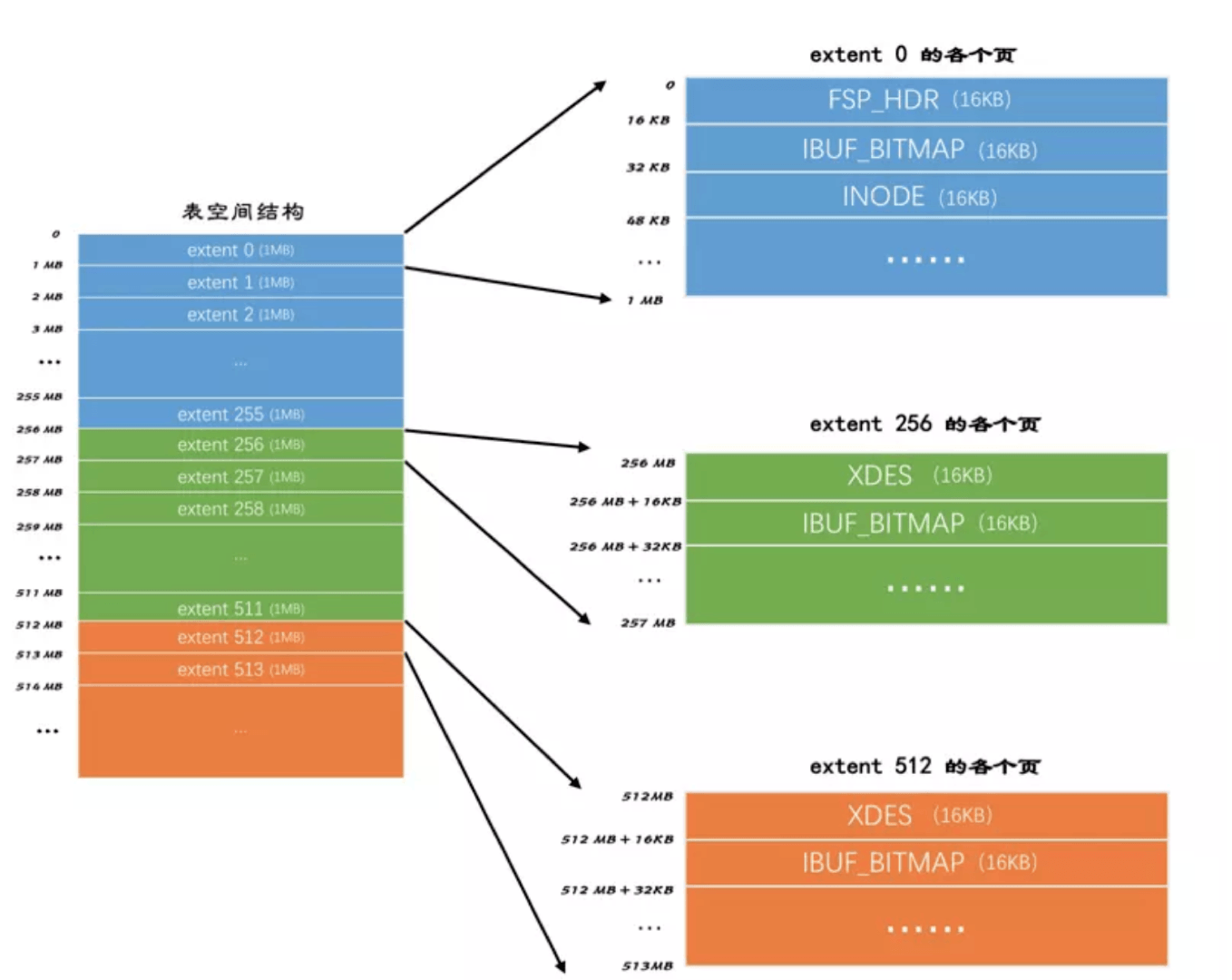
Extent除了这几个特殊的Page之外,其他就是前文讲过的Page–用来存储数据的页。之所以这里有这几个特殊的页是为了对这个表空间能够进行有效的管理。而如何管理则是下文的目的了。通过学习这些数据的存储,可以了解到InnoDB的存储结构以及对今后如何优化InnoDB查询有更深的了解。
FSP_HDR的结构示意图
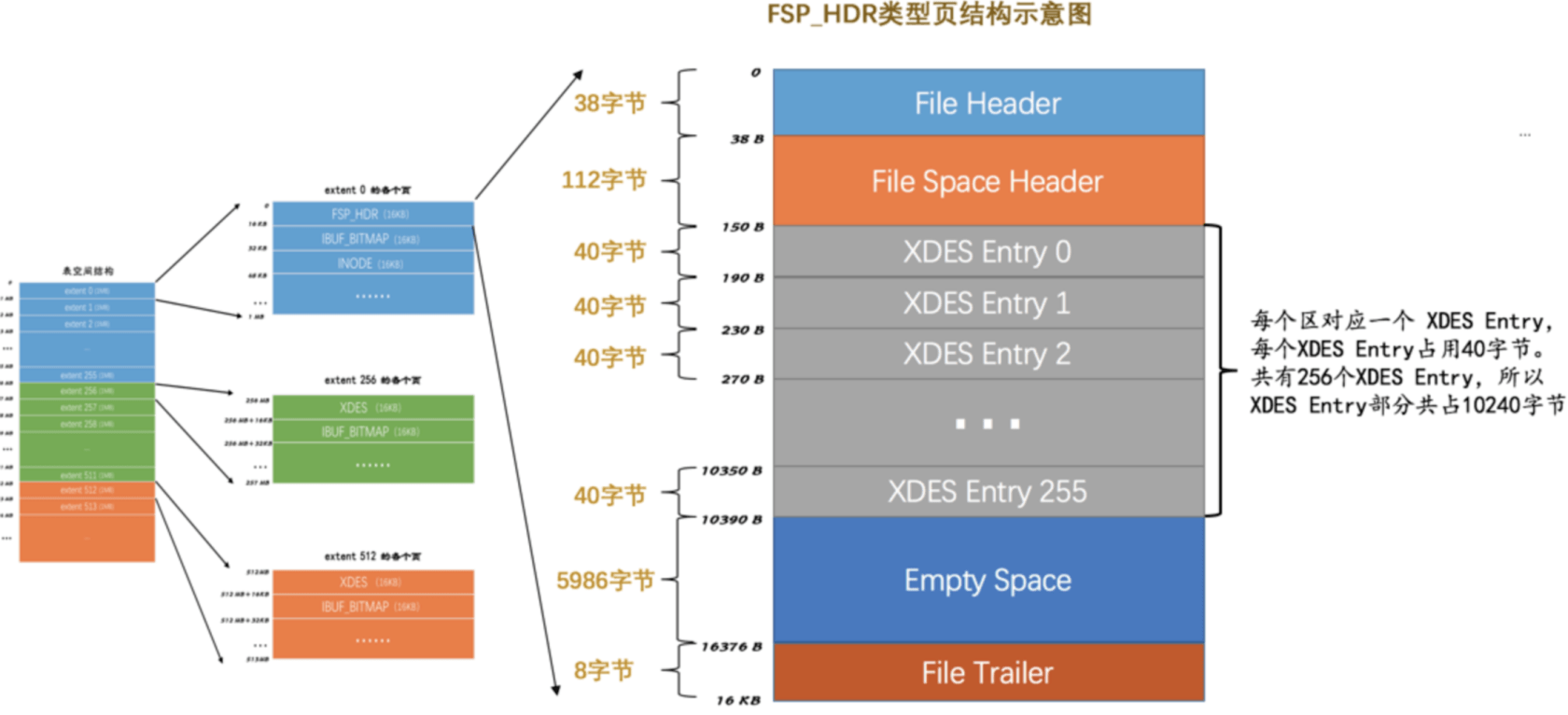
- `FILE Header`:文件头
- `File Space Header`:表空间的头信息
- `XDES Entry`:区描述实例。256个区别划分成了一组,组内的每一个区都对应一个`XDES Entry`。
- `Empty Space`:空闲区域
- `File Traile`:文件尾部FIle Space Header结构示意图

下文的
List Base Node占用16B,指向的Extent的首节点和尾节点。具体的意义如下图:

- `Space ID`:表空间ID
- `Not Used`:保留字段,未使用
- `Size`:当前表空间总的`Page`个数
- `FREE Limit`:当前尚未初始化的最小`Page No`。从该`Page`往后的都尚未加入到`表空间`的`FREE LIST`上
- `Space Flags`:
- `FRAG_N_USED`:`FREE_FRAG`链表上已被使用的`Page`数,用于快速计算该链表可用空闲`Page`数
- `List Base Node For FREE List`(简写`FSP_FREE`):当一个`Extent`中的所有`Page`都未被使用,放到该链表上,用于随后的分配。
- `List Base Node For FREE_FRAG List`(简写`FSP_FREE_FRAG`):`FREE_FRAG`链表的基点,通常这样的`Extent`中的`Page`可能归属于不同的`segment`,用于`segment frag array page`的分配
- `List Base Node For FULL_FRAG List`(简写`FSP_FULL_FRAG`):`Extent`中所有的`Page`都被使用时,放到该链表上。当有`Page`从该`Extent`释放时,则移回`FREE_FRAG`链表
- `Next Unused Segment ID`:当前文件中最大的段ID+1,用于段分配时的seg id计数器
- `List Base Node for SEG_INODES_FULL`:已被完全用满的`Inode page`链表
- `List Base Node for SEG_INODES_FREE`:至少存在一个空闲的`Inode Entry`的`Inode Page`被放到该链表INDOE结构示意图
INODE
数据段:单独的区的集合存放叶子节点
索引段:单独的区的集合存放非叶子节点
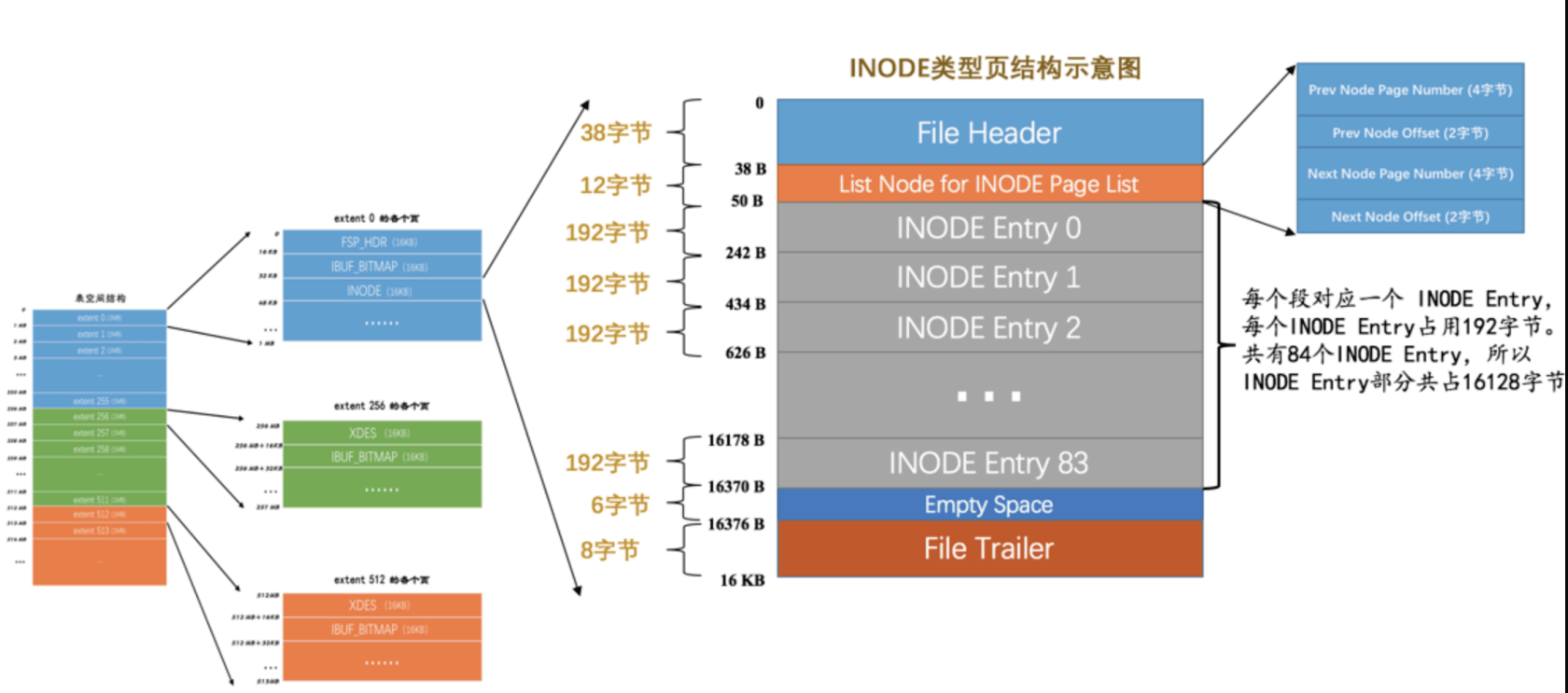
- `FILE Header`:文件头
- `List Node for Node Page List` :`INODE`双向链表
Prev Node Page Number
Prev Node Offsct
Next Node Page Number
Next Node Offset
- INODE Entry:段实体
- Empty Space:空闲空间
- File Tailer:文件尾INODE Entry结构示意图
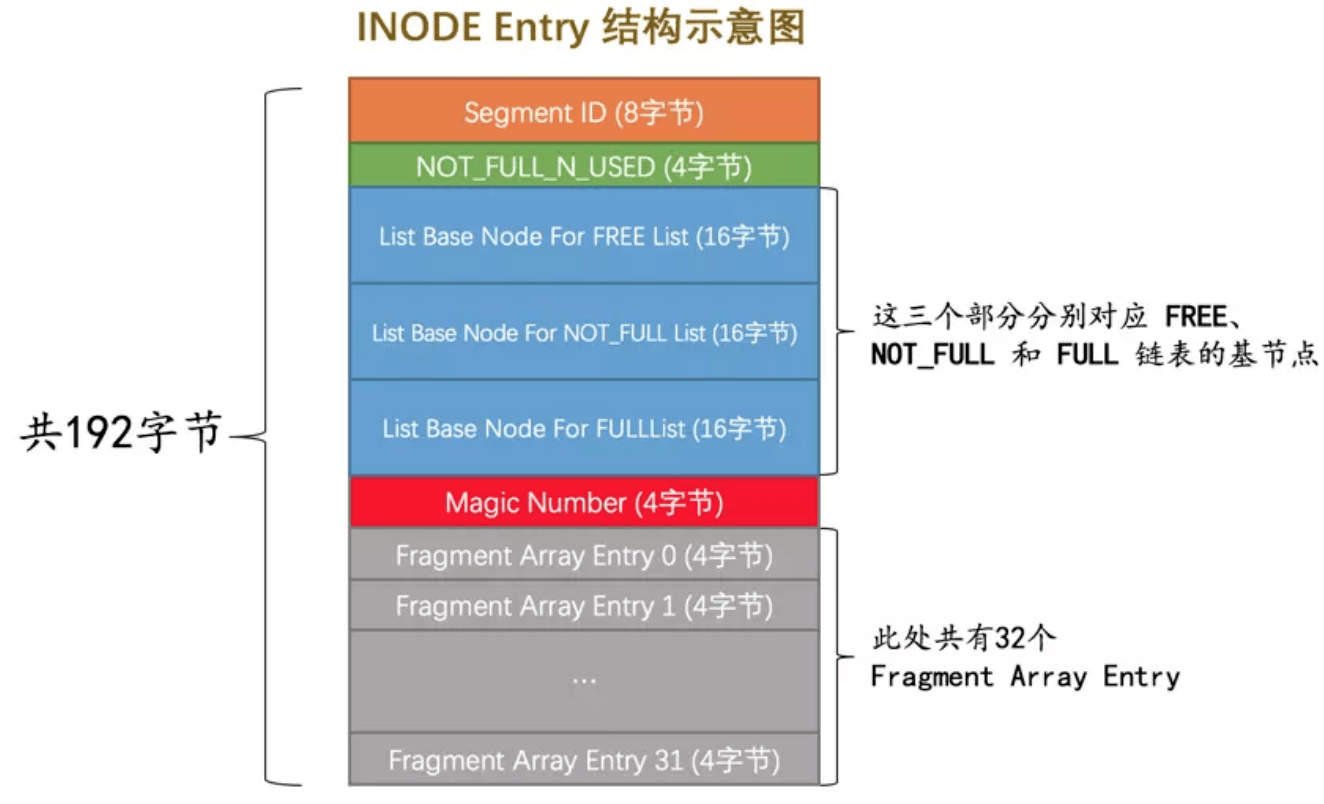
- `Segment ID`:段ID
- `NOT_FULL_N_USED`:在`NOT_FULL`链表中已经使用了多少个页面
- `List Base Node For FREE List`:完全没有被使用并分配给该`Segment`的`Extent`链表。
- `List Base Node For NOT_FULL List`:至少有一个`Page`分配给当前`Segment`的`Extent`链表,全部用完时,转移到`FSEG_FULL`,全部释放时,则归还`FSP_FREE`。
- `List Base Node For FULL List`:分配给当前`Segment`且`Page`完全使用完的`Extent`链表。
- `Magic Number`:标记这个`INODE Entry`是否已经被初始化,初始化的意思就是把各个字段的值都填进去了。
- `Fragment Array Entry`:指向某个`Page`的指针,记录的是相对位置。XDES结构示意图
XDES Entry(Extent Descriptor Entry)是对区的描述实体,用来记录区的信息。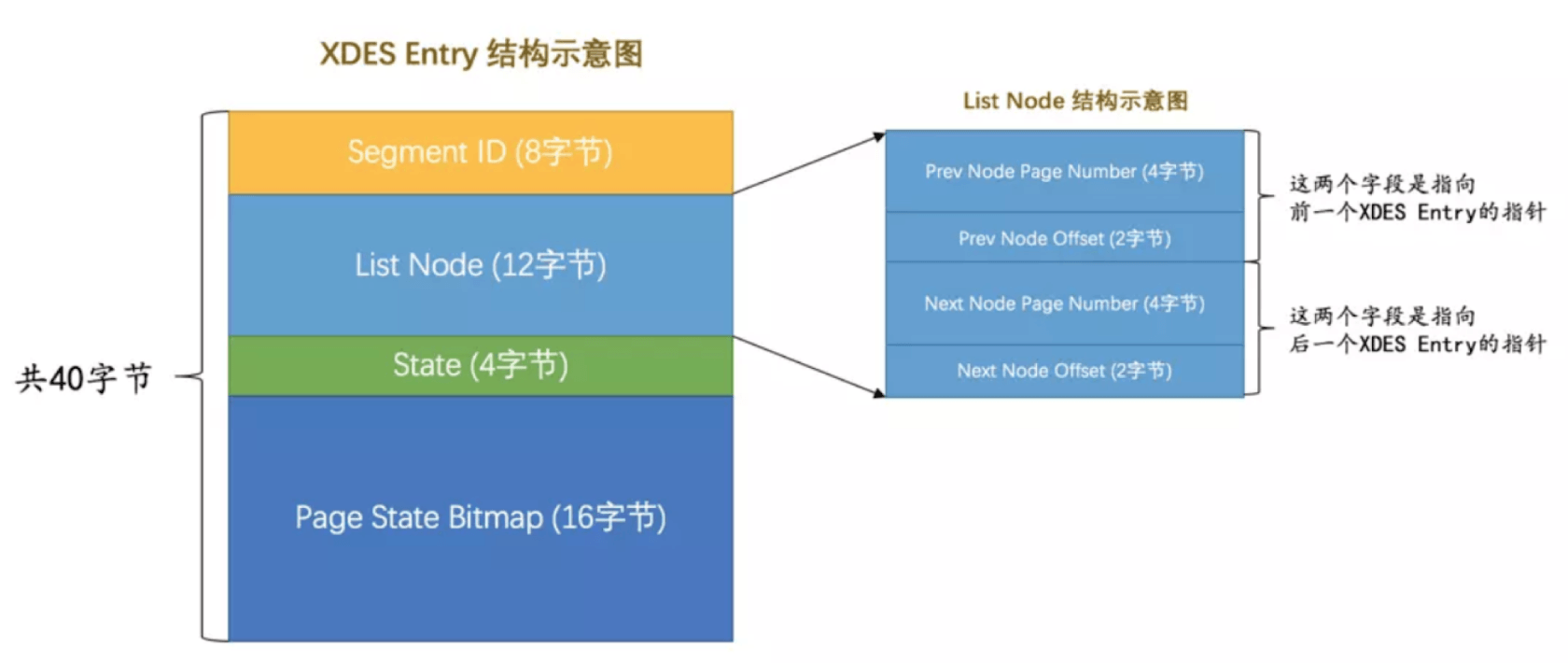
- SegmentID:段ID。每个表空间分为`叶子节点段`和`非叶子结点段`,也可称为`数据段`和`索引段`。每个段都有自己的ID,这个值通过`INODE`结构存储。
- List Node:指向前后`XDES Entry`的指针。
`Prev Node Page Number`:前一个节点的页号
`Prev Node Offset`:前一个节点的相对位置
`Next Node Page Number`:下一个节点的页号
`Next Node Offset`:下一个节点的相对位置
- State:区的状态。
FREE:直属于表空间-空闲区。
FREE_FRAG:直属于表空间-有剩余空间的碎片区。
FULL_FRAG:直属于表空间-没有剩余空间的碎片区。
FSEG:附属于某个段的区
- Page State Bitmap:1M的连续空间分配给了64个`Page`。16B=128bit,每2个bit表示1个`Page`的状态。`00`表示空闲,`10`表示已写。数据结构分析
从每个结构来看似乎还是很清晰的,就犹如表空间的数据结构图把自己的每一个部分的细微结构都展现了出来。但是这些结构是如何组合起来工作的,却一下子摸不着头脑。接下来就慢慢的分析这些数据结构之间的关系。
首先:聊一聊碎片区
前面提到过一个表刚被建立的时候只有96KB,也即6个页面。其中这6个页面是哪些页面的组成呢?举个例子: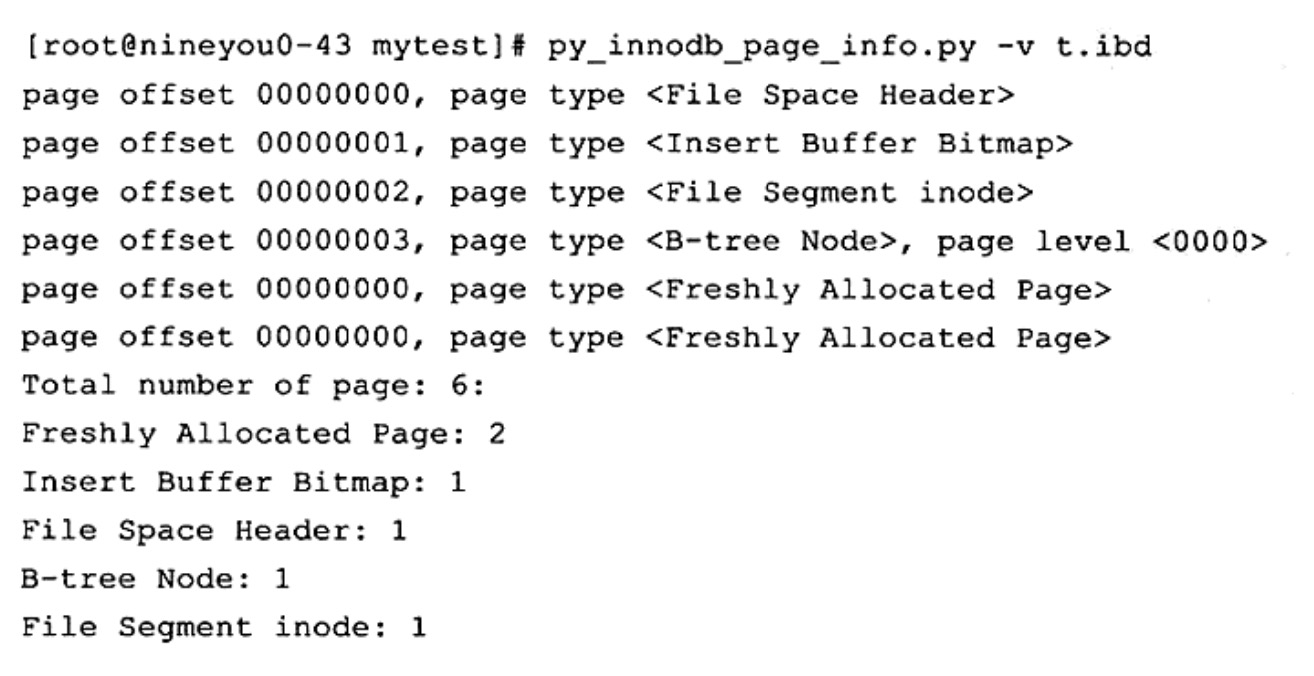
File Space Header:表空间头Insert Buffer Bitmap:表空间的IBUF_BITMAPB-tree Node:这是一个Page,表示的是叶子节点File Segment inode:表空间的INODE页面。Freshly Allocated Page:剩下2个Page还未被使用。
(1)刚创建的表不会分配完整的Extent,表中的数据开始都是存储在Fragment碎片区。表空间除了固定的3个Page之外,剩下的就是3个空闲的Page。
(2)这3个空闲的Page一开始建表的时候是从File Space Header.FSP_FREE_FRAG链表指向的碎片区(还有空闲Page的Extent)分配的。
(3)如果3个空闲Page被写满,这些页面的页号会被依次写在INODE.INode Entry.Fragment Array Entry:0-2,并且向FSP_FREE_FRAG指向的的碎片区申请新的Page,这个新的Page的页号被写在Fragment Array Entry 3。—如此下去就会把INODE.INode Entry的32个Fragment用完,接下来就是分配完整的Extent。如果碎片区的空闲页面被分配完毕,则这个碎片区就会被链接到FSP_FULL_FRAG。反之如果FSP_FULL_FRAG有空闲的页面则又会被链接回FSP_FREE_FRAG。
(4)FSP_FREE_FRAG的碎片区最开始是从FSP_FREE中申请的。
(5)碎片区用完之后,开始申请完整的1MExtent。这个Extent也是从FSP_FREE申请。每一个Extent都对应了一个FSP_HDR.XDES Entry。256个Extent被视为一组,每个Extent都有唯一对应的XDES Entry。所以通过FSP_HDR就可以管理这一组的Extent。
再而:聊一聊段
一个索引有两个段:数据段和索引段。数据段指的就是单独存放叶子节点的区链表,而索引段指的就是单独存放非叶子结点的区链表。该如何去理解呢?下面通过实践分析某个数据表的二进制存储文件。
第一步:通过py_innodb_page_info.py检查ibd
bash-3.2# python py_innodb_page_info.py ../lottery_match/league_map.ibd -v
page offset 00000000, page type <File Space Header>
page offset 00000001, page type <Insert Buffer Bitmap>
page offset 00000002, page type <File Segment inode>
page offset 00000003, page type <B-tree Node>, page level <0001>
page offset 00000004, page type <B-tree Node>, page level <0000>
page offset 00000005, page type <B-tree Node>, page level <0000>
page offset 00000006, page type <B-tree Node>, page level <0000>
page offset 00000007, page type <B-tree Node>, page level <0000>
page offset 00000000, page type <Freshly Allocated Page>
Total number of page: 9:
Freshly Allocated Page: 1
Insert Buffer Bitmap: 1
File Space Header: 1
B-tree Node: 5
File Segment inode: 1如上存在叶子节点和非叶子节点。叶子节点在page offset 3,非叶子节点在在page offset 4、5、6、7。File Segment inode在page offset 2。这次的重点分析对象是INDOE的INode Entry,求证一个索引分两段的存储关系是如何存储的。
第二步:开始分析page offset 2-INDOE
见INODE二进制分析
求证得到的结论就是:
- 一个索引分两段,最开始的时候就以
INode Entry结构保存了段的实例。 - 这个例子的数据表是有两个索引,所以一共用了4个
INode Entry。但是INode Entry又是如何管理的Extent呢?
本作品采用《CC 协议》,转载必须注明作者和本文链接




 关于 LearnKu
关于 LearnKu




推荐文章: